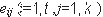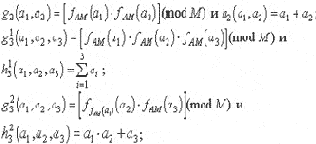Анализ программ на этапе их эксплуатации
В данном разделе будут рассмотрены методы поиска и нейтрализации РПС с помощью дизассемблеров и отладчиков на этапе эксплуатации программ. То есть задача защиты в отличии задач защиты в предыдущих раз-делах здесь решается "с точностью до наоборот".
Основная схема анализа исполняемого кода, в данном случае, может выглядеть следующим образом :
выделение чистого кода, то есть удаление кода, отвечающего за защиту этой программы от несанкционированного запуска, копирования и т.п. и преобразования остального кода в стандартный правильно интерпретируемый дизассемблером;
лексический анализ;
дизассемблирование;
семантический анализ;
перевод в форму, удобную для следующего этапа (в том числе и перевод на язык высокого уровня);
синтаксический анализ.
После снятия защиты осуществляется поиск сигнатур (лексем) РПС. Примеры сигнатур РПС приведены в работе . Окончание этапа дизассемблирования предшествует синтаксическому анализу, то есть процессу отождествлению лексем, найденных во входной цепочке, одной из языковых конструкций, задаваемых грамматикой языка, то есть синтаксический анализ исполняемого кода программ состоит в отождествлении сигнатур, найденных на этапе лексического анализа, одному из видов РПС.
При синтаксическом анализе могут встретиться следующие трудности:
могут быть не распознаны некоторые лексемы. Это следует из то-го, что макроассемблерные конструкции могут быть представлены бесконечным числом регулярных ассемблерных выражений;
порядок следования лексем может быть известен с некоторой вероятностью или вообще не известен;
грамматика языка может пополняться, так как могут возникать новые типы РПС или механизмы их работы.
Таким образом, окончательное заключение об отсутствии или наличии РПС можно дать только на этапе семантического анализа, а задачу этого этапа можно конкретизировать как свертку терминальных символов в нетерминалы как можно более высокого уровня там, где входная цепочка задана строго.
Так как семантический анализ удобнее вести на языке высокого уровня далее проводится этап перевода ассемблерного текста в текст на языке более высокого уровня, например, на специализированном языке макроассемблера, который нацелен на выделение макроконструкций, используемых в РПС.
На этапе семантического анализа дается окончательный ответ на вопрос о том, содержит ли входной исполняемый код РПС, и если да, то какого типа. При этом используется вся информация, полученная на всех предыдущих этапах. Кроме того, необходимо учитывать, что эта информа-ция может считаться правильной лишь с некоторой вероятностью, причем не исключены вообще ложные факты, или умозаключения исследователей. В целом, задача семантического анализа является сложной и ресурсоемкой и скорее не может быть полностью автоматизирована.
Человеческий фактор
Преднамеренные и непреднамеренные нарушения безопасности программного обеспечения безопасности компьютерных систем большинство отечественных и зарубежных специалистов связывают с деятельностью человека. При этом технические сбои аппаратных средств КС, ошибки программного обеспечения и т.п. часто рассматриваются лишь как второстепенные факторы, связанные с проявлением угроз безопасности.
С некоторой степенью условности злоумышленников в данном случае можно разделить на два основных класса:
злоумышленники-любители (будем называть их хакерами);
злоумышленники-профессионалы.
Хакеры - это люди, увлеченные компьютерной и телекоммуникационной техникой, имеющие хорошие навыки в программировании и довольно любознательные. Их деятельность в большинстве случаев не приносит особого вреда компьютерным системам. Ко второму классу можно отнести отечественные, зарубежные и международные криминальные сообщества и группы, а также правительственные организации и службы, которые осуществляют свою деятельность в рамках концепции "информационной войны". К этому же классу можно отнести и сотрудников самих предприятий и фирм, ведущих разработку или эксплуатацию программного обеспечения.
Хакеры и группы хакеров
Хакеры часто образуют небольшие группы. Иногда эти группы периодически собираются, а в больших городах хакеры и группы хакеров встречаются регулярно. Но основная форма взаимодействия осуществляется через Интернет, а ранее - через электронные доски BBS. Как правило, каждая группа хакеров имеет свой определенный (часто критический) взгляд на другие группы. Хакеры часто прячут свои изобретения от хакеров других групп и даже от соперников в своей группе.
Существуют несколько типов хакеров. Это хакеры, которые:
стремятся проникнуть во множество различных компьютерных систем (маловероятно, что такой хакер объявится снова после успешного проникновения в систему);
получают удовольствие, оставляя явный след того, что он проник в систему;
желают воспользоваться оборудованием, к которому ему запрещен доступ;
охотятся за конфиденциальной информацией;
собираются модифицировать определенный элемент данных, например баланс банка, криминальную запись или экзаменационные оценки;
пытаются нанести ущерб "вскрытой" (обезоруженной) системе.
Группы хакеров, с некоторой степенью условности, можно разделить на следующие:
группы хакеров, которые получают удовольствие от вторжения и исследования больших ЭВМ, а также ЭВМ, которые используются в различных государственных учреждениях;
группы хакеров, которые специализируются на телефонной системе;
группы хакеров - коллекционеров кодов - это хакеры, запускающие перехватчики кода, которые ищут карту вызовов (calling card) и номера PBX (private branch exchange - частная телефонная станция с выходом в общую сеть);
группы хакеров, которые специализируются на вычислениях. Они используют компьютеры для кражи денег, вычисления номеров кредитных карточек и другой ценной информации, а затем продают свои услуги и методы другим, включая членов организованной преступности. Эти хакеры могут скупать у коллекционеров кодов номера PBX и продавать их за 200-500$, и подобно другим видам информации неоднократно. Архивы кредитных бюро, информационные срезы баз данных уголовного архива ФБР и баз данных других государственных учреждений также представляют для них большой интерес. Хакеры в этих группах, как правило, не находят взаимопонимания с другими хакерами;
группы хакеров, которые специализируются на сборе и торговле пиратским программным обеспечением.
Типовой потрет хакера
Ниже приводится два обобщенных портрета хакера, один составлен по данным работы и характеризует скорее зарубежных хакеров-любителей, в то время как второй - это обобщенный портрет отечественного злонамеренного хакера, составленный Экспертно-криминалистическим центром МВД России .
В первом случае отмечается, что многие хакеры обладают следующими особенностями :
мужчина: большинство хакеров - мужчины, как и большинство программистов;
молодой: большинству хакеров от 14 до 21 года, и они учатся в институте или колледже.
Когда хакеры выходят в деловой мир в качестве программистов, их программные проекты источают большую часть их излишней энергии, и корпоративная обстановка начинает менять их жизненную позицию. Возраст компьютерных преступников показан на рис.4.1 ;
сообразительный: хакеры часто имеют коэффициент интеллекта выше среднего. Не смотря на свой своеобразный талант, большинство из них в школе или колледже не были хорошими учениками. Например, большинство программистов пишут плохую документацию и плохо владеют языком;
концентрирован на понимании, предсказании и управлении: эти три условия составляет основу компетенции, мастерства и самооценки и стремительные технологические сдвиги и рост разнообразного аппаратного и программного обеспечения всегда будут вызовом для хакеров;

Рис. 4.1. Возрастное распределение обнаруженных компьютерных преступников
увлечен компьютерами: для многих пользователей компьютер - это необходимый рабочий инструмент. Для хакера же - это "удивительная игрушка" и объект интенсивного исследования и понимания;
отсутствие преступных намерений: по данным лишь в 10% рассмотренных случаев компьютерной преступности нарушения, совершаемые хакерами, привели к разрушению данных компьютерных систем. В связи с этим можно предположить, что менее 1% всех хакеров являются злоумышленниками.
Обобщенный портрет отечественного хакера выглядит следующим образом: это мужчина в возрасте от 15 до 45 лет, либо имеющий многолетний опыт работы на компьютере, либо почти не обладающий таким опытом; в прошлом к уголовной ответственности не привлекался; является яркой, мыслящей личностью, способной принимать ответственные решения; хороший, добросовестный работник; по характеру нетерпимый к насмешкам и к потере своего социального статуса в рамках окружающей его группы людей; любит уединенную работу; приходит на службу первым и уходит последним; часто задерживается на работе после окончании рабочего дня и очень редко использует отпуска и отгулы.
Криминальные сообщества и группы, сценарий взлома компьютерной системы
В связи со стремительным ростом информационных технологий и разнообразных компьютерных и телекоммуникационных средств и систем, наблюдается экспоненциальный рост как количества компьютерных атак, так и объем нанесенного от них ущерба (см. табл.4.3). Это показали исследования, проведенные в 90-х гг. в США . Анализ показывает, что такая тенденция постоянно сохраняется.
За последнее время в нашей стране не отмечено ни одного компьютерного преступления, которое было бы совершено одиночкой . Более того, известны случаи, когда организованными преступными группировками нанимались бригады из десятков хакеров. Им предоставлялись отдельные охраняемые помещения, оборудованные самыми передовыми компьютерными средствами и системами для проникновения в компьютерные сети коммерческих банков (см. табл.4.4).
Специалисты правоохранительных органов России неоднократно отмечали тот факт, что большинство компьютерных преступлений в банковской сфере совершается при непосредственном участии самих служащих коммерческих банков . Результаты исследований, проведенных с привлечением банковского персонала, показывают, что доля таких преступлений приближается к отметке 70%. При осуществлении попытки хищения 2 млрд. рублей из филиала одного крупного коммерческого банка преступники оформили проводку фиктивного платежа с помощью удаленного доступа к компьютеру через модем, введя пароль и идентификационные данные, которые им передали сообщники из состава персонала этого филиала. Далее эти деньги были переведены в соседний банк, где преступники попытались снять их со счета, оформив поддельное платежное поручение.
По данным Экспертно-криминалистического центра МВД России принципиальный сценарий взлома защитных механизмов банковской компьютерной системы представляется следующим. Компьютерные злоумышленники-профессионалы обычно работают только после тщательной предварительной подготовки. Они снимают квартиру на подставное лицо в доме, в котором не проживают сотрудники ФСБ, МВД или МГТС. Подкупают сотрудников банка, знакомых с деталями электронных платежей и паролями, и работников телефонной станции, чтобы обезопасить себя на случай поступления запроса от службы безопасности банка.
Нанимают охрану из бывших сотрудников МВД. Чаще всего взлом банковской компьютерной системы осуществляется рано утром, когда дежурный службы безопасности теряет свою бдительность, а вызов помощи затруднен.
Таблица 4.3
| Год | События, цифры, факты |
| 21.11. 1988 | Вирус Морриса на 24 часа вывел из строя сеть ARPANET. Ущерб составил98 млн. долларов. |
| 1989 | К. Митник подключился к одному из компьютеров ИВС объединенной системы ПВО Североамериканского континента (North American Air Defense Command) |
| 1989 | Группа хакеров MOD уничтожила почти всю информацию в компьютере, используемом корпорацией Educational Broadcasting Corp., общественной телевизионной станцией WNET, канал 13 в Нью-Йорке |
| 1990 | К. Нейдорф осуществил доступ к телефонную сеть системы 911 в девяти штатах США и получил конфиденциальную информациюв виде кодов доступа |
| 1994 | Национальная аудиторская служба Великобритании (National Audit Office - NAO) зарегистрировала 655 случаев НСД и 562 случая заражения вирусами компьютерных систем британских правительственных организаций, что в 1.4 и 3.5 раза соответственно превышает уровень 1993 г. |
| 1994 | В США ущерб от НСД к информационно-вычислительным ресурсам превысил $10 млрд. (в 1991 г. по оценкам USA Research $1.75 млрд.) |
| 1995 | В США из 150 проверенных исследовательских и производственных вычислительных комплексов 48% подверглись успешной реализации НСД. |
| 1995 | В Великобритании ущерб от НСД к информационно-вычислительным ресурсам превысил 5 млрд. Фунтов стерлингов (в 4 раза больше по сравнению с 1989 г.) |
| 1995 | В сети Bitnet (международная академическая сеть) за 2 часа вирус, замаскированный под рождественское поздравление, заразил более 500 тысяч компьютеров по всему миру, при этом сеть IBM прекратила вообще работу на несколько часов. |
| Декабрь 1996 | Компьютерная атака на WebCom (крупнейшего провайдера услуг WWW в США) вывела из строя на 40 часов больше 3000 абонентских пунктов WWW. Атака представляла собой "синхронный поток", которая блокирует функционирование сервера и приводит к "отказу в обслуживании". Поиск маршрута атаки длился 10 часов. |
/p>
Таблица 4.4
| Год | События, цифры, факты |
| 1993 | Была совершена попытка хищения 68 миллионов долларов путем манипуляции с данными в компьютерных сетях Центрального Банка России |
| 1994 | В. Левин проник в компьютерную систему Ситибанка и сумел перевести 2.8 миллиона долларов на счета своих сообщников в США, Швейцарии, Нидерландах и Израиле |
| 1995 | Ущерб, нанесенный банкам США за счет несанкционированного использования компьютерных сете путем введения и "навязывания" ложной информации из Москвы и Санкт-Петербурга российскими хакерами составил за I квартал 1995 г. составил $300 млн. |
| 1997 | Правоохранительными органами России было выявлено 15 компьютерных преступлений, связанных НСД к банковским базам данных. В ходе расследования установлены факты незаконного перевода 6,3 млрд. рублей. Доля компьютерных преступлений от общего числа преступлений в кредитно-финансовой сфере в 1997 г. составила 0,02% при их раскрываемостине более 1-5%. |
| 1998 | Предотвращено хищения на сумму 2 млрд. рублей из филиала одногоиз самых крупных коммерческих банков России |
Согласно существующей статистики в коллективах людей занятых той или иной деятельностью, как правило, только около 85% являются вполне лояльными (честными), а остальные 15% делятся примерно так: 5% - могут совершить что-нибудь противоправное, если, по их представлениям, вероятность заслуженного наказания мала; 5% - готовы рискнуть на противоправные действия, даже если шансы быть уличенным и наказанным складываются 50 на 50; 5% - готовы пойти на противозаконный поступок, даже если они почти уверены в том, что будут уличены и наказаны. Такая статистика в той или иной мере может быть применима к коллективам, участвующим в разработке и эксплуатации информационно-технических составляющих компьютерных систем.
Таким образом, можно предположить, что не менее 5% персонала, участвующего в разработке и эксплуатации программных комплексов, способны осуществить действия криминального характера из корыстных побуждений либо под влиянием каких-нибудь иных обстоятельств.
По другим данным считается, что от 80 до 90% компьютерных нарушений являются внутренними, в частности считается, что на каждого "... подлого хакера приходится один обозленный и восемь небрежных работников, и все они могут производить разрушения изнутри".
Формальные методы доказательства правильности программ и их спецификаций
Традиционные методы анализа ПО связаны с доказательством правильности программ (верификация программ). Начало этому направлению было положено работами П. Наура и Р. Флойда, в которых сформулирована идея приписывания точке программы так называемого индуктивного, или промежуточного утверждения и указана возможность доказательства частичной правильности программы (то есть соответствия друг другу ее предусловия и постусловия), построенного на установлении согласованности индуктивных утверждений.
Фундаментальный вклад в теорию верификации внес Ч. Хоор, высказавший идеи проведения доказательства частичной правильности программы в виде вывода в некоторой логической системе, а Э. Дейкстра ввел понятие слабейшего предусловия, позволяющее одновременно как соответствие друг другу предусловия и постусловия, так и завершимость. Методы доказательства правильности программ принесли определенную пользу программированию. Было отмечено, что эти методы указывают способ рассуждения о ходе выполнения программ, дают удобную систему комментирования программ и устанавливают взаимосвязи между конструкциями языков программирования и их семантикой. Если принять более широкое толкование термина "анализ программ", подразумевая доказательство разнообразных свойств программ или доказательство теорем о программах, то ценность методов анализа станет более ясной. В частности можно исследовать характер изменения выходных значений программы, количество операций при выполнении программы, наличие зацикливаний, незадействованных участков программы. Таким образом, в некоторых частных случаях методы верификации могут применяться и для доказуемого обнаружения программных дефектов.
Формальное доказательство в виде вывода в некоторой логической системе вполне надежно, но сами доказательства оказываются очень длинными и часто необозримыми. Рассмотрим следующий фрагмент программы.
integer r, dd; r:=a; dd:=d; while dd
 d do dd:=2*dd; begin dd:=dd/2; if dd
d do dd:=2*dd; begin dd:=dd/2; if dd
Должно соблюдаться условие, что целые константы a и d удовлетворяют отношениям a
Рассмотрим последовательность значений, заданную выражениями для:
i=0 ddi=d i>0 ddi=2*ddi-1.
Далее с помощью обычных математических приемов можно вывести, что: ddn=d*2n (2.1.1)
Кроме того, поскольку d>0, можно сделать вывод, что для любого конечного значения r отношение ddr>r будет выполняться при некотором конечном значении k; первый цикл завершается при dd=d*2k. Решая уравнение di=2*di-1 относительно di-1, получаем di-1=di/2, что позволяет утверждать, что второй цикл тоже завершится. По окончании первого цикла dd=ddk и поэтому выполняется соотношение
0
Это соотношение сохраняется при выполнении повторяемого оператора второго заголовка. После завершения повторений (в соответствии с заголовком while dd
0
Далее мы доказываем, что после начала работы программы всегда выполняется отношение:
dd

Это следует, например, из того, что возможные значения dd имеют вид (см. (1)) d*2i при 0
k.Следующая задача состоит в том, чтобы показать, что после присваивания r начального значения всегда выполняется отношение
a
Оно выполняется после начальных присваиваний.
Повторяемый оператор первого заголовка (dd:=2*dd) сохраняет отношение (2.1.5), и поэтому весь первый цикл сохраняет отношение (2.1.5).
Повторяемый оператор из второго цикла состоит из двух операторов. Первый (dd:=2*dd) сохраняет инвариантность (2.1.5); второй тоже сохраняет отношение (2.1.5), так как он либо не изменяет значение r, либо уменьшает r на текущее dd, а эта операция в силу (2.1.4) также сохраняет справедливость отношения (2.1.5). Таким образом, весь повторяемый оператор второго цикла сохраняет отношение (2.1.5).
Объединяя отношения (2.1.3) и (2.1.5), получаем, что окончательное значение r удовлетворяет условиям 0
r(mod d), то есть r - наименьший неотрицательный остаток от деления a на d.И хотя методы доказательства правильности программ существенно ограничены для практического использования, тем не менее есть области, где данные методы могут найти прикладное значение.
При этом n и m связаны соотношением n=s*m, где s=log2r (в дальнейших рассуждениях log - логарифм по основанию 2). Наиболее целесообразно выбрать основание r=2? как наиболее экономное представление чисел в машине, ибо при r < 2? на представление чисел уходит больше памяти. Например, широко принятое на практике представление десятичных чисел в двоично-десятичном коде требует на 20 % большего объема памяти, чем двоичное представление тех же чисел.
Тем не менее, иногда полезно представлять ситуацию, когда r=10 или r=10k, например, при отладке программ.
Следует также обратить внимание на тот факт, что при выполнении арифметических операций над числами многократной точности, например, по классическим алгоритмам Кнута, основание r следует уменьшать, чтобы не возникло переполнение разрядной сетки. Так, для операции сложения уменьшение выполняется до r=2?-1, для умножения - до r=2?/2. Однако если архитектурой вычислительной системы предусмотрен флаг переноса или хранение промежуточного результата с двойной точностью, то можно возвращаться к основанию r=2?.
Алгоритм A*B modulo N - алгоритм выполнения операции модулярного умножения
Операнды многократной точности для данного алгоритма представляются в виде одномерного массива целых чисел. Для знака можно зарезервировать элемент с нулевым индексом. Особенности представления чисел при организации взаимодействия алгоритма с другими рабочими программами, при организации ввода-вывода и т.д. рассматриваются, например, в работе. В алгоритме использован известный вычислительный метод "разделяй и властвуй" и реализован способ вычисления "цифра-за-цифрой". Прямое умножение не следует делать по нескольким причинам: во-первых, произведение A*B требует в два раза больше памяти, чем при методе "цифра-за-цифрой"; во-вторых, умножение двух многоразрядных чисел труднее организовать, чем умножение числа многократной точности на число однократной точности. Так, в работе приводятся расчеты на супер-ЭВМ "CRAY-2" для 100-разрядных десятичных чисел: модулярное умножение методом "цифра-за-цифрой" выполняется примерно на 10% быстрее, чем прямое умножение и следующая за ним модульная редукция.
Алгоритм модулярного умножения (алгоритм P) приведен на рис.2.1, а на рис.2.2 представлен псевдокод процедуры ADDK.
Так как B[i]
 P можно не вводить потому, что вероятность того, что B[i] будет равняться 0 пренебрежимо мала, если значение ? не достаточно малым. Ошибка затем все равно будет алгоритмом обнаружена. Проверка
P можно не вводить потому, что вероятность того, что B[i] будет равняться 0 пренебрежимо мала, если значение ? не достаточно малым. Ошибка затем все равно будет алгоритмом обнаружена. Проверка "if p_short-k*n_short>n_short DIV 2"
позволяет представлять k числом однократной точности и работать с наи-меньшими абсолютными остатками в каждой итерации. Значение операнда Pi на каждом шаге итерации должно быть ограничено величиной N.
Теорема 2.1. Пусть Pi - частичное произведение P в конце i-той итерации (т.е. в конце i-того цикла FOR алгоритма P). Тогда для любого i (i=[1,...,n]) abs(Pi)N, rm-1
rm.Доказательство теоремы 2.1. Доказательство теоремы проведем методом индукции. Если k=abs(p_short) DIV n_short, где DIV - целочисленное деление, то
p_short=(k+?)*n_short, (2.1.6)
где k - целое, 0
? < 1.Проверка "if p_short-k*n_short>n_short DIV 2" есть ни что иное, как проверка
? > 0.5 (2.1.7)
На i-том шаге алгоритм вычисляет:
P'=Pi-1*r+A*B[i] (2.1.8)
Возможны два варианта:
Вариант 1. Если k=0, т.е. n_short>abs(p_short) (см. алгоритм), то суммирование при помощи процедуры ADDK не производится и утверждение теоремы выполняется, т.е. abs(Pi) < N .
Вариант 2. Если k > 0, т.е.
n_short < abs(p_short) (2.1.9)
Здесь также возможны два варианта:
Вариант A:
p_short < 0 (2.1.10)
Из (2.1.9) и (2.1.10) следует P' и так как Pi=-P'+k*N (см. алгоритм), то согласно (2.1.7)
Pi= ?*N, если ?
и так как Pi=-P'+(k+1)*N, то
Pi=-(1-?)*N, если ? > 0.5 (2.1.12)
Алгоритм P
m_shifts:=0; while n[m_shifts]=0 do begin shift_left(N and A); m_shifts:=m_shifts+1; end; m:=m_shifts; reset(P); n_short:=N[m]; for i:=n downto 1 do begin shift_left(P);
{сдвиг на 1 элемент влево или
умножение P*r} if b<>0 then addk(A*B[i],{to}P); let p_short represent the 2 high
assimilated digits of P; k:=abs(p_short) div n_short; if p_short-k*n_short > n_short div 2 then
k:=k+1; if k> 0 then begin if p_short < 0 then addk(k*N,{to} P) else addk(-k*N,{to} P); end; end;{for} right shift P, N by m_shifts; if P < 0 then P:=P+N; write(P); {P - результат}
Рис. 2.1. Псевдокод алгоритма модулярного умножения A*B modulo N
Алгоритм ADDK
carry:=0; for i:=1 to m do begin t:=P[i]+k*N[i]+carry; P[i]:=t mod r; carry:=t div r; end; P[m+1]:=carry; write(P); {P - результат}
Рис.2.2. Псевдокод алгоритма вычисления P+k*N (процедура ADDK)
Вариант B:
p_short>0 (2.1.13)
Из (2.1.9) и (2.1.13) следует P'>N и так как Pi=P'-k*N, то согласно (2.1.7)
Pi=-? *N, если ?
и так как Pi=P'-(k+1)*N, то
Pi=(1-?)*N, если ? > 0.5 (2.1.15)
Во всех случаях (2.1.11), (2.1.12), (2.1.14) и (2.1.15), так как 0
.
Примечание. Для чего нужна проверка (2.1.7)
"if p_short-k*n_short>n_short DIV 2" ?
Пусть в конце каждой итерации P принимает максимально возможное значение Pi-1=N-1, а N, A и B[i] заведомо тоже велики: N=rn+1-1, A=rn+1-2, B[i]=r-1. Тогда на i-том шаге согласно (2.1.8):
Pi'=(rn+1-2)*r+(rn+1-2)*(r-1)=2*rn+2-rn+1-4*r+2(2.1.16)

При достаточно большом m, если не введена проверка (2.1.6), то k < 2*r-1, по условию же 0< k < r -1. И из (2.1.16) и (2.1.17) видно, что P придется представлять m+2 разрядами (что определяется слагаемым 2*rn+2), по условию же m+1. Если же ввести проверку (2.1.7), то даже при ?=0,5 т.е.
Pi-1=(N-1)/2 и с учетом того, что если неравенство (2.1.7) выполняется, то Pi меняет знак на противоположный (сравн. (2.1.11), (2.1.12), (2.1.14) и (2.1.15)), из (2.1.6) и (2.1.7) получим, что 0
В алгоритме P используется также известный метод, когда для получения частного от деления двух многоразрядных чисел, используются только старшие цифры этих чисел (см., например, алгоритм D в работе ).Чем больше основание системы счисления r, тем ниже вероятность того, что пробное частное k от деления первых цифр больших чисел не будет соответствовать действительному частному.
Методы доказательства правильности программ могут быть применены для анализа безопасности ПО при существенных ограничениях на размеры и сложность создаваемых программ. Поэтому в частных случаях они могут оказаться более эффективными, чем другие известные методы анализа программ, которые исследуются в следующих разделах данной работы.
Идентификация программ по внутренним характеристикам
Обеспечение безопасности программ, когда их исходные тексты попадают в руки злоумышленников, которые стремятся привнести в код программы РПС до того как программы подвергнутся компиляции, может заключаться в использовании методов идентификации программ и их характеристик.
При установления степени подобия исходной и исследуемой программы целесообразнее всего выбрать критерий, который насколько это возможно, не зависит от маскировок, вносимых в исходный текст программ нарушителем. Для этого необходимо выбрать параметры, характеризующие собственно программу и связанные с такими ее свойствами, которые трудно изменить и которые сохраняются в машинном коде программы. К таким параметрам может относится, например, распределение операторов по тексту программы , которое сложно изменить нарушителю, не искажая назначения программы. Такие изменения требуют глубокого понимания текста программы и логики вносимых изменений, что сопряжено с огромной работой по преобразованию программы.
Сначала рассмотрим вопросы анализа подобия последовательностей операторов в программе, поскольку этот подход не чувствителен к поверхностной маскировке, которую мог бы попытаться внести нарушитель, изменяя некоторые атрибуты программы, например, имена переменных, нумерацию строк и т.п. Для этого необходимо написать программу - анализатор, которая будет тестировать исследуемую программу, и выделять операторы, накапливая их в файле как данные, отражающие порядок их использования. Введем для последовательности операторов программы с номером n обозначение seq n. Тогда последовательность операторов для программ 1 и 2 будет обозначаться seq1 и seq2 соответственно. Одна из характеристик последовательности операторов - частота появления отдельного оператора. Анализ последовательности операторов оказывается эффективным в тех случаях, когда нарушитель изменяет или перемещает отдельные части программы, добавляет дополнительные операторы или погружает скопированную программу в некоторый модуль. При таких манипуляциях значительные участки последовательности операторов сохраняются неизменными, так как попытка изменить их равносильна переписыванию программы с сопутствующей ой трудоемкой операцией отладки.
Рассмотрим распределение частот появления операторов в программе. Если программа скопирована целиком, но при этом замаскирована, число появлений каждого оператора в копии будет аналогично числу появлений в оригинале. Нарушитель может изменить некоторые операторы и добавить новые, но в целом процент изменений в программе, вероятно, будет мал, и распределение частот появления операторов ожидается одинаковым как для копии, так и для оригинала.
В то же время, если программа (или отдельный программный модуль) включена в большую программу необходимо рассматривать другую характеристику, связанную с сохранением структуры последовательности операторов и определяемую некоторой функцией. Такое подобие структур может быть выражена как максимум взаимной корреляцией функций двух программ, положение которого зависит от размещения модуля в программе. Интересен вопрос, будет ли заимствованная программа, откомпилированная в машинный код, обеспечивать достаточное значение корреляционной функции, чтобы выделить модуль, включенный в состав программы, а также будет ли взаимная корреляционная функция машинного кода соответствовать взаимной корреляционной функции исходной программы на языке высокого уровня.
Другая характеристика программы - автокорреляционная функция, определяющая меру соответствия, с которой одни и те же последовательности операторов повторяются в самой программе. По всей видимости, корреляционная функция должна быть чувствительна к добавлению, удалению или перемещению операторов, чем гистограмма частот появления операторов в программе, поскольку при сокращении последовательности значение корреляционной может существенно уменьшаться.
Информационная война
В настоящее время за рубежом в рамках создания новейших оборонных технологий и видов оружия активно проводятся работы по созданию так называемых средств нелетального воздействия. Эти средства позволяют без нанесения разрушающих ударов (например, современным оружием массового поражения) по живой силе и технике вероятного противника выводить из строя и/или блокировать его вооружение и военную технику, а также нарушать заданные стратегии управления войсками.
Одним из новых видов оружия нелетального воздействия является информационное оружие, представляющее собой совокупность средств поражающего воздействия на информационный ресурс противника. Воздействию информационным оружием могут быть подвержены прежде всего компьютерные и телекоммуникационные системы противника. При этом центральными объектами воздействия являются программное обеспечение, структуры данных, средства вычислительной техники и обработки информации, а также каналы связи.
Появление информационного оружия приводит к изменению сущности и характера современных войн и появлению нового вида вооруженного конфликта - информационная война.
Несомненным является то, что информационная война, включающая информационную борьбу в мирное и военное время, изменит и характер военной доктрины ведущих государств мира. Многими зарубежными странами привносится в доктрину концепция выигрывать войны, сохраняя жизни своих солдат, за счет технического превосходства.
Ввиду того, что в мировой практике нет прецедента ведения широкомасштабной информационной войны, а имеются лишь некоторые прогнозы и зафиксированы отдельные случаи применения информационного оружия в ходе вооруженных конфликтов и деятельности крупных коммерческих организаций (см. таблицы данного раздела), анализ содержания информационной войны за рубежом возможен по отдельным публикациям, так как, по некоторым данным информация по этой проблеме за рубежом строго засекречена.
Анализ современных методов ведения информационной борьбы (см. табл.4.5) позволяет сделать вывод о том, что к прогнозируемым формам информационной войны можно отнести следующие:
глобальная информационная война;
информационные операции;
преднамеренное изменение замысла стратегической и тактической операции;
дезорганизация жизненно важных для страны систем;
нарушение телекоммуникационных систем;
обнуление счетов в международной банковской системе;
уничтожение (искажение) баз данных и знаний важнейших государственных и военных объектов.
К методам и средствам информационной борьбы в настоящее время относят:
воздействие боевых компьютерных вирусов и преднамеренных дефектов диверсионного типа;
несанкционированный доступ к информации;
проявление непреднамеренных ошибок ПО и операторов компьютерных систем;
использование средств информационно-психологического воздействия на личный состав;
воздействие радиоэлектронными излучениями;
физические разрушения систем обработки информации.
Таблица 4.5
| Год | События, цифры, факты |
| 1985 | Разведслужбой ФРГ с засекреченного объекта в пригороде Франкфурта успешно проведена операция "Project RAHAB" по проникновению в ИВС и базы данных государственных учреждений и промышленных компаний Великобритании, Италии, СССР, США, Франции и Японии. |
| 1985 | Спецподразделение LAKAM разведслужбы Израиля МОССАД осуществило НСД к ИВС Центра по обеспечению разведывательных операций ВМС США (US Naval Intelligence Support Center - NISC). |
| 1988 | Матиас Шпеер из Ганновера осуществил НСД к информации о программе СОИ и разработках ядерного, химического и биологического оружия из секретных электронных досье Пентагона. |
| Декабрь 1988 | В Ливерморской лаборатории США (Lawrence Livermore National Laboratories - LLNL), занимающейся разработкой ядерного оружия, было зафиксировано 10 попыток НСД через каналы связи с INTERNET. |
| 1989 | Во Франции зарегистрированы попытки НСД в информационные банки данных военного арсенала в Шербуре. |
| Конец 80-х | Группа компьютерных взломщиков из ГДР (Д. Бржезинский, П. Карл, М. Хесс и К. Кох) овладели паролями и кодами доступа к военным и исследовательским компьютерам в США, Франции, Италии, Швейцарии, Великобритании, ФРГ, Японии. |
| 1995 | В космическом центре NASA им. Джонсона (Johnson Space Center) регистрировалось 3-4 попытки НСД в сутки (на 50% больше чем в 1994 г.), 349.2 часов затрачено на восстановление функционирования сети. |
| 1995 | Центр информационной борьбы ВВС (Air Force Information Warfare Center) за первых 3 недели после создания зарегистрировал более 150 попыток НСД только к одному сетевому узлу. |
| Январь 1997 | Через Internet выведена из строя главная машина для хранения информационного архива по проекту FreeBSD (freefall.freebsd.org). |
Используемая терминология
Разработка терминологии в области обеспечения безопасности ПО является базисом для формирования нормативно-правового обеспечения и концептуальных основ по рассматриваемой проблеме. Единая терминологическая база является ключом к единству взглядов в области, информационной безопасности, стимулирует скорейшее развитие методов и средств защиты ПО. Термины освещают основные понятия, используемые в рассматриваемой области на данный период времени. Определения освещают толкование конкретных форм, методов и средств обеспечения информационной безопасности.
Термины и определения
Непреднамеренный дефект - объективно и (или) субъективно образованный дефект, приводящий к получению неверных решений (результатов) или нарушению функционирования КС.
Преднамеренный дефект - криминальный дефект, внесенный субъектом для целенаправленного нарушения и (или) разрушения информационного ресурса.
Разрушающее программное средство (РПС) - совокупность программных и/или технических средств, предназначенных для нарушения (изменения) заданной технологии обработки информации и/или целенаправленного разрушения извне внутреннего состояния информационно-вычислительного процесса в КС.
Средства активного противодействия - средства защиты информационного ресурса КС, позволяющие блокировать канал утечки информации, разрушающие действия противника, минимизировать нанесенный ущерб и предотвращать дальнейшие деструктивные действия противника посредством ответного воздействия на его информационный ресурс.
Несанкционированный доступ - действия, приводящие к нарушению безопасности информационного ресурса и получению секретных сведений.
Нарушитель (нарушители) - субъект (субъекты), совершающие несанкционированный доступ к информационному ресурсу.
Модель угроз - вербальная, математическая, имитационная или натурная модель, формализующая параметры внутренних и внешних угроз безопасности ПО.
Оценка безопасности ПО - процесс получения количественных или качественных показателей информационной безопасности при учете преднамеренных и непреднамеренных дефектов в системе.
Система обеспечения информационной безопасности - объединенная совокупность мероприятий, методов и средств, создаваемых и поддерживаемых для обеспечения требуемого уровня безопасности информационного ресурса.
Информационная технология - упорядоченная совокупность организационных, технических и технологических процессов создания ПО и обработки, хранения и передачи информации.
Технологическая безопасность - свойство программного обеспечения и информации не быть преднамеренно искаженными и (или) начиненными избыточными модулями (структурами) диверсионного назначения на этапе создания КС.
Эксплуатационная безопасность - свойство программного обеспечения и информации не быть несанкционированно искаженными (измененными) на этапе эксплуатации КС.
Эксплуатация
Сведения о персональном составе контролирующего подразделения и испытываемых программных системах
Внедрение злоумышленников в контролирующее подразделение.
Вербовка сотрудников контролирующего подразделения.
Сбор информации о испытываемой программной системе.
Сведения об обнаруженных при контроле программных закладках
Разработка новых программных закладок при доработке программной системы.
Сведения об обнаруженных незлоумышленных дефектах и программных закладках
Сведения о доработках программной системы и подразделениях, их осуществляющих
Сведения о среде функционирования программной системы и ее изменениях
Сведения о функционировании программной системы, доступе к ее загрузочному модулю и исходным данным, алгоритмах проверки сохранности программной системы и данных
Рис.1.3. Пример типовой модели угроз технологической безопасности информации и ПО
Элементы модели угроз эксплуатационной безопасности по
Анализ угроз эксплуатационной безопасности ПО КС позволяет, разделить их на два типа: случайные и преднамеренные, причем последние подразделяются на активные и пассивные. Активные угрозы направлены на изменение технологически обусловленных алгоритмов, программ функциональных преобразований или информации, над которой эти преобразования осуществляются. Пассивные угрозы ориентированы на нарушение безопасности информационных технологий без реализации таких модификаций.
Вариант общей структуры набора потенциальных угроз безопасности информации и ПО на этапе эксплуатации КС приведен в табл.1.2.
Рассмотрим основное содержание данной таблицы. Угрозы, носящие случайный характер и связанные с отказами, сбоями аппаратуры, ошибками операторов и т.п. предполагают нарушение заданного собственником информации алгоритма, программы ее обработки или искажение содержания этой информации. Субъективный фактор появления таких угроз обусловлен ограниченной надежностью работы человека и проявляется в виде ошибок (дефектов) в выполнении операций формализации алгоритма функциональных преобразований или описания алгоритма на некотором языке, понятном вычислительной системе.
Угрозы, носящие злоумышленный характер вызваны, как правило, преднамеренным желанием субъекта осуществить несанкционированные изменения с целью нарушения корректного выполнения преобразований, достоверности и целостности данных, которое проявляется в искажениях их содержания или структуры, а также с целью нарушения функционирования технических средств в процессе реализации функциональных преобразований и изменения конструктива вычислительных систем и систем телекоммуникаций.
На основании анализа уязвимых мест и после составления полного перечня угроз для данного конкретного объекта информационной защиты, например, в виде указанной таблицы, необходимо осуществить переход к неформализованному или формализованному описанию модели угроз эксплуатационной безопасности ПО КС. Такая модель, в свою очередь, должна соотноситься (или даже являться составной частью) обобщенной модели обеспечения безопасности информации и ПО объекта защиты.
К неформализованному описанию модели угроз приходится прибегать в том случае, когда структура, состав и функциональная наполненность компьютерных системы управления носят многоуровневый, сложный, распределенный характер, а действия потенциального нарушителя информационных и функциональных ресурсов трудно поддаются формализации. Пример описания модели угроз при исследовании попыток несанкционированных действий в отношении защищаемой КС приведен на рис.1.4.
После окончательного синтеза модели угроз разрабатываются практические рекомендации и методики по ее использованию для конкретного объекта информационной защиты, а также механизмы оценки адекватности модели и реальной информационной ситуации и оценки эффективности ее применения при эксплуатации КС.
Таким образом, разработка моделей угроз безопасности программного обеспечения КС, являясь одним из важных этапов комплексного решения проблемы обеспечения безопасности информационных технологий, на этапе создания КС отличается от разработки таких моделей для этапа их эксплуатации.
Принципиальное различие подходов к синтезу моделей угроз технологической и эксплуатационной безопасности ПО заключается в различных мотивах поведения потенциального нарушителя информационных ресурсов, принципах, методах и средствах воздействия на ПО на различных этапах его жизненного цикла.
Классификация методов защиты от компьютерных вирусов
Проблему защиты от вирусов необходимо рассматривать в общем контексте проблемы защиты информации от несанкционированного доступа и технологической и эксплуатационной безопасности ПО в целом. Основной принцип, который должен быть положен в основу разработки технологии защиты от вирусов, состоит в создании многоуровневой распределенной системы защиты, включающей:
регламентацию проведения работ на ПЭВМ,
применение программных средств защиты,
использование специальных аппаратных средств.
При этом количество уровней защиты зависит от ценности информации, которая обрабатывается на ПЭВМ. Для защиты от компьютерных вирусов в настоящее время использу-ются следующие методы: Архивирование. Заключается в копировании системных областей магнитных дисков и ежедневном ведении архивов измененных файлов.
Архивирование является одним из основных методов защиты от вирусов. Остальные методы защиты дополняют его, но не могут заменить полностью.
Входной контроль. Проверка всех поступающих программ детекторами, а также проверка длин и контрольных сумм вновь поступающих программ на соответствие значениям, указанным в документации. Большинство известных файловых и бутовых вирусов можно выявить на этапе входного контроля. Для этой цели используется батарея (несколько последовательно запускаемых программ) детекторов. Набор детекторов достаточно широк, и постоянно пополняется по мере появления новых вирусов. Однако при этом могут быть обнаружены не все вирусы, а только распознаваемые детектором. Следующим элементом входного контроля является контекстный поиск в файлах слов и сообщений, которые могут принадлежать вирусу (например, Virus, COMMAND.COM, Kill и т.д.). Подозрительным является отсутствие в последних 2-3 килобайтах файла текстовых строк - это может быть признаком вируса, который шифрует свое тело.
Рассмотренный контроль может быть выполнен с помощью специальной программы, которая работает с базой данных "подозрительных" слов и сообщений, и формирует список файлов для дальнейшего анализа.
После проведенного анализа новые программы рекомендуется несколько дней эксплуатировать в карантинном режиме. При этом целесообразно использовать ускорение календаря, т.е. изменять текущую дату при повторных запусках программы. Это позволяет обнаружить вирусы, срабатывающие в определенные дни недели (пятница, 13 число месяца, воскресенье и т.д.).
Профилактика. Для профилактики заражения необходимо организовать раздельное хранение (на разных магнитных носителях) вновь поступающих и ранее эксплуатировавшихся программ, минимизация периодов доступности дискет для записи, разделение общих магнитных носителей между конкретными пользователями.
Ревизия. Анализ вновь полученных программ специальными средствами (детекторами), контроль целостности перед считыванием информации, а также периодический контроль состояния системных файлов.
Карантин. Каждая новая программа проверяется на известные типы вирусов в течение определенного промежутка времени. Для этих целей целесообразно выделить специальную ПЭВМ, на которой не проводятся другие работы. В случае невозможности выделения ПЭВМ для карантина программного обеспечения, для этой цели используется машина, отключенная от локальной сети и не содержащая особо ценной информации.
Сегментация. Предполагает разбиение магнитного диска на ряд логических томов (разделов), часть из которых имеет статус READ_ONLY (только чтение). В данных разделах хранятся выполняемые программы и системные файлы. Базы данных должны хранится в других секторах, отдельно от выполняемых программ. Важным профилактическим средством в борьбе с файловыми вирусами является исключение значительной части загрузочных модулей из сферы их досягаемости. Этот метод называется сегментацией и основан на разделении магнитного диска (винчестера) с помощью специального драйвера, обеспечивающего присвоение отдельным логическим томам атрибута READ_ONLY (только чтение), а также поддерживающего схемы парольного доступа. При этом в защищенные от записи разделы диска помещаются исполняемые программы и системные утилиты, а также системы управления базами данных и трансляторы, т.е.
компоненты ПО, наиболее подверженные опасности заражения. В качестве такого драйвера целесообразно использовать программы типа ADVANCED DISK MANAGER (программа для форматирования и подготовки жесткого диска), которая не только позволяет разбить диск на разделы, но и организовать доступ к ним с помощью паролей. Количество ис-пользуемых логических томов и их размеры зависят от решаемых задач и объема винчестера. Рекомендуется использовать 3 - 4 логических тома, причем на системном диске, с которого выполняется загрузка, следует оставить минимальное количество файлов (системные файлы, командный процессор, а также программы - ловушки).
Фильтрация. Заключается в использовании программ - сторожей, для обнаружения попыток выполнить несанкционированные действия.
Вакцинация. Специальная обработка файлов и дисков, имитирующая сочетание условий, которые используются некоторым типом вируса для определения, заражена уже программа или нет.
Автоконтроль целостности. Заключается в использовании специальных алгоритмов, позволяющих после запуска программы определить, были ли внесены изменения в ее файл.
Терапия. Предполагает дезактивацию конкретного вируса в заражен-ных программах специальными программами (фагами). Программыфаги "выкусывают" вирус из зараженной программы и пытаются восстановить ее код в исходное состояние (состояние до момента заражения). В общем случае технологическая схема защиты может состоять из следующих этапов:
входной контроль новых программ;
сегментация информации на магнитном диске;
защита операционной системы от заражения;
систематический контроль целостности информации.
Необходимо отметить, что не следует стремиться обеспечить гло-бальную защиту всех файлов, имеющихся на диске. Это существенно затрудняет работу, снижает производительность системы и, в конечном счете, ухудшает защиту из-за частой работы в открытом режиме. Анализ по-казывает, что только 20-30% файлов должно быть защищено от записи.
При защите операционной системы от вирусов необходимо правиль-ное размещение ее и ряда утилит, которое можно гарантировать, что после начальной загрузки операционная система еще не заражена резидентным файловым вирусом.
Это обеспечивается при размещении командного про-цессора на защищенном от записи диске, с которого после начальной загрузки выполняется копирование на виртуальный (электронный) диск. В этом случае при вирусной атаке будет заражен дубль командного процес-сора на виртуальном диске. При повторной загрузке информация на вирту-альном диске уничтожается, поэтому распространение вируса через командный процессор становится невозможным.
Кроме того, для защиты операционной системы может применяться нестандартный командный процессор (например, командный процессор 4DOS, разработанный фирмой J.P.Software), который более устойчив к за-ражению. Размещение рабочей копии командного процессора на виртуальном диске позволяет использовать его в качестве программы-ловушки. Для этого может использоваться специальная программа, которая периодиче-ски контролирует целостность командного процессора, и информирует о ее нарушении. Это позволяет организовать раннее обнаружение факта вирусной атаки.
В качестве альтернативы MS DOS было разработано несколько опера-ционных систем, которые являются более устойчивыми к заражению. Из них следует отметить DR DOS и Hi DOS. Любая из этих систем более "вирусоустойчива", чем MS DOS. При этом, чем сложнее и опаснее вирус, тем меньше вероятность, что он будет работать на альтернативной операцион-ной системе.
Анализ рассмотренных методов и средств защиты показывает, что эффективная защита может быть обеспечена при комплексном использовании различных средств в рамках единой операционной среды. Для этого необходимо разработать интегрированный программный комплекс, под-держивающий рассмотренную технологию защиты. В состав программного комплекса должны входить следующие компоненты.
Каталог детекторов. Детекторы, включенные в каталог, должны запускаться из операционной среды комплекса. При этом должна быть обеспечена возможность подключения к каталогу новых детекторов, а также указание параметров их запуска из диалоговой среды. С помощью данной компоненты может быть организована проверка ПО на этапе входного контроля.
Программа- ловушка вирусов. Данная программа порождается в процессе функционирования комплекса, т.е. не хранится на диске, поэтому оригинал не может быть заражен. В процессе тестирования ПЭВМ программа - ловушка неоднократно выполняется, изменяя при этом текущую дату и время (организует ускоренный кален-дарь). Наряду с этим программа-ловушка при каждом запуске контролирует свою целостность (размер, контрольную сумму, дату и время создания). В случае обнаружения заражения программный комплекс переходит в режим анализа зараженной программы - ловушки и пытается определить тип вируса.
Программа для вакцинации. Предназначена для изменения среды функционирования вирусов таким образом, чтобы они теряли спо-собность к размножению. Известно, что ряд вирусов помечает зараженные файлы для предотвращения повторного заражения. Используя это свойство возможно создание программы, которая обрабатывала бы файлы таким образом, чтобы вирус считал, что они уже заражены.
База данных о вирусах и их характеристиках. Предполагается, что в базе данных будет храниться информация о существующих виру-сах, их особенностях и сигнатурах, а также рекомендуемая стратегия лечения. Информация из БД может использоваться при анализе зараженной программы-ловушки, а также на этапе входного контроля ПО. Кроме того, на основе информации, хранящейся в БД, можно выработать рекомендации по использованию наиболее эффективных детекторов и фагов для лечения от конкретного типа вируса.
Резидентные средства защиты. Отдельная компонента может ре-зидентно разместиться в памяти и постоянно контролировать целостность системных файлов и командного процессора. Проверка может выполняться по прерываниям от таймера или при выполнении операций чтения и записи в файл.
Классификация средств исследования программ
В этом подразделе мы будем исходить из предположения, что на этапе разработки программная закладка была обнаружена и устранена, либо ее вообще не было. Для привнесения программных закладок в этом случае необходимо взять готовый исполняемый модуль, дизассемблировать его и после внесения закладки подвергнуть повторной компиляции. Другой способ заключается в незаконном получении текстов исходных программ, их анализе, внесении программных дефектов и дальнейшей замене оригинальных программ на программы с приобретенными закладками. И, наконец, может осуществляться полная замена прикладной исполняемой программы на исполняемую программу нарушителя, что впрочем, требует от последнего необходимость иметь точные и полные знания целевого назначения и конечных результатов прикладной программы.
Все средства исследования ПО можно разбить на 2 класса: статиче-ские и динамические. Первые оперируют исходным кодом программы как данными и строят ее алгоритм без исполнения, вторые же изучают программу, интерпретируя ее в реальной или виртуальной вычислительной среде. Отсюда следует, что первые являются более универсальными в том смысле, что теоретически могут получить алгоритм всей программы, в том числе и тех блоков, которые никогда не получат управления. Динамические средства могут строить алгоритм программы только на основании конкретной ее трассы, полученной при определенных входных данных. Поэтому задача получения полного алгоритма программы в этом случае эквивалентна построению исчерпывающего набора текстов для подтвер-ждения правильности программы, что практически невозможно, и вообще при динамическом исследовании можно говорить только о построении некоторой части алгоритма.
Два наиболее известных типа программ, предназначенных для иссле-дования ПО, как раз и относятся к разным классам: это отладчик (динамическое средство) и дизассемблер (средство статистического исследования). Если первый широко применяется пользователем для отладки собственных программ и задачи построения алгоритма для него вторичны и реализуются самим пользователем, то второй предназначен исключительно для их решения и формирует на выходе ассемблерный текст алгоритма.
Помимо этих двух основных инструментов исследования, можно ис-пользовать:
"дискомпиляторы", программы, генерирующие из исполняемого кода программу на языке высокого уровня;
"трассировщики", сначала запоминающие каждую инструкцию, проходящую через процессор, а затем переводящие набор инструкций в форму, удобную для статического исследования, автоматически выделяя циклы, подпрограммы и т.п.;
"следящие системы", запоминающие и анализирующие трассу уже не инструкции, а других характеристик, например вызванных программой прерывания.
Кодирование
Архитектура программной системы, взаимодействие ее с внешней средой и взаимодействие подпрограмм программной системы
Доступ к "чужим" подпрограммам и данным.
Нерациональная организация вычислительного процесса.
Организация динамически формируемых команд или параллельных вычислительных процессов.
Организация переадресации команд, запись злоумышленной информации в используемые программной системой или другими программами ячейки памяти.
Функции и назначение кодируемой части программной системы, взаимодействие этой части с другими подпрограммами
Формирование программной закладки, воздействующей на другие части программной системы.
Организация замаскированного спускового механизма программной закладки.
Формирование программной закладки, изменяющей структуру программной системы.
Технология записи программного обеспечения и исходных данных
Поставка программного обеспечения и технических средств со встроенными дефектами.
КонтрольИспользуемые процедуры и методы контроля Формирование спускового механизма программной закладки, не включающего ее при контроле на безопасность. Маскировка программной закладки путем внесения в программную систему ложных "непреднамеренных" дефектов. Формирование программной закладки в ветвях программной системы, не проверяемых при контроле. Формирование "вирусных" программ, не позволяющих выявить их внедрение в программную систему путем контрольного суммирования. Поставка программного обеспечения и вычислительной техники, содержащих программные, аппаратные и программно-аппаратные закладки. |
Контрольно-испытательные методы анализа безопасности программного обеспеченияКонтрольно-испытательные методы - это методы, в которых критерием безопасности программы служит факт регистрации в ходе тестирования программы нарушения требований по безопасности, предъявляемых в системе предполагаемого применения исследуемой программы . Тестирование может проводиться с помощью тестовых запусков, исполнения в виртуальной программной среде, с помощью символического выполнения программы, ее интерпретации и другими методами.
Рис. 2.3. Методы и средства анализа безопасности ПО Контрольно-испытательные методы делятся на те, в которых контролируется процесс выполнения программы и те, в которых отслеживаются изменения в операционной среде, к которым приводит запуск программы. Эти методы наиболее распространены, так как они не требуют формального анализа, позволяют использовать имеющиеся технические и программные средства и быстро ведут к созданию готовых методик. В качестве примера - можно привести методику пробного запуска в специальной среде с фиксацией попыток нарушения систем защиты и разграничения доступа. Рассмотрим формальную постановку задачи анализа безопасности ПО для решения ее с помощью контрольно-испытательных методов. Пусть задано множество ограничений на функционирование программы, определяющих ее соответствие требованиям по безопасности в системе предполагаемой эксплуатации. Эти ограничения задаются в виде множества предикатов С={ci(a1,a2,...am)|i=1,...,N} зависящих от множества аргументов A={ai|i=1,...,M}. Это множество состоит из двух подмножеств: подмножества ограничений на использование ресурсов аппаратуры и операционной системы, например оперативной памяти, процессорного времени, ресурсов ОС, возможностей интерфейса и других ресурсов; подмножества ограничений, регламентирующих доступ к объектам, содержащим данные (информацию), то есть областям памяти, файлам и т.д. Для доказательства того, что исследуемая программа удовлетворяет требованиям по безопасности, предъявляемым на предполагаемом объекте эксплуатации, необходимо доказать, что программа не нарушает ни одного из условий, входящих в С. Для этого необходимо определить множество параметров P={pi|i=1,...,K}, контролируемых при тестовых запусках программы. Параметры, входящие в это множество определяются используемыми системами тестирования. Множество контролируемых параметров должно быть выбрано таким образом, что по множеству измеренных значений параметров Р можно было получить множество значений аргументов А. После проведения Т испытаний по вектору полученных значений параметров Pi,i=1,...,T можно построить вектор значений аргументов Ai, i=1,...,T. Тогда задача анализа безопасности формализуется следующим образом. Программа не содержит РПС, если для любого ее испытания i=1,...,T множество предикатов C={cj(a1i,a2i...aMi)|j=1,...,N} истинно. Очевидно, что результат выполнения программы зависит от входных данных, окружения и т.д., поэтому при ограничении ресурсов, необходимых для проведения испытаний, контрольно-испытательные методы не ограничиваются тестовыми запусками и применяют механизмы экстраполяции результатов испытаний, включают в себя методы символического тестирования и другие методы, заимствованные из достаточно проработанной теории верификации (тестирования правильности) программы. Рассмотрим схему анализа безопасности программы контрольно-испытательным методом (рис.2.4). Контрольно-испытательные методы анализа безопасности начинаются с определения набора контролируемых параметров среды или программы. Необходимо отметить, что этот набор параметров будет зависеть от используемого аппаратного и программного обеспечения (от операционной системы) и исследуемой программы. Затем необходимо составить программу испытаний, осуществить их и проверить требования к безопасности, предъявляемые к данной программе в предполагаемой среде эксплуатации, на запротоколированных действиях программы и изменениях в операционной среде, а также используя методы экстраполяции результатов и стохастические методы. Очевидно, что наибольшую трудность здесь представляет определение набора критичных с точки зрения безопасности параметров программы и операционной среды.Они очень сильно зависят от специфики операционной системы и определяются путем экспертных оценок. Кроме того в условиях ограниченных объемов испытаний, заключение о выполнении или невыполнении требований безопасности как правило будет носить вероятностный характер. Краткое описание криптографических средств контроля целостности и достоверности программОсновные положения криптологии и базовые криптографические понятия Термин "криптология" происходит от двух греческих слов: "крипто", что означает "тайный" и "логос", т.е. - учение. Криптология как наука, состоит из двух тесно теоретически и практически связанных дисциплин: криптографии и криптоанализа. Криптография - наука о способах преобразования (шифрования) информации с целью ее защиты от незаконных пользователей. Криптоанализ - наука (и практика ее применения) о методах и способах вскрытия шифров. Криптография и криптоанализ очевидным образом связаны друг с другом, так как не бывает хороших криптографов, не владеющих методами криптоанализа, и наоборот - хороший криптоаналитик должен быть знаком со всеми известными способами построения шифров. Ниже даются базовые понятия и определения криптологии, в т.ч. используемые и в настоящем разделе. Шифр (криптосистема) - способ, метод преобразования информации с целью ее защиты от незаконных пользователей (от противника). Для противника возникает сложная задача вскрытия шифра. Вскрытие (взламывание) шифра - процесс получения информации из шифрованного сообщения (шифртекста) без знания примененного шифра. Шифрование - процесс применения шифра к защищаемой информации, т.е. преобразование информации в шифрованное сообщение с помощью определенных правил, содержащихся в шифре. Дешифрование - процесс, обратный шифрованию, т.е. преобразование шифрованного сообщения в защищаемую информацию с помощью определенных правил, содержащихся в шифре. Исходное сообщение, имеющее, как правило, смысловое (логически значимое) содержание, которое необходимо зашифровать называется открытым текстом. Зашифрованное сообщение, имеющее, как правило, вид случайного набора символов (цифр) называется шифртекстом или криптограммой. Под ключом в криптографии понимают сменный элемент шифра, который применен для шифрования конкретного открытого текста (сообщения). В криптографии обычно общепринято следующее допущение. Криптоаналитик (противник) почти всегда имеет полный шифртекст. Помимо этого в криптографии принято правило Керкхоффа, которое гласит, что "стойкость шифра должна определяться только секретностью его ключа". В этом случае задача противника сводится к попытке раскрытия шифра (попытке осуществления атаки) на основе шифртекста. Если же противник имеет к тому же некоторые отрывки открытого текста и соответствующие им элементы шифртекста, тогда он пытается осуществлять атаку на основе открытого текста. Атака на основе выбранного открытого текста заключается в том, что противник, используя свой открытый текст, получает правильный шифртекст (например, используя "вслепую" некоторую шифрмашину) и пытается в этом случае вскрыть шифр. Попытку раскрытия шифра можно осуществить, если противник подставляет свой ложный шифртекст и при дешифровании получает необходимый для раскрытия шифра открытый текст. Такой способ раскрытия называется атакой на основе выбранного шифртекста. Теоретически существует абсолютно стойкий шифр, но единственным таким шифром является какая-нибудь форма так называемой ленты однократного использования (или так называемый "одноразовый блокнот"), в которой открытый текст "объединяется" с полностью случайным ключом такой же длины. Этот результат был доказан К. Шенноном с помощью разработанного им теоретико-информационного метода исследования шифров. Для абсолютной стойкости существенным является каждое из следующих требований к ленте однократного использования: полная случайность (равновероятность) ключа (это, в частности, означает, что ключ нельзя вырабатывать с помощью какого-либо детерминированного устройства); равенство длины ключа и длины открытого текста; однократность использования ключа. В то же время, именно эти условия и делают абсолютно стойкий шифр очень ресурсозатратным и непрактичным. Прежде чем пользоваться таким шифром, необходимо обеспечить всех абонентов достаточным запасом случайных ключей и исключить возможность их повторного применения. А это сделать необычайно трудно и дорого. В силу данных причин абсолютно стойкие шифры применяются только в сетях связи с небольшим объемом передаваемой информации, обычно это сети для передачи особо важной государственной информации. В 1976 г. опубликовав свою работу "Новые направления в криптографии", американские ученые У. Диффи и М. Хеллман выдвинули следующую удивительную гипотезу: "Возможно построение практически стойких криптосистем, вообще не требующих передачи секретного ключа". Такие криптосистемы, получившие название криптосистем с открытым ключом, основываются на введении понятий "односторонней функции" и "односторонней функции с секретом". Понятие односторонней функции было введено в подразделе 2.4 Вопрос о существовании односторонней функции с секретом является столь же гипотетическим, что и вопрос о существовании односторонней функции. Для практических целей было построено несколько функций, которые могут оказаться односторонними, а это означает, что задача инвертирования эквивалентна некоторой давно изучаемой трудной математической задаче (см., например, ). Применение односторонних функций в криптографии позволяет: во-первых, организовать обмен шифрованными сообщениями с использованием только открытых каналов связи и, во-вторых, решать новые криптографические задачи, такие как электронная цифровая подпись. В большинстве схем электронной подписи используются хэш-функции. Это объясняется тем, что практические схемы электронной подписи не способны подписывать сообщения произвольной длины, а процедура, состоящая в разбиении сообщения на блоки и в генерации подписи для каждого блока по отдельности, крайне неэффективна. Под термином "хэш-функция" понимается функция, отображающие сообщения произвольной длины в значение фиксированной длины, которое называется хэш-кодом. Далее рассмотрим базовые криптографические методы, широко применяющиеся в современных системах обеспечения безопасности информации. Краткое описание основных криптографических методов защиты данных Симметричный шифр ГОСТ 28147-89 Пусть L и R - последовательности битов, LR означает их конкатенацию. Под обозначением  A[+]B=A B < 232A[+]B=A BСимволом {+} обозначается операция сложения по модуль 232-1 двух 32-разрядных чисел. Правила суммирования чисел следующие: A{+}B=A B < 232-1A{+}B=A BВо всех режимах работы алгоритма используется ключ длиной 256 битов, который представляется в виде восьми 32-разрадных чисел X(i).Если обозначить ключ через W, то W=X(7)X(6)X(5)X(4)X(3)X(2)X(1)X(0). Дешифрование, как и в любой симметричной криптосистеме осуществляется на том же ключе, что и шифрование. Ниже приводится описание двух наиболее используемых режимов шифра: режима простой замены и режима генерации имитовставки . Описание режима простой замены. Код программы T разбивается на блоки по 64 бита в каждом, которые обозначаются T(j). Очередная последовательность битов T(j) разбивается на две последовательности B(0) (левые или старшие биты) и A(0) (правые или младшие биты), каждая из которых содержит 32 бита. Затем выполняется итеративный процесс шифрования, который описывается следующими формулами: при i=1,2,...,24; j=i-1(mod 8) A(i)=f(A(i-1)[+]X(j)(+)B(i-1)); B(i)-A(i-1); при i=25,26,...,31; j=32-i A(i)=f(A(i-1)[+]X(j)(+)B(i-1)); B(i)-A(i-1); при i=32 A(32)=A(31); B(32)=f(A(31)[+]X(0)(+)B(31)), где i обозначает номер итерации (i=1,2,...,32). Функция f называется функцией шифрования. Ее аргументом является сумма по модулю 232 числа A(i), полученного на предыдущем шаге итерации, в числа X(j) ключа (размерность каждого из этих чисел 32 знакам). Функция шифрования включает две операции над полученной 32-разрядной суммой. Первая операция называется подстановкой K. Блок подстановки K состоит из восьми узлов замены K(1)...K(8) с памятью 64 бита каждый. Поступающий на блок подстановки 32-разрядный вектор разбивается на 8 последовательно идущих 4- разрядных векторов, каждый из которых преобразуется в 4-разрядный вектор соответствующим узлом замены, представляющим собой таблицу из 16 целых чисел в диапазоне 0,...,15. Входной вектор определяет адрес строки в таблице, число из которой является выходным вектором. Затем 4-разрядные выходные векторы последовательно объединяются в 32-разрядный вектор. Таблицы блока подстановки блока подстановки K содержат редко изменяемые ключевые элементы, общие для некоторой компьютерной системы. Вторая операция - циклический сдвиг влево 32-разрядного вектора, полученного в результате подстановки K. 64-разрядный блок зашифрованных данных Тш представляется в виде: Тш=A(32)B(32). Остальные блоки кода программы в режиме простой замены шифруются аналогично. Режим генерации имитовставки. Для получения имитовставки код программы представляется в виде 64-разрядных блоков T(i), =1,2,..,m. Где m определяет объем кода программы. Первый блок кода программы T(i) подвергается преобразованию, соответствующему первым 16 циклам алгоритма шифрования в режиме простой замены, причем в качестве ключа для выработки имитовставки используется ключ, по которому шифруются данные. Полученное после 16 циклов работы 64-разрядное число суммируется по модулю 2 со вторым блоком открытых данных T(2). Результат суммирования снова подвергается преобразованию, соответствующему 16 циклам алгоритма шифрования в режиме простой замены. Полученное 64-разрядной число суммируется по модулю 2 с третьим блоком данных T(3) и т.д. Последний блок T(m), при необходимости дополненный до полного 64-разрядного блока нулями, суммируется по модулю 2 с результатом работы на шаге m-1, после чего шифруется в режиме простой замены по первым 16 циклам алгоритма. Из полученного 64-разрядного числа выбирается отрезок Ир длиной р битов. Данный отрезок и является имитовставкой Ир, полученной для кода программы T. Открытый ключевой обмен Диффи-Хеллмана и криптосистемы с открытым ключом Основная задача ключевого обмена Диффи-Хеллмана заключается в следующем: " Каким образом можно установить секретный ключ между абонентами А и В по открытому каналу связи а затем использовать его для шифрованной передачи сообщений?" Для этих целей, пусть абонент A выбирает какую-нибудь функцию fk с секретом k. Он публикует в открытом сертифицированном справочнике описание функции fk в качестве своего алгоритма шифрования. Однако, значение секрета k он никому не сообщает, т.е. держит его в тайне от других. Если абонент B хочет послать А защищаемую информацию x A. Поскольку A для своего секрета k умеет инвертировать fk, то он вычисляет x по полученному y. Так как никто другой не знает k и поэтому в силу свойств функции с секретом не сможет за полиномиальное время по известному шифрованному сообщению y вычислить защищаемую информацию x.Описанная выше схема является криптосистемой с открытым ключом, поскольку алгоритм шифрования fk является общедоступным или открытым. Такие криптосистемы называют еще асимметричными, поскольку в них есть асимметрия в алгоритмах: алгоритмы шифрования и дешифрования различны. В отличие от таких систем традиционные шифры называют симметричными, так как в них ключ для шифрования и дешифрования один и тот же, и именно поэтому его нужно хранить в секрете. Для асимметричных систем алгоритм шифрования общеизвестен, но восстановить по нему алгоритм дешифрования за полиномиальное время невозможно. Электронная цифровая подпись Основные определения, обозначения и алгоритмы. Для реализации схем электронной цифровой подписи (или просто цифровой подписи) требуются три следующих эффективно функционирующих алгоритма: Ak - алгоритм генерации секретного и открытого ключей для подписи кода программы, а также проверки подписи, - s и p соответственно; As - алгоритм генерации (проставления) подписи с использованием секретного ключа s; Ap - алгоритм проверки (верификации) подписи с использованием открытого ключа p. Алгоритмы должны быть разработаны так, чтобы выполнялось основное принципиальное свойство, - свойство невозможности получения нарушителем (противником) алгоритма As из алгоритма Ap. Таким образом, если Ak - алгоритм генерации ключей, тогда определим значения (s,p)=Ak(?,?) как указанные выше сгенерированные ключи, где ? - некоторый параметр безопасности (как правило, длина ключей), а ? - параметр, характеризующий случайный характер работы алгоритма Ak при каждом его вызове. Ключ s хранится в секрете, а открытый ключ p делается общедоступным. Это делается, как правило, путем помещения открытых ключей пользователей в открытый сертифицированный справочник. Сертификация открытых ключей справочника выполняется некоторым дополнительным надежным элементом, которому все пользователи системы доверяют обработку этих ключей. Обычно этот элемент называют Центром обеспечения безопасности или Центром доверия. Непосредственно процесс подписи осуществляется посредством алгоритма As. В этом случае значение c=As(m) - есть подпись кода программы m, полученная при помощи алгоритма As и ключа s. Процесс верификации выполняется следующим образом. Пусть m* и c* - код программы и подпись для этого кода соответственно, Ap - алгоритм верификации. Тогда, выбрав из справочника общедоступный открытый ключ p, можно выполнить алгоритм верификации: b=Ap(m*,c*), где предикат b Примеры схем электронной цифровой подписи. К наиболее известным схемам цифровой подписи с прикладной точки зрения относятся схемы RSA, схемы Рабина-Уильямса, Эль-Гамаля, Шнорра и Фиата-Шамира , а также схема электронной цифровой подписи отечественного стандарта ГОСТ Р 34.10-94 . Рассмотрим несколько подробнее четыре наиболее известные схемы цифровой подписи: Подпись RSA: Вход: Числа n, p, q, где p и q - большие l - разрядные простые числа, n=pq. Открытый ключ p=(e,n), секретный ключ s=d, такой, что ed Генерация ключей:(d,(e,n))=Ak(l,b). Подпись:As: 1.md(mod n) кода программы m. Верификация:Ap: 1.[c*]e(mod n) Подпись Эль-Гамаля: Вход: Числа p и g, где p - простое l - разрядное число, а g - первообразный корень по модулю p. Секретный ключ s=d, открытый ключ p=e, такой, что e Генерация ключей:(d,(e,g,p))=Ak(l,b). Подпись: As: 1.r RZp-1;2.находится такое c, что m где (c,r) - подпись кода m. Верификация:Ap: 1.если gm*=errc*(mod p), то подпись верна. Подпись Фиата - Шамира: Вход: Числа n, p, и q, где p и q большие l - разрядные простые числа, открытый ключ p есть вектор (v1,v2,...,vk), где vj - квадратичные вычеты по модулю n, j= 
1. Секретный ключ подписи x (1 < x < q) и открытый ключ y
/p> Под стойкостью схемы цифровой подписи понимается стойкость в теоретико-сложностном смысле, то есть, как отсутствие эффективных алгоритмов ее подделки и (или) раскрытия . По-видимому, до сих пор основной является следующая классификация: атака с открытым ключом, когда противник знает только открытый ключ схемы; атака на основе известного открытого текста (известного кода программы), когда противник получает подписи для некоторого (ограниченного) количества известных ему кодов (при этом противник никак не может повлиять на выбор этих кодов); атака на основе выбранного открытого текста, когда противник может получить подписи для некоторого ограниченного количества выбранных им кодов программы (предполагается, что коды выбираются независимо от открытого ключа, например, до того как открытый ключ станет известен); направленная атака на основе выбранного открытого текста (то же, что предыдущая, но противник, выбирая код программы, уже знает открытый ключ); адаптивная атака на основе выбранного открытого текста, когда противник выбирает коды программы последовательно, зная открытый ключ и зная на каждом шаге подписи для всех ранее выбранных кодов. Атаки перечислены таким образом, что каждая последующая сильнее предыдущей. Угрозами для схем цифровой подписи являются раскрытие схемы или подделка подписи. Определяются следующие типы угроз: полного раскрытия, когда противник в состоянии вычислить секретный ключ подписи; универсальной подделки, когда противник находит алгоритм, функционально эквивалентный алгоритму вычисления подписи; селективной подделки, когда осуществляется подделка подписи для кода программы, выбранного противником априори; экзистенциональной подделки, когда осуществляется подделка подписи хотя бы для одного кода программы (при этом противник не контролирует выбор этого кода, которое может быть вообще случайным или бессмысленным). Угрозы перечислены в порядке ослабления. Стойкость схемы электронной подписи определяется относительно пары (тип атаки, угроза). Если принять вышеописанную классификацию атак и угроз, то наиболее привлекательной является схема цифровой подписи, стойкая против самой слабой из угроз, в предположении, что противник может провести самую сильную из всех атак. В этом случае, такая схема должна быть стойкой против экзистенциональной подделки с адаптивной атакой на основе выбранного открытого текста. Разновидности схем подписи электронных сообщений. Для обеспечения целостности и достоверности информации при ее передаче и хранении, а также для проведения аутентификации абонентов системы и решения других задач защиты существует достаточно много всевозможных разновидностей схем подписи . Без подробного описания ниже приводится одна из разновидностей схем подписи, которая, как правило, использует рассмотренный выше математический аппарат и может использоваться для защиты программ. Схема подписи с верификацией по запросу. В работах Д. Шаума (см., например, [,]) впервые была предложена схема подписи с верификацией по запросу, в которой абонент V не может осуществить верификацию подписи без участия абонента S. Такие схемы могут эффективно использоваться в том случае, когда фирма - изготовитель поставляет потребителю некоторый информационный продукт (например, программное обеспечение) с проставленной на нем подписью указанного вида . Однако проверить эту подпись, которая гарантирует подлинность программы или отсутствие ее модификаций, можно только уплатив за нее. После факта оплаты фирма - изготовитель дает разрешение на верификацию корректности полученных программ. Схема состоит из трех этапов (протоколов), к которым относятся непосредственно этап генерации подписи, этап верификации подписи с обязательным участием подписывающего (протокол верификации) и этап оспаривания, если подпись или целостность подписанных сообщений подверглась сомнению (отвергающий протокол). I. Генерация подписи. Пусть каждый пользователь S имеет один открытый ключ P и два секретных ключа S1 и S2. Ключ S1 всегда остается в секрете, - он необходим для генерации подписи. Ключ S2 может быть открыт для того, чтобы конвертировать схему подписи с верификацией по запросу в обычную схему электронной цифровой подписи. Вместе с обозначениями секретного и открытого ключей x RZ*p (взятых из отечественного стандарта на электронную цифровую подпись) введем также обозначения S1=x и S2=u, ugu(mod p). Открытый ключ P публикуется в открытом сертифицированном справочнике.Подпись кода m вычисляется следующим образом. Выбирается k gk(mod p). Затем вычисляется sgswy-rw , где wПроверка подписи (с участием подписывающего) осуществляется посредством следующего интерактивного протокола. II. Протокол верификации. Абонент вычисляет ? logr(p)?. Для этого:Абонент V выбирает a,b ragb(mod p) и посылает ? абоненту S. Абонент S выбирает t?g1(mod p), h2V. Абонент V высылает параметры a и b. Если ?Абонент V проверяет выполнение равенств h1?awb+1(mod p) . Если проверка завершена успешно, то подпись принимается как корректная. III. Отвергающий протокол. В отвергающем протоколе S доказывает, что logg(p)w Абонент V выбирает d,e 1, ?ge(mod p), bre(mod p) , bS значения a, b, d. Абонент S проверяет соотношение au(mod p)RZq, вычисляет cV значение c. Абонент V посылает абоненту S значение e. Абонент S проверяет, что выполняются соотношения из следующих двух их пар: awe(mod p) и a?e(mod p).Если да, то посылает V значение R. Иначе останавливается. Абонент V проверяет, что d?gR Если во всех l циклах проверка в п. 5 выполнена успешно, то абонент V принимает доказательства. Таблица 3.1. Протокол верификации является интерактивным протоколом доказательств с абсолютно нулевым разглашением. Доказательство. Требуется доказать, что вышеприведенный протокол удовлетворяет трем свойствам: полноты, корректности и нулевого разглашения [,]. Полнота означает, что если оба участника (V и S) следуют протоколу и (r,s) - корректная подпись для сообщения m, то V примет доказательство с вероятностью близкой к 1. Из описания протокола верификации очевидно, что абонент S всегда может надлежащим образом ответить на запросы абонента V, то есть доказательство будет принято с вероятностью 1. Корректность означает, что если V действует согласно протоколу, то какие действия не предпринимал бы S, он может обмануть V лишь с пренебрежимо малой вероятностью. Здесь под обманом понимается попытка S доказать, что logg(p)w Предположим, что logg(p)w  где a1 logg(p)r logw(p)?.Отсюда, очевидно, следует, что logg(p)w logg(p)r  что противоречит предположению. Следовательно, какие бы h1, h2, t1 и t2 не выбрал S, проверка, которую проводит V, может быть выполнена только для одного значения a. Отсюда вероятность обмана не превосходит 1/q. Отметим, что протокол верификации является безусловно стойким для абонента V, то есть доказательство корректности не зависит ни от каких предположений о вычислительной мощности доказывающего (S). Свойство нулевого разглашения означает, что в результате выполнения протокола абонент V не получает никакой полезной для себя информации (например, о секретных ключах, используемых S). Для доказательства нулевого разглашения необходимо для любого возможного проверяющего V* построить моделирующую машину MV , которая является вероятностной машиной Тьюринга, работает за полиномиальное в среднем время и создает на выходе (без участия S) такое же распределение случайных величин, которое возникает у V* в результате выполнения протокола. В нашем случае, случайные величины, которые "видит" V*, - это h1, h2, и t. Необходимо доказать, что протокол верификации является доказательством с абсолютно нулевым разглашением, то есть моделирующая машина создает распределение случайных величин (h1,h2,t), которое в точности совпадает с их распределением, возникающим при выполнении протокола. Моделирующая машина MV использует в своей работе V* в качестве "черного ящика". Моделирующая машина Запоминает состояние машины V*, то есть содержимое всех ее лент, внутреннее состояние и позиции головок на лентах. Затем получает от V* значение ? и после этого снова запоминает состояние машины V*. Выбирает ? g?(modp) и h`2`Получает от V* значения a и b. Если ?Машина MV` "отматывает" V* на состояние, которое было запомнено в конце шага 1. Выбирает tragb+1(modp) и h2Машина MV` передает V* h1, h2 и получает ответ (a`,b`). Возможны два варианта: 5.1. a=a` , b=b` . В этом случае моделирование закончено и MV` записывает на выходную ленту тройку (h1,h2,t) и останавливается.5.2. a b` . Отсюда следует, что ?ra`gb`(modp) . Предположим, что ba`. Следовательно, MV` может вычислить rМашина MV` "отматывает" V* на состояние, которое было за-полнено в начале шага 1. Получает от V* значение ?. Выбирает ? g?(modp) и h2Получает от V* значения a и b. Если ?В противном случае вычисляет t=[?-al-b](mod q), выдает (h1,h2,t) на выходную ленту и останавливается. К пп. 7 и 8 необходимо сделать следующее пояснение. Поскольку logg(p)w logg(p)r. Отсюдаh2 wb+1walИз описания моделирующей машины MV` очевидно, что она работает за полиномиальное время. Величины (h1,h2,t) на шаге 5.1 выбираются в точности как в протоколе и поэтому имеют такое же распределение вероятностей. Кроме того, значения (h1,h2), выбираемые на шаге 7, имеют такое же распределение, как и в протоколе. Чтобы показать что и t имеет одинаковое распределение, достаточно заметить, что машина V* не может по h1 и h2 определить, с кем она имеет дело - с S или MV`.Поэтому, даже если бы V* могла каким-либо "хитрым" образом строить a и b с учетом (h1,h2), распределение вероятностей величин a и b в обоих случаях одинаковы. Но значение t определяется однозначно четверкой величин a, b, h1, h2, при условии выполнения проверки на шаге 5 протокола. Таблица 3.2. Отвергающий протокол является протоколом доказательства с абсолютно нулевым разглашением. Доказательство. Полнота протокола очевидна. Если абоненты S и V следуют протоколу, тогда абонент V всегда примет доказательства абонента S. Для доказательства корректности прежде всего заметим, что если logg(p)w Если же S может сгенерировать c таким образом, что с вероятностью, которая не является пренебрежимо малой, он может на шаге 4 "открыть" оба значения ?, то есть найти R1 и R2 такие, что 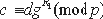  , то алгоритм, который использует S для этой цели, можно использовать для вычисления дискретных логарифмов: loggd=R2-R1. , то алгоритм, который использует S для этой цели, можно использовать для вычисления дискретных логарифмов: loggd=R2-R1.Так как при случайном выборе значения d логарифм loggd может быть вычислен с вероятностью, которая не является пренебрежимо малой, это противоречит гипотезе о трудности вычисления дискретных логарифмов. Далее доказывается, что отвергающий протокол является доказательством с абсолютно нулевым разглашением. Для этого необходимо для всякого возможного проверяющего V* построить моделирующую машину MV`, которая создает на выходе (без участия S) такое же распределение случайных величин (в данном случае, c и R), какое возникает у V* в результате выполнения протокола. Моделирующая машина Следующие шаги выполняются в цикле l раз. Машина MV` запоминает состояние машины V*. Получает от V* значения a, b и d. Выбирает ? RZq и вычисляет cV* значение c. Получает от V* значение e. Проверяет, было ли "угадано" на шаге 2 значение ? (это значение было "угадано", если awe(modp) и ?=0, либо ??e(modp) и ?=1). Если да, то записывает на входную ленту значение (c,R). В противном случае "отматывает" V* на то состояние, которое было запомнено на шаге 1, и переходит на шаг 2.Легко видеть, что распределения случайных величин (c,R), возникающее в процессе выполнения протокола и создаваемые моделирующей машиной MV`, одинаковы, поскольку R в обоих случаях - чисто случайная величина, а величина c записывается на выходную ленту машины MV` только тогда, когда ? совпало с ?. Поскольку значение ? выбирается машиной MV` на шаге 3 случайным образом, а c не дает V* никакой информации о значении ?, на каждой итерации ? будет угадано с вероятностью 1/2. Отсюда следует, что машина MV` работает за полиномиальное в среднем время. В работе показано, как строить схемы конвертируемой и селективно конвертируемой подписи с верификацией по запросу на основе отечественного стандарта ГОСТ Р 34.10-94. В таких схемах открытие определенного секретного параметра некоторой схемы подписи с верификацией по запросу позволяет трансформировать последнюю в обычную схему цифровой подписи. При этом открытие секретного параметра в конвертируемой схеме подписи с верификацией по запросу дает возможность верифицировать все имеющиеся и сгенерированные в дальнейшем подписи, в то время как в селективно конвертируемых схемах подписи с верификацией по запросу можно верифицировать лишь какую-либо одну подпись. Процедуры арбитража. Часто разработчиками схем цифровой подписи при их создании, наряду с процедурами генерации и верификации цифровой подписи, не приводятся процедуры арбитража, которые позволяют установить корректность/ некорректность подписи в случае возникновения споров между участниками схемы. Проблеме арбитража в литературе уделяется мало внимание еще по-видимому и потому, что разработка арбитражных процедур считается прерогативой конкретного пользователя системы. В случае возникновения проблемы по поводу корректности подписи основные действия участников процесса должны сводиться к следующему: Абонент V предъявляет арбитру сообщение и его подпись. Арбитр требует предъявить секретный ключ подписи абоненту S. Если абонент S отказывается, тогда арбитр дает заключение, что подпись подлинная. (То есть, в данном случае возможное нарушение сводится к тому, что абонент отказывается признать представленную подпись своей). Арбитр выбирает из открытого сертифицированного справочника открытый ключ абонента S и проверяет его соответствие секретному ключу подписи. При обнаружения несоответствия (например, по вине службы ведения такого справочника) арбитр признает подпись, предъявленную абонентом V, подлинной. Арбитр проверяет корректность подписи при помощи проверочных соотношений, используемых как при генерации, так и при верификации данной подписи. Одна из основных проблем при арбитраже связана с тем, что арбитр получает секретный ключ абонента S. В том случае, если арбитр является нечестным, то тогда никаких способов защиты пользователей системы от него не может быть в принципе. Помимо этого, следует также сказать о том, что желательно, чтобы пользователь генерировал свои секретные ключи самостоятельно, так как даже создание специального центра генерации ключей не может полностью обезопасить пользователей от слабых ключей и полностью исключает в данном случае возможность решения споров в суде. Хэш-функции Основные определения, обозначения и алгоритмы. Под термином "хэш-функция" понимается функция, отображающая электронные данные произвольной длины (иногда длина ограничена, но достаточно большим числом), в значения фиксированной длины. Последние часто называют хэш-кодами. Таким образом, у всякой хэш-функции h имеется большое количество коллизий, то есть пар значений x и y таких, что h(x)=h(y). Основное требование, предъявляемое криптографическими приложениями к хэш-функциям, состоит в отсутствии эффективных алгоритмов поиска коллизий. Хэш-функция, обладающая таким свойством, называется хэш-функцией, свободной от коллизий. Кроме того, хэш-функция должна быть односторонней, то есть функцией, по значению которой вычислительно трудно найти ее аргумент и, в то же время, функцией, для аргумента которой, вычислительно трудно найти другой аргумент, который давал бы то же самое значение функции. Таким образом, хэш-функции вместе со схемами электронной цифровой подписи предназначены для решения задач обеспечения целостности и достоверности электронных данных. В прикладных компьютерных системах требуется применение так называемых криптографически стойких хэш-функций. Под термином "криптографически стойкая хэш-функция" понимается функция h, которая является односторонней и свободной от коллизий. Введем следующие обозначения. Хэш-функция h обозначается как h(?) и h(?,?) для одного и двух аргументов соответственно. Хэш-код функции h обозначается как H. При этом H0=I обозначает начальное значение (вектор инициализации) хэш-функции. Под обозначением Для лучшего понимания дальнейшего материала приведем небольшой пример построения хэш-функции. Предположим нам необходимо получить хэш-код для некоторой программы M. В качестве шифрующего преобразования в хэш-функции будут использоваться процедуры шифра DES с ключом k. Тогда, чтобы получить хэш-код H программы M при помощи хэш-функции h необходимо выполнить следующую итеративную операцию:  где код программы M разбит на n 64-битных блока. Хэш-кодом данной хэш-функции является значение H=h(M,I)=Hn. Стойкость (безопасность) хэш-функций. Один из основных методов криптоанализа хэш-функций заключается в проведении криптоаналитиком (противником) атаки, основанной на "парадоксе дня рождения", основные идеи которой, излагаются ниже. Для понимания сущности предлагаемого метода криптоанализа достаточно знать элементарную теорию вероятностей. Атака, основанная на "парадоксе дня рождения", заключается в следующем. Пусть a   Практически это означает, что в случайно подобранной группе из 24 человек вероятность наличия двух лиц с одним и тем же днем рождения составляет значение примерно 1/2. Этот старый и хорошо изученный парадокс и положен в основу криптоанализа хэш-функций. Например, для криптоанализа хэш-функций, основанных на использовании криптоалгоритма DES, указанная атака может быть проведена следующим образом. Пусть n - мощность области хэш-кодов (для криптоалгоритма DES она равна 264). Предположим, что есть две программы m1 и m2. Первая программа достоверна, а для второй криптоаналитик пытается получить то же самое значение хэш-кода, выдав таким образом программу m1 за программу m2 (то есть криптоаналитик пытается получить коллизию). Для этого криптоаналитик подготавливает порядка К основным методам предотвращения данной атаки можно отнести: увеличение длины получаемых хэш-кодов (увеличение мощности области хэш-кодов) и выполнение требования итерированности шифрующего преобразования. Методы построения криптографически стойких хэш-функций. Практические методы построения хэш- функций можно условно разделить на три группы: методы построения хэш-функций на основе какого-либо алгоритма шифрования (пример, приведенный выше), методы построения хэш-функций на основе какой-либо известной вычислительно трудной математической задачи и методы построения хэш-функций "с нуля" . Рассмотрим примеры построения хэш-функций на основе алгоритмов шифрования. Наряду с примером, приведенным выше, покажем, как строить хэш-функции на основе наиболее известных блочных шифров ГОСТ 28147 - 89, DES и FEAL. В качестве шифрующего преобразования будут использоваться некоторые режимы шифров ГОСТ 28147-89, DES и FEAL с ключом k. Тогда, чтобы получить хэш-код H программы M при помощи хэш-функции h, необходимо выполнить следующую итеративную операцию (например, с использованием алгоритма ГОСТ 28147-89):  Таким образом, хэш-кодом данной хэш-функции является значение H=h(M,I)=Hn. При этом используется режим выработки имитовставки ГОСТ 28147-89, а шифрующее преобразование 64-битных блоков заключается в выполнении 16 циклов алгоритма шифрования в режиме простой замены. Алгоритм ГОСТ 28147-89 в качестве базового используется в хэш-функции отечественного стандарта на функцию хэширования сообщений ГОСТ Р 34.11-94, являющегося основным практическим инструментом в компьютерных системах, требующих обеспечения достоверности и целостности электронных данных. Алгоритм DES (в режиме CFB) можно использовать в качестве базового, например, в следующей хэш-функции (с получением хэш-кода H=h(M,I)=Hn):  Другие примеры хэш-функций на основе алгоритмов шифрования. N-хэш алгоритм разработан фирмой Nippon Telephone Telegraph в 1990 году. N-хэш алгоритм использует блоки длиной 128 битов, шифрующую функцию, аналогичную функции алгоритма шифрования FEAL, и вырабатывает блок хэш-кода длиной 128 битов. На вход пошаговой хэш-функции в качестве аргументов поступают очередной блок кода Mi длиной 128 битов и хэш-код Hi-1 предыдущего шага также размером 128 битов. При этом H0=I, а Hi=Ek(Mi,Hi-1) Hi-1. Хэш- кодом всего кода программы объявляется хэш-код, получаемый в результате преобразования последнего блока текста.Идея использовать алгоритм блочного шифрования, стойкость которого общеизвестна, для построения надежных схем хэширования выглядит естественной. Однако для некоторых таких хэш-функций возникает следующая проблема. Предлагаемые методы могут требовать задания некоторого ключа, на котором происходит шифрование. В дальнейшем этот ключ необходимо держать в секрете, ибо противник, зная этот ключ и значение хэш-кода, может выполнить процедуру в обратном направлении. Еще одной слабостью указанных выше схем хэширования является то, что размер хэш-кода совпадает с размером блока алгоритма шифрования. Чаще всего размер блока недостаточен для того, чтобы схема была стойкой против атаки на основе "парадокса дня рождения". Поэтому были предприняты попытки построения хэш-функций на базе блочного шифра с размером хэш-кода в k раз (как правило, k=2) большим, чем размер блока алгоритма шифрования. В качестве примера можно привести хэш-функции MDC2 и MDC4 фирмы IBM. Данные хэш-функции используют блочный шифр (в оригинале DES) для получения хэш-кода, длина которого в два раза больше длины блока шифра. Алгоритм MDC2 работает несколько быстрее, чем MDC4, но представляется несколько менее стойким. Следует также отметить, что существует два основных режима применения хэш-функций: поточный и блочный. Выбор режима зависит от используемого в хэш-функции шифрующего преобразования. В качестве примера хэш-функций, построенных на основе вычислительно трудной математической задачи можно привести функцию из рекомендаций MKKTT X.509. Криптографическая стойкость данной функции основана на сложности решения следующей труднорешаемой теоретико-числовой задачи. Задача умножения двух больших (длиной в несколько сотен битов) простых чисел является простой с вычислительной точки зрения, в то время как факторизация (разложение на простые множители) полученного произведения является труднорешаемой задачей для указанных размерностей. Следует отметить, что задача разложения числа на простые множители эквивалентна следующей труднорешаемой математической задаче. Пусть n=pq произведение двух простых чисел p и q. В этом случае можно легко вычислить квадрат числа по модулю n: x2(mod n), однако вычислительно трудно извлечь квадратный корень по этому модулю. Таким образом, хэш-функцию МККТТ X.509 можно записать как:  длина блока Mi представляется в октетах, каждый октет разбит пополам и к каждой половине спереди приписывается полуоктет, состоящий из двоичных единиц; n - произведение двух больших (512-битных) простых чисел p и q. По-видимому, наиболее эффективными на сегодняшний день с точки зрения программной реализации и условий применения оказываются хэш-функции построенные "с нуля". Алгоритм MD4 (Message Digest) был разработан Р. Ривестом [,]. Размер вырабатываемого хэш-кода - 128 битов. По заявлениям самого разработчика при создании алгоритма он стремился достичь следующих целей: После того, как алгоритм был впервые опубликован, несколько криптоаналитиков построили коллизии для последних двух из трех раундов, используемых в MD4. Несмотря на то, что ни один из предложенных методов построения коллизий не приводит к успеху для полного MD4, автор усилил алгоритм и предложил новую схему хэширования MD5. Алгоритм MD5 является доработанной версией алгоритма MD4. Аналогично MD4, в алгоритме MD5 размер хэш-кода равен 128 битам. После ряда начальных действий MD5 разбивает текст на блоки длиной 512 битов, которые, в свою очередь, делятся на 16 подблоков по 32 бита. Выходом алгоритма являются 4 блока по 32 бита, конкатенация которых образует 128-битовый хэш-код. В 1993 году Национальный институт стандартов и технологий (NIST) США совместно с Агентством национальной безопасности США выпустил "Стандарт стойкой хэш-функции" (Secure Hash Standard), частью которого является алгоритм SHA. Предложенная процедура вырабатывает хэш-код длиной 160 битов для произвольного текста длиной менее 264 битов. Разработчики считают, что для SHA невозможно предложить алгоритм, имеющий разумную трудоемкость, который строил бы два различных набора данных, дающих один и тот же хэш-код (то есть алгоритм, находящий коллизии). Алгоритм SHA основан на тех же самых принципах, которые использовал Р. Ривест при разработке MD4, более того, алгоритмическая структура SHA очень похожа на структуру MD4. Процедура дополнения хэшируемого текста до кратного 512 битам полностью совпадает с процедурой дополнения алгоритма MD5. Обобщая вышесказанное, следует отметить, что при выборе практически стойких и высокоэффективных криптографических хэш-функций можно руководствоваться следующими эвристическими принципами: любой из известных алгоритмов построения коллизий не должен быть эффективнее метода, основанного на "парадоксе дня рождения"; алгоритм должен допускать эффективную программную реализацию на 32-разрядном процессоре; алгоритм не должен использовать сложных структур данных и подпрограмм; алгоритм должен быть оптимизирован с точки зрения его реализации на микропроцессорах типа Intel. Криптографические протоколы Базовым объектом исследований в криптологии являются криптографические протоколы. Криптографические протоколы относится к сравнительно новому направлению в криптографии, которое в последнее время переживает бурное развитие. В то же время, они являются весьма нетривиальным объектом исследований. Даже их формализация на сегодняшний день выглядит весьма затруднительной. Тем не менее, неформально под протоколом будем понимать распределенный алгоритм, т.е. совокупность алгоритмов для каждого из участников вычислений, плюс спецификации форматов сообщений, пересылаемых между участниками, плюс спецификации синхронизации действий участников, плюс описание действий при возникновении сбоев . Объектом изучения теории криптографических протоколов являются удаленные абоненты, взаимодействующие по открытым каналам связи. Целью взаимодействия абонентов является решение какой-то задачи.Имеется также противник, который преследует собственные цели. При этом противниками могут быть один или даже несколько абонентов, вступивших в сговор. Приведенная выше схема подписи с верификацией по запросу, а также схемы, представленные в разделе 2.4. есть не что иное, как сложные двухсторонние или многосторонние протоколы, которые используют, в том числе и криптографические примитивы. КриптопрограммированиеКриптопрограммирование посредством использования инкрементальных алгоритмов Одним из основных инструментов методологии криптопрограммирования являются инкрементальные алгоритмы. Цель инкрементальной криптографии заключается в разработке криптографических алгоритмов обработки электронных данных, обладающих следующим принципиальным свойством. Если алгоритм применяется к электронным данным D для достижения каких-либо их защитных свойств, то применение инкрементального алгоритма к данным D, подвергнувшихся модификации - D`, должно осуществляться быстрее, чем необходимость заново обработать данный документ. В тех приложениях, когда указанные алгоритмы являются, например, алгоритмами шифрования электронных документов или их цифровой подписи, требование повышения эффективности инкрементальных алгоритмов является крайне желательным. Один из основных методов применения инкрементальных алгоритмов заключается в использовании их аутентификационных признаков для антивирусной защиты. При обработке электронных документов инкрементальными алгоритмами рассматриваются такие операции обработки данных как "вставка" и "стирание" для символьных строк или "cut" - "вырезание и помещение в буфер" и "paste" - "извлечение из буфера и вставка" для текста. Основная задача здесь заключается в разработке эффективных инкрементальных алгоритмов для схем цифровой подписи и схем аутентификации сообщений, поддерживающих вышеупомянутые операции по модификации электронных данных. Такие алгоритмы должны обладать основным качественным свойством, а именно свойством "защиты от вмешательства", что, таким образом, и делает их применимыми для защиты программ от вирусов и других разрушающих программных средств. Основные криптографические примитивы, такие как шифрование и цифровая подпись имеют фундаментальную теоретическую базу. Во многих работах (см., например, обзор в работе []) были даны базовые определения их криптографической стойкости, основанные на обобщенных теоретико-сложностных и теоретико-информационных предположениях. Главная проблема, которая остается и затрудняет использование на практике многих доказуемо стойких теоретических криптоконструкций, заключается в их пространственно-временной неэффективности. Инкрементальность, в этом смысле, является новой мерой эффективности, которая является вполне приемлемой во многих алгоритмических приложениях. Пусть далее рассматривается процессор, защищенный от физического вмешательства, который имеет ограниченное количество безопасной локальной памяти. Необходимо получить доступ к файлам, находящихся на удаленных (возможно небезопасных) носителях, например, хост-станциях или www-серверах. Компьютерный вирус может атаковать удаленную станцию, и исследовать и изменять содержание удаленной информационной среды (но при этом он не имеет доступа к безопасной локальной памяти процессора). Для защиты файлов от таких вирусов, процессор вычисляет для каждого файла аутентификационный признак, как функцию от самого файла и ключа, который хранится в безопасной локальной памяти. Внедрение вируса в файл не позволяет ему заново вычислять признак, и при реализации процесса верификации признака, таким образом, обнаружится вторжение вируса. Следует обратить внимание на то, что для корректной верификации аутентификационного признака защищенный процессор должен заново подтвердить подлинность файлов. Ясно, что наиболее привлекательным способом является модернизация аутентификационного признака быстрее, чем необходимость его вычисления заново. Эта проблема особенно сложна в том случае, когда локальная память не достаточно большая для того, чтобы хранить (даже временно) фрагмент файла или когда "слишком дорого" ввести в локальную память полный файл. Идея инкрементальных алгоритмов, состоит в том, чтобы воспользоваться какими-либо имеющимися преимуществами такой организации программно-аппаратного взаимодействия и найти способы криптографических преобразований над электронными данными D не заново, а, скорее, как получение быстродействующей функции от значений криптографических преобразований над данными из которых D был получен. Когда "изменения" не велики, инкрементальные методы могут дать большие преимущества по эффективности. Основные элементы инкрементальной криптографии Примитивы. Инкрементальность можно рассматривать для любого криптографического примитива. В данном случае рассматриваются два из них - цифровая подпись и шифрование. Инкрементальность далее рассматривается, как правило, для "прямых" преобразованиях, а именно для генерации подписи и шифровании, но все рассуждения будут верны и для "сопряженных" преобразований, а именно для верификации подписи и дешифрования. Операторы модификации. Рассмотрим проблему модификации защищаемого файла в терминах применения фиксированного набора основных операций по модификации электронного документа. Например: замена блока в документе другим; вставка нового блока; удаление старого блока. Операции должны быть достаточно "мощны" для демонстрации реальных модификаций таких как: замена, вставка и удаление. Соответственно также рассматриваются операции "cut" и "paste", например, операции разбиения отдельного документа на два, а затем, вставка двух документов в один. Инкрементальные алгоритмы. Зафиксируем базовое криптографическое преобразование T (например, цифровая подпись документа с некоторым ключом). Каждой элементарной операции модификации текста (например, вставки) будет соответствовать инкрементальный алгоритм I. На вход этого алгоритма подаются: исходный файл; значения преобразования T на нем; описание модификаций; и возможно соответствующие ключи или другие параметры. Это позволит вычислить значение T для результирующего файла. Основная проблема здесь заключается в проектировании схем обработки файлов, обладающих эффективными инкрементальными алгоритмами. Предположим, что имеется подпись ?old для файла Dold и файл D'old, измененный посредством вставки в файл Dold некоторых данных. Необходимо получить подпись путем подписывания строки, состоящей из ?old и описания модификаций над документом Dold. Это схема называется схемой, зависящей от истории. Могут иметься приложения, когда такие действия являются приемлемыми. В большинстве же случаев это не желательно, так как делается большое количество изменений и затраты на верификацию подписи пропорциональны числу изменений. В связи с этим размеры подписи растут со временем. Чтобы избежать таких затрат необходимо использовать схемы, свободные от истории или HF-схемы. Все нижеприведенные схемы являются схемами, свободными от истории. Безопасность. Свойство инкрементальности вводит новые проблемы безопасности и вызывает необходимость новых определений. Рассмотрим случай схем подписи и аутентификации. Разумно предположить, что противник не только имеет доступ к предыдущим подписанным версиям фалов, но также способен выдавать команды на модификацию текста в существующих файлах и получать инкрементальные подписи для измененных файлов. Такая атака на основе выбранного сообщения для инкрементальных алгоритмов подписи может вести к "взлому" используемой схемы подписи, которая не может быть взломана при проведении противником других атак, в тех случаях, когда не используются инкрементальные алгоритмы. Кроме того, в некоторых сценариях, например, при вирусных атаках можно предположить, что противник вмешивается в содержание существующих документов и аутентификационных признаков, полученных посредством схем подписи/аутентификации. Соответственно рассматриваются два определения безопасности: базовое и более сильное понятие безопасности, когда доказывается стойкость защиты от вмешательств. Секретность инкрементальных схем. Исходя из вышесказанного, появляется новая проблема, которая проявляется в инкрементальном сценарии, а именно - проблема секретности различных версий файлов. Предположим ? - подпись кода М и ?' является подписью слегка измененного кода M'. Тогда, наилучшим вариантом было бы получить такую подпись ?', которая давала бы как можно меньше информации, об оригинальном коде М. Метод защиты файлов программ посредством инкрементального алгоритма маркирования Основные определения. Пусть АУТ(m) - обычный алгоритм аутентификации сообщений и АУТa(m)- функция маркирования сообщения m, индуцированная схемой АУТ с ключом аутентификации a. Пусть ВЕРa(m,?) - соответствующий алгоритм верификации, где ?={true, false} - предикат корректности проверки. Далее будут использоваться деревья поиска и, следовательно, необходимо напомнить, что 2-3-дерево имеет все концевые узлы (листья) на одном и том же самом уровне/высоте (как и в случае сбалансированных двоичных деревьев) и каждая внутренняя вершина имеет или 2, или З дочерних узла []. В данном случае 2-3-дерево подобно двоичному дереву является упорядоченным деревом и, таким образом, концевые узлы являются упорядоченными. Пусть Vh - определяет множество всех строк длины не больше h, ассоциированных очевидным способом с вершинами сбалансированного 2-3-дерева высоты h. Маркированное дерево может рассматриваться как функция Т: Vh - >{0,1}*, которая приписывает аутентификационный признак (АП) каждой вершине. Пусть совокупный аутентификационный признак файла F получен посредством использования 2-З-дерева аутентификационных признаков каждого из блоков файла F=F[1],...,F[l] (далее такое дерево будет называться маркированным деревом). Каждая вершина w ассоциирована с меткой, которая состоит из АП (аутентифицирующих дочерние узлы) и счетчика, представляющего число узлов в поддереве с корнем w. Алгоритм маркирования. Алгоритм создания 2-3-дерева аутентификационных признаков (алгоритм маркирования) работает следующим образом: для каждого i, пусть T(w)=АУТ?(F[i]), где w - i-тый концевой узел; для каждого не - концевого узла w, пусть Т(w)=АУТ?((L1,L2,L3),рзм), где Li - метка i-того дочернего узла w (в случае, если w имеет только два дочерних узла, то L3=?) и рзм - число узлов в поддереве с корнем w); для корня дерева Т(?)=АУТ?((L1,L2,L3),Id,счт), где Id - название документа и счт - соответствующее показание счетчика (связанное с этим документом). Инкрементальный алгоритм маркирования. Предположим, что файл F, аутентифицированный маркированным деревом, подвергается операции замены, то есть j-тый блок файла F заменен блоком F(?). Сначала необходимо проверить, что путь от требуемого текущего значения до корня дерева корректен. Для этого необходимо выполнить следующий алгоритм. Пусть u0,...uh - путь из корня u0=? к j-тому концевому узлу обозначается как uh. Тогда: проверить, что ВЕР? принимает Т(?) как корректный АП строки Т(?)=АУТa((L1,L2,L3),Id,счт), где Id - название документа и счт - текущее значение счетчика (связанного с этим документом); для i=1,...,h-1 проверить, что ВЕР? принимает Т(ui) как корректный АП строки ((L1,L2,L3),рзм), где Li - метка i-того дочернего узла w (в случае, если w имеет только два дочерних узла, то L3=?) и рзм - число узлов в поддереве с корнем w)); проверить, что ВЕР? принимает Т(uh) как корректный АП блока F[j] . Если все эти проверки успешны, тогда совокупный АП файла F получается следующим образом: установить Т(uh):=АУТ(F(?)); для i=h-1,...,1 установить Т(ui):=АУТ(Т(ui1),Т(ui2),Т(ui3)); установить Т(?):=АУТ((Т(ui0),Т(ui1),Т(ui1)),Id,счт+1). Следует подчеркнуть, что значения Т на всех других вершинах (то есть, не стоящих на пути u0,...,uh) остаются неизменяемыми. Следует отметить, что предлагаемая инкрементальная схема маркирования имеет дополнительное свойство, заключающееся в том, что она безопасна даже для противника который может "видеть" как отдельные аутентификационные признаки, так и все маркированное дерево и может даже "вмешиваться" в эти признаки. Для каждого файла, пользователь должен хранить в локальной безопасной памяти ключ x схемы подписи, имя файла и текущее значение счетчика. Всякий раз, когда пользователь хочет проверить целостность файла, он проверяет корректность маркированного дерева открытым образом. Наиболее эффективным является использование инкрементального алгоритма маркирования для защиты программ, использующих постоянно обновляющие структуры данных, например, файл с исходными данными или итерационно изменяемыми переменными. ЛитератураАбрамов С.А. Элементы анализа программ. Частичные функции на множестве состояний. - М.: Наука, 1986. Ахо А., Хопкрофт Дж., Ульман Дж. Построение и анализ вычислительных алгоритмов. - М.: Мир, 1979. Безруков Н.Н. Компьютерная вирусология// Справ. - Киев: Издательство УРЕ, 1991. Беневольский С.В., Бетанов В.В. Контроль правильности расчета параметров траектории сложных динамических объектов на основе алгоритмической избыточности// Вопросы защиты информации. - 1996.- №2.- С.66-69. Белкин П.Ю. Новое поколение вирусов принципы работы и методы защиты// Защита информации. - 1997.- №2.-С.35-40. Варновский Н.П. Криптографические протоколы// В кн. Введение в криптографию/ Под. Общ. Ред. В.В. Ященко М.: МЦНМО, "ЧеРо", 1998. Вербицкий О.В. О возможности проведения любого интерактивного доказательства за ограниченное число раундов// Известия академии наук. Серия математическая. - 1993. - Том 57. - №3. - С.152-178. Герасименко В.А. Защита информации в АСОД.- М.: Энергоиздат, 1994. ГОСТ 28147-89. Системы обработки информации. Защита криптографическая. Алгоритм криптографического преобразования. ГОСТ Р 34.10-94. Информационная технология. Криптографическая защита информации. Процедуры выработки и проверки электронной цифровой подписи на базе асимметричного криптографического алгоритма. ГОСТ Р 34.11-94. Информационная технология. Криптографическая защита информации. Функция хэширования. Дал У., Дейкстра Э., Хоор К. Структурное программирование/ М.: Мир, 1975. Гэри М., Джонсон Д. Вычислительные машины и труднорешаемые задачи. М.: Мир, 1982. Дейкстра Э.В. Смиренный программист// В кн. Лекции лауреатов премии Тьюринга за первые 20 лет 1966-1985.- М.: Мир, 1993. Защита программного обеспечения: Пер. с англ./ Д. Гроувер, Р. Сатер, Дж. Фипс и др./ Под редакцией Д. Гроувера.- М.: Мир, 1992. Зегжда Д., Мешков А., Семьянов П., Шведов Д. Как противостоять вирусной атаке. - CПб.: BHV-Санкт-Петербург, 1995. Зегжда Д.П., Шмаков Э.М. Проблема анализа безопасности программного обеспечения// Безопасность информационных технологий. - 1995.- №2.- С.28-33. Зима В.М., Молдовян А.А., Молдовян Н.А. Защита компьютерных ресурсов от несанкционированных действий пользователей. - Учеб пособие. - СПб: Издательство ВИКА им. А.Ф. Можайского, 1997. Ефимов А.И., Пальчун Б.П. О технологической безопасности компьютерной инфосферы// Вопросы защиты информации. - 1995.- №3(30).-С.86-88. Ефимов А.И. Проблема технологической безопасности программного обеспечения систем вооружения// Безопасность информационных технологий. - 1994.- №3-4.- С.22-33. Ефимов А.И., Ухлинов Л.М. Методика расчета вероятности наличия дефектов диверсионного типа на этапе испытаний программного обеспечения вычислительных задач// Вопросы защиты информации. - 1995.- №3(30).-С.86-88. Ефимов А.И., Пальчун Б.П., Ухлинов Л.М. Методика построения тестов проверки технологической безопасности инструментальных средств автоматизации программирования на основе их функциональных диаграмм// Вопросы защиты информации. - 1995.- №3(30).-С.52-54. Казарин О.В. Самотестирующиеся и самокорректирующиеся программы для систем защиты информации// В кн.: Тезисы докл. конференции "Методы и средства обеспечения безопасности информации", С.- Петербург. - 1996.- С.93-94. Казарин О.В. О создании информационных технологий, исходно ориентированных на разработку безопасного программного обеспечения// Вопросы защиты информации. - 1997. - №№1-2 (36-37). - С.9-10. Казарин О.В. Два подхода к созданию программного обеспечения на базе алгоритмически безопасных процедур// Безопасность информационных технологий.-1997.-№3.- С.39-40. Казарин О.В. Основные принципы построения самотестирующихся и самокорректирующихся программ// Вопросы защиты информации. - 1997. - №№1-2 (36-37). - С.12-14. Казарин О.В. Конвертируемые и селективно конвертируемые схемы подписи с верификацией по запросу// Автоматика и телемеханика. - 1998. - №6. - С.178-188. Казарин О.В., Лагутин В.С., Петраков А.В. Защита достоверных цифровых электрорадиосообщений. - М.: РИО МТУСИ, 1997 Казарин О.В., Ухлинов Л.М. Интерактивная система доказательств для интеллектуальных средств контроля доступа к информационно - вычислительным ресурсам// Автоматика и телемеханика. - 1993.- №11.- С.167-175. Казарин О.В., Ухлинов Л.М. Новые схемы цифровой подписи на основе отечественного стандарта// Защита информации. - 1995.- №5.- С.52-56. Казарин О.В., Ухлинов Л.М. Принципы создания самотестирующейся / самокорректирующей программной пары для некоторых схем защиты информации// Тезисы докладов Международной конференции IT+SE'97, Украина, Ялта, 15-24 мая 1997. - С.109-111. Казарин О.В., Ухлинов Л.М. К вопросу о создании безопасного программного обеспечения на базе методов конфиденциального вычисления функции// Тезисы докладов Международной конференции - IP+NN'97, Украина, Ялта, 10-17 октября 1997. - C.3-6. Казарин О.В., Скиба В.Ю. Об одном методе верификации расчетных программ// Безопасность информационных технологий.-1997.-№3.-С.40-43. Кнут Д. Искусство программирования для ЭВМ. Том 2.: Мир, 1976. Лагутин В.С., Петраков А.В. Утечка и защита информации в телефонных каналах. - М.: Энергоатомиздат, 1998. Липаев В.В. Управление разработкой программных средств. - М.: Финансы и статистика, 1993. Липаев В.В., Позин Б.А., Штрик А.А. Технология сборочного программирования. - М.: Радио и связь, 1992. Липаев В.В. Сертификация информационных технологий программных средств и баз данных. Методы и стандарты. - Казань: Издательство ЦНИТ РТ, 1995. Надежность и эффективность в технике (в 10-ти томах). Справочник. - М.: Машиностроение, 1989. Организация и современные методы защиты информации (под общей редакцией Диева С.А., Шаваева А.Г.). - М.: Концерн "Банковский деловой центр", 1998. Пальчун Б.П. Проблема взаимосвязи надежности и безопасности информации// В кн.: Тезисы докл. конференции "Методы и средства обеспечения безопасности информации", С.-Петербург. - 1996.- С.184-185. Петраков А.В. Защита и охрана личности, собственности, информации. М.: Радио и связь, 1997. Петраков А.В., Лагутин В.С. Телеохрана. М.: Энергоатомиздат, 1998. Пальчун Б.П., Юсупов Р.М. Оценка надежности программного обеспечения. - СПб.: Наука, 1994. Проблемы безопасности программного обеспечения. Под ред. П.Д. Зегжда. - СПб.: Издательство СПбГТУ, 1995. Правиков Д.И., Чибисов В.Н. Об одном подходе к поиску программных закладок// Безопасность информационных технологий. - 1995.- №1.- С.76-79. Расторгуев С.П., Дмитриевский Н.Н. Искусство защиты и "раздевания" программ. М.: Издательство "Совмаркет", 1991. Руководящий документ. Концепция защиты средств вычислительной техники и автоматизированных систем от НСД к информации. М.: Гостехкомиссия России, 1992. Руководящий документ. Защита от несанкционированного доступа к информации. Термины и определения. М.: Гостехкомиссия России, 1992. Руководящий документ. Автоматизированные системы. Защита от НСД к информации. Классификация АС и требования по защите информации. М.: Гостехкомиссия России, 1992. Руководящий документ. Средства вычислительной техники. Защита от несанкционированного доступа к информации. Показатели защищенности от НСД к информации. М.: Гостехкомиссия России, 1992. Руководящий документ. Временное положение по организации разработки, изготовления и эксплуатации программных и технических средств защиты информации от НСД в автоматизированных системах и средствах вычислительной техники. М.: Гостехкомиссия России, 1992. Руководящий документ. Средства вычислительной техники. Межсетевые экраны. Защита от несанкционированного доступа к информации. Показатели защищенности от НСД к информации. М.: Гостехкомиссия России, 1997. Стенг Д., Мун С. Секреты безопасности сетей. - К.: "Диалектика", 1995. Сырков Б. Компьютерная преступность в России. Современное состояние// Системы безопасности связи и телекоммуникаций. - 1998. - №21. - С.70-72. Тейер Т., Липов М., Нельсон Э. Надежность программного обеспечения. - М.: Мир, 1981. Томпсон К. Размышления о том, можно ли полагаться на доверие// В кн. Лекции лауреатов премии Тьюринга за первые 20 лет 1966-1985.- М.: Мир, 1993. Ухлинов Л.М., Казарин О.В. Методология защиты информации в условиях конверсии военного производства// Вестник РОИВТ.- 1994.- №1-2.- С.54-60. Файтс Ф., Джонсон П., Кратц М. Компьютерный вирус: проблемы и прогноз. - М.: Мир, 1994. Щербаков А. Разрушающие программные воздействия. - М.: ЭДЕЛЬ, 1993. Ben-Or M., Canetti R., Goldreich O. Asynchronous secure computation// Proc 25th ACM Symposium on Theory of Computing. - 1993. - P.52-61. Blum M., Luby M., Rubinfeld R. Self-testing/ correcting with applications to numerical problems// Proc 22th ACM Symposium on Theory of Computing. - 1990. - P.73-83. Blum M., Kannan S. Designing programs that check their work// Proc 21th ACM Symposium on Theory of Computing. - 1989. - P.86-97. Buell D.A., Ward R.L. A multiprecise arithmetic package// J.Supercomput. - 1989. - V.3. - №2. - P.89-107. Cohen F. Computer viruses: Theory and experiments// Proceedings of the 7th National Computer Security Conference. - 1984. Hunter D.G.N. RSA key calculations in ADA// The Comp.J. - 1985. - V.28. - №3. - P.343-348. Micali S., Rogaway Ph. Secure computation// Advances in Cryptology - CRYPTO'91, Proceedings, Springer-Verlag LNCS, V.576. - 1992. - P.392-404. Rivest R. The MD4 message digest algorithm// RFC 1186, October, 1990. Rivest R. The MD5 message digest algorithm// RFC 1321, April, 1992. Rivest R.L., Shamir A., Adleman L. A method for obtaining digital signatures and public-key cryptosystems// Communication of the ACM.- 1978.- V.21.- №2.- P.120-126. Логико-аналитические методы контроля безопасности программПри проведении анализа безопасности с помощью логико-аналитических методов (см. рис.2.5) строится модель программы и формально доказывается эквивалентность модели исследуемой программы и модели РПС. В простейшем случае в качестве модели программы может выступать ее битовый образ, в качестве моделей вирусов множество их сигнатур, а доказательство эквивалентности состоит в поиске сигнатур вирусов в программе. Более сложные методы используют формальные модели, основанные на совокупности признаков, свойственных той или иной группе РПС. Формальная постановка задачи анализа безопасности логико-аналитическими методами может быть сформулирована следующим образом.
Рис.2.4. Схема анализа безопасности ПО с помощью контрольно-испытательных методов
Рис. 2.5. Схема анализа безопасности ПО с помощью логико-аналитических методов Выбирается некоторая система моделирования программ, представленная множеством моделей всех программ - Z. В выбранной системе исследуемая программа представляется своей моделью М, принадлежащей множеству Z. Должно быть задано множество моделей РПС V={vi|i=1,...,N}, полученное либо путем построения моделей всех известных РПС, либо путем порождения множества моделей всех возможных (в рамках данной модели) РПС. Множество V является подмножеством множества Z. Кроме того, должно быть задано отношение эквивалентности определяющее наличие РПС в модели программы, обозначим его Е(x,y). Это отношение выражает тождественность программы x и РПС y, где x - модель программы, y - модель РПС, и y принадлежит множеству V. Тогда задача анализа безопасности сводится к доказательству того, что модель исследуемой программы М принадлежит отношению E(M,v), где v принадлежит множеству V. Для проведения логико-аналитического анализа безопасности про-граммы необходимо, во-первых, выбрать способ представления и получения моделей программы и РПС. После этого необходимо построить модель исследуемой программы и попытаться доказать ее принадлежность к отношению эквивалентности, задающему множество РПС. На основании полученных результатов можно сделать заключение о степени безопасности программы. Ключевыми понятиями здесь являются "способ представления" и "модель программы". Дело в том, что на ком-пьютерную программу можно смотреть с очень многих точек зрения - это и алгоритм, который она реализует, и последовательность команд процессора, и файл, содержащий последовательность байтов и т.д. Все эти понятия образуют иерархию моделей компьютерных программ. Можно вы-брать модель любого уровня модели и способ ее представления, необхо-димо только чтобы модель РПС и программы были заданы одним и тем же способом, с использованием понятий одного уровня. Другой серьезной проблемой является создание формальных моделей программ, или хотя бы определенных классов РПС. Механизм задания отношения между программой и РПС определяется способом представления модели. Наиболее перспективным здесь представляется использование семантических графов и объектно-ориентированных моделей. В целом полный процесс анализа ПО включает в себя три вида анали-за: лексический верификационный анализ; синтаксический верификационный анализ; семантический анализ программ. Каждый из видов анализа представляет собой законченное исследование программ согласно своей специализации. Результаты исследования могут иметь как самостоятельное значение, так и коррелироваться с результатами полного процесса анализа. Лексический верификационный анализ предполагает поиск распознавания и классификацию различных лексем объекта исследования (программа), представленного в исполняемых кодах. При этом лексемами являются сигнатуры. В данном случае осуществляется поиск сигнатур следующих классов: сигнатуры вирусов; сигнатуры элементов РПС; сигнатуры (лексемы) "подозрительных функций"; сигнатуры штатных процедур использования системных ресурсов и внешних устройств. Поиск лексем (сигнатур) реализуется с помощью специальных про-грамм-сканеров. Синтаксический верификационный анализ предполагает поиск, распознавание и классификацию синтаксических структур РПС, а также по-строение структурно-алгоритмической модели самой программы. Решение задач поиска и распознавания синтаксических структур РПС имеет самостоятельное значение для верификационного анализа программ, поскольку позволяет осуществлять поиск элементов РПС, не имеющих сигнатуры. Структурно-алгоритмическая модель программы необходима для реализации следующего вида анализа - семантического. Семантический анализ предполагает исследование программы изучения смысла составляющих ее функций (процедур) в аспекте операционной среды компьютерной системы. В отличие от предыдущих видов анализа, основанных на статическом исследовании, семантический анализ нацелен на изучение динамики программы - ее взаимодействия с окружающей средой. Процесс исследования осуществляется в виртуальной операционной среде с полным контролем действий программы и отслеживанием алгоритма ее работы по структурно-алгоритмической модели. Семантический анализ является наиболее эффективным видом анализа, но и самым трудоемким. По этой причине методика сочетает в себе три перечисленных выше анализа. Выработанные критерии позволяют разумно сочетать различные виды анализа, существенно сокращая время исследования, не снижая его качества. Методы и средства анализа безопасности программного обеспеченияШироко известны различные средства программного обеспечения обнаружения элементов РПС - от простейших антивирусных программ-сканеров до сложных отладчиков и дизассемблеров - анализаторов и именно на базе этих средств и выработался набор методов, которыми осуществляется анализ безопасности ПО. Авторы работ ,] предлагают разделить методы, используемые для анализа и оценки безопасности ПО, на две категории: контрольно-испытательные и логико-аналитические (см. рис.2.3). В основу данного разделения положены принципиальные различия в точке зрения на исследуемый объект (программу). Контрольно-испытательные методы анализа рассматривают РПС через призму фиксации факта нарушения безопасного состояния системы, а логико-аналитические - через призму доказательства наличия отношения эквивалентности между моделью исследуемой программы и моделью РПС. В такой классификации тип используемых для анализа средств не принимается во внимание - в этом ее преимущество по сравнению, например, с разделением на статический и динамический анализ. Комплексная система исследования безопасности ПО должна вклю-чать как контрольно-испытательные, так и логико-аналитические методы анализа, используя преимущества каждого их них. С методической точки зрения логико-аналитические методы выглядят более предпочтительными, т.к. позволяют оценить надежность полученных результатов и проследить последовательность (путем обратных рассуждений) их получения. Однако эти методы пока еще мало развиты и, несомненно, более трудоемки, чем контрольно-испытательные. Методы обеспечения надежности программ для контроля их технологической безопасностиПри исследовании методов и средств оценки уровня технологической безопасности программных комплексов учитываются факторы, имеющие, как правило, чисто случайный характер. Следовательно, показатели, связанные с оцениванием безопасности ПО лучше всего выражать вероятностной мерой, а для их вычисления можно использовать вероятностные модели надежности ПО , которые при осуществлении замены условия правильности функционирования программ на условие их безопасности можно использовать для этих целей. Исходные данные, определения и условия В данном разделе будем считать, что безопасность программного обеспечения - это вероятность того, что преднамеренные программные дефекты, вызывающие критическое поведение управляемой КС, будут обнаружены при определенных условиями внешней среды и в течение заданного периода наблюдения при испытаниях. Под определенными условиями внешней среды следует понимать описание входных данных и состояние вычислительного процесса в момент выполнения программы при испытаниях. Под заданным периодом функционирования понимается время, необходимое для выполнения поставленной задачи. Выделение определенного интервала времени целесообразно в случае систем реального времени, в которых неопределенными являются количество прогонов любой из действующих программ, состояние баз данных и моменты выполнения той или иной программы. В условиях, когда состояние программы достоверно известно в качестве периода наблюдений следует выбрать рабочий цикл или прогон. В любом случае перед каждым повторным выполнением программы необходимо либо восстанавливать состояние памяти , либо осуществлять серию последовательных прогонов, при котором последовательным образом изменяется состояние базы данных. Интуитивное определение безопасности ПО может быть уточнено в статистическом смысле на основе следующих простых соображений: машинная программа p может быть определена как описание некоторой вычислимой функции F на множестве E всех значений наборов входных данных, таких что каждый элемент Ei множества E представляет собой набор значений данных, необходимый для выполнения прогона программы: E=(Ei:i=1,2,...,N); выполнение программы p приводит к получению для каждого Ei определенного значения функции F(Ei); множество E определяет все возможные вычисления в программе p, то есть каждому набору входных данных Ei соответствует прогон программы p, и наоборот, каждому прогону соответствует некоторый набор входных данных Ei; наличие дефектов в программе p приводит к тому, что ей на самом деле соответствует функция F', отличная от заданной функции F; для некоторого Ei отклонение выхода F'(Ei), полученного в результате выполнения программы не должно превышать уровень безопасности программного обеспечения S(Ei), то есть безопасность обеспечивается при соблюдении ограничения: F'(Ei), S(Ei). (Вопрос о том, приводит ли некоторое отклонение выхода к нарушению условия безопасности, должен решаться в каждом конкретном случае отдельно, поскольку все определяется конкретными особенностями поведения системы после нарушения ее работы) . Совокупность действий, включающая ввод Ei, выполнение программы p, которое заканчивается получением результата F'(Ei) называется прогоном программы p. Необходимо также отметить, что значения входных переменных, образующие Ei, не должны все одновременно подаваться на вход программ p. Таким образом, вероятность P того, что прогон программы приведет к обнаружению дефекта, равна вероятности того, что набор данных Ei, используемый в данном прогоне, принадлежит множеству Ee. Если обозначить через ne число различных наборов значений входных данных, содержащихся в Ee, то P=ne/N - есть вероятность того, что прогон программы на наборе входных данных Ei, случайно выбранном из E среди равновероятных, закончится обнаружением дефекта. При этом R=1-P - есть вероятность того, что прогон программы p на наборе входных данных Ei, случайно выбранном из E среди априорно равновероятных, приведет к получению приемлемого результата. Однако в процесс функционирования программы выбор входных данных из E обычно осуществляется не с одинаковыми априорными вероятностями, а диктуется определенными условиями работы. Определение множества E входных массивов. Выделение в E подмножеств Gj, связанных с отдельными ветвями программы. Определение для каждого Gj в предполагаемых условиях функционирования значений вероятности Pj. Определение подмножества Gj для каждого входного набора данных, используемого в контрольных примерах. Выявление проверенных пар и непроверенных в ходе испытаний сегментов и пар сегментов. Определение для каждого j величины P'=ajPj, где aj определяется в соответствии со следующими правилами . aj=0,99, если подмножество Gj включает более одного контрольного примера; aj=0,95, если подмножество Gj включает ровно один контрольный пример; aj=0,90, если подмножество Gj не включает ни одного контрольного примера, но в процессе проверки программы были найдены все сегменты и все сегментные пары ветви Lj; aj=0,80, если в ходе испытаний были опробованы все сегменты, но не все сегментные пары; aj=0,80-0,20m, если m сегментов (1 4) ветви Lj не были опробованы в ходе испытаний; aj=0, если более чем 4 сегмента не были опробованы в процессе испытаний. Вычисление грубой оценки R" осуществляется по формуле  Приведенные выше параметры aj были определены интуитивно на основе анализа теоретических результатов исследования и экспериментальных результатов тестирования различных программ. Для того, чтобы получить более точные оценки величины R необходимо провести измерения с использованием подходящего метода формирования выборки. Оценка технологической безопасности ПО осуществляется посредством проверки условия R" Эти условия характеризуются некоторым распределением вероятностей pi, того, что будет выбран набор входных данных Ei. Распределение P может быть определено через pi с помощью величины yi, которая принимает значение 0, если прогон программы на наборе Ei заканчивается вычислением приемлемого значения функции, и значением 1, если этот прогон заканчивается обнаружением дефекта. Поэтому  Введем также определения и обозначения, связывающие структурные характеристики программ с их безопасностью. Структурными характеристиками программы p являются множество ветвей Lj (j=1,...,n), подмножества входных наборов данных Gj, соответствующие ветвям Lj, множества сегментов Segj, из которых состоят отдельные ветви, совокупность операторов ветвления, которые обеспечивают переход от одного сегмента к другому при движении по отдельной ветви программы. Оценка технологической безопасности программ на базе метода Нельсона Перед тем как перейти непосредственно к методу оценки, необходимо сделать несколько замечаний. Следует заметить, что реальные условия испытаний программ всегда существенно отличаются от тех, которые требуются для представительного измерения уровня безопасности ПО. Так, например, тестовые прогоны выполняются на входных наборах данных, выбранных не совсем случайным, а выбранных некоторым определенным образом: обычно выбор производится так, чтобы соответствующую ошибку можно было найти как можно быстрее. При этом выбор основывается на опыте и интуиции испытателей, либо осуществляется с учетом функциональных возможностей, которые должна обеспечивать программа, или возможностей соответствующих методик испытаний. Поэтому контрольные примеры, как правило, не являются представительными с точки зрения моделирования реальных условий работы программы и далее описывается процедура грубой оценки величины R, предусматривающая использование результатов испытаний и включающая следующие шаги: Методы противодействия динамическим способам снятия защиты программ от копированияНабор методов противодействия динамическим способам снятия защиты программ от копирования включает следующие методы . Периодический подсчет контрольной суммы, занимаемой образом задачи области оперативной памяти, в процессе выполнения. Это позволяет: заметить изменения, внесенные в загрузочный модуль; в случае, если программу пытаются "раздеть", выявить контрольные точки, установленные отладчиком. Проверка количества свободной памяти и сравнение и с тем объемом, к которому задача "привыкла" или "приучена". Это действия позволит застраховаться от слишком грубой слежки за программой с помощью резидентных модулей. Проверка содержимого незадействованных для решения защищаемой программы областей памяти, которые не попадают под общее распределение оперативной памяти, доступной для программиста, что позволяет добиться "монопольного" режима работы программы. Проверка содержимого векторов прерываний (особенно 13h и 21h) на наличие тех значений, к которым задача "приучена". Иногда бывает полезным сравнение первых команд операционной системы, отрабатывающих этим прерывания, с теми командами, которые там должны быть. Вместе с предварительной очисткой оперативной памяти проверка векторов прерываний и их принудительное восстановление позволяет избавиться от большинства присутствующих в памяти резидентных программ. Переустановка векторов прерываний. Содержимое некоторых векторов прерываний (например, 13h и 21h) копируется в область свободных векторов. Соответственно изменяются и обращения к прерываниям. При этом слежение за известными векторами не даст желаемого результата. Например, самыми первыми исполняемыми командами программы копируется содержимое вектора 21h (4 байта) в вектор 60h, а вместо команд int 21h в программе везде записывается команда int 60h. В результате в явном виде в тексте программы нет ни одной команды работы с прерыванием 21h. Постоянное чередование команд разрешения и запрещения прерывания, что затрудняет установку отладчиком контрольных точек. Контроль времени выполнения отдельных частей программы, что позволяет выявить "остановы" в теле исполняемого модуля. Многие перечисленные защитные средства могут быть реализованы исключительно на языке Ассемблер. Одна из основных отличительных особенностей этого языка заключается в том, что для него не существует ограничений в области работы со стеком, регистрами, памятью, портами ввода/вывода и т.п. Автокорреляция представляет значительный интерес, поскольку дает некоторую числовую характеристику программы. По всей вероятности автокорреляционные функции различного типа можно использовать и тестировании программ на технологическую безопасность, когда разработанную программу еще не с чем сравнивать на подобие с целью обнаружения программных дефектов. Таким образом, программы имеют целую иерархию структур, которые могут быть выявлены, измерены и использованы в качестве характеристик последовательности данных. При этом в ходе тестирования, измерения не должны зависеть от типа данных, хотя данные, имеющие структуру программы, должны обладать специфическими параметрами, позволяющими указать меру распознавания программы. Поэтому указанные методы позволяют в определенной мере выявить те изменения в программе, которые вносятся нарушителем либо в результате преднамеренной маскировки, либо преобразованием некоторых функций программы, либо включением модуля, характеристики которого отличаются от характеристик программы, а также позволяют оценить степень обеспечения безопасности программ при внесении программных закладок. Методы создания самотестирующихсяТаким образом, самотестирование должно лишь незначительно замедлять время выполнения программы P. Самокорректирующаяся программа это вероятностная программа Cf, которая помогает программе P скорректировать саму себя, если только P выдает корректный результат с низкой вероятностью ошибки, то есть для любого x, Cf вызывает программу P для корректного вычисления f(x), в то время как собственно сама P обладает низкой вероятностью ошибки. Самотестирующейся/самокорректирующейся программной парой называется пара программ вида (Tf,Cf). Предположим пользователь может взять любую программу P, которая целенаправленно вычисляет f и тестирует саму себя при помощи программы Tf. Если P проходит такие тесты, тогда по любому x, пользователь может вызвать программу Cf, которая, в свою очередь, вызывает P для корректного вычисления f(x). Даже если программа P, которая вычисляет значение функции f некорректно для некоторой небольшой доли входных значений, ее в данном случае все равно можно уверенно использовать для корректного вычисления f(x) для любого x. Кроме того, если удастся в будущем написать программу P' для вычисления f, тогда некоторая пара (Tf,Cf) может использоваться для самотестирования и самокоррекции P' без какой-либо ее модификации. Таким образом, имеет смысл тратить определенное количество времени для разработки самотестирующейся/ самокорректирующейся программной пары для прикладных вычислительных функций. Перед тем как перейти к более формальному описанию определений самотестирующихся и самокорректирующихся программ необходимо дать определение вероятностной оракульной программе (по аналогии с вероятностной оракульной машиной Тьюринга). Вероятностная программа M является вероятностной оракульной программой, если она может вызывать другую программу, которая является исполнимой во время выполнения M. Обозначение MA означает, что M может делать вызовы программы A. Пусть P - программа, которая предположительно вычисляет функцию f. Пусть I является объединением подмножеств In, где n принадлежит множеству натуральных чисел N и пусть Dp={Dn|n Далее, пусть err(P,f,Dn) это вероятность того, что P(x) - если err(P,f,Dn) - если err(P,f,Dn) Оракульная программа Cf с параметром 0 (?1,?2,?)-самотестирующейся/ самокорректирующейся программной парой для функции f называется пара вероятностных программ (Tf,Cf) такая, что существуют константы 0 Свойство случайной самосводимости. Пусть x Метод создания самотестирующейся расчетной программы с эффективным тестирующим модулем В качестве расчетной программы рассматривается любая программа, решающая задачу получения значения некоторой вычислимой функции. При этом под верификацией расчетной программы понимается процесс доказательства того, что программа будет получать на некотором входе истинные значения исследуемой функции. Иными словами, верификация расчетной программы направлена на доказательство отсутствия преднамеренных и (или) непреднамеренных программных дефектов в верифици-руемой программе. В данном случае предлагается метод создания самотестирующихся программ для верификации расчетных программных модулей . Данный метод не требует вычисления эталонных значений и является независимым от используемого при написании расчетной программы языка программи-рования, что существенно повышает оперативность исследования программы и точность оценки вероятности отсутствия в ней программных де-фектов. Следует в то же время отметить, что предположительно предлагаемый метод можно использовать для программ, вычисляющих функции особого вида, а именно функции, обладающие свойством случайной само-сводимости. Пусть для функции Y = f (X) существует пара функций (gc, hc)Y таких, что: Y = gc (f (a1), ..., f (ac)), X = hc (a1, ..., ac). Легко увидеть, что если значения ai выбраны из In в соответствии с распределением Dp, тогда пара функций (gc, hc)Y обеспечивает выполнение для функции Y = f (X) свойства случайной самосводимости. Пару функций (gc, hc)Y будем называть ST-парой функций для функции Y = f (X). Метод верификации расчетных программ на основе ST-пары функций. Предположим, что на ST-пару функций можно наложить некоторую совокупность ограничений на сложность программной реализации и время выполнения. В этом случае, пусть длина кода программ, реализующих функции gc и hc , и время их выполнения составляет константный мультип-ликативный фактор от длины кода и времени выполнения программы P. Предлагаемый метод верификации расчетной программы P на основе ST-пары функций для некоторого входного значения вектора X* заключа-ется в выполнении следующего алгоритма. (Всюду далее, если осуществ-ляется случайный выбор значений, этот выбор выполняется в соответствии с распределением вероятностей Dp). Алгоритм ST Определить множество A*={a1*,...,ac*} такое, что X*=hc{a1*,...,ac*} , где a1*,...,ac* выбраны случайно из входного подмножества In. Вызвать программу P для вычисления значения Y0*=f(X*) Вызвать c раз программу P для вычисления множества значений {f(a1*),...,f(ac*)} Определить значения Y1*=gc{f(a1*) ,...,f(ac*)} Если Y0*=Y1* , то принимается решение, что программа P корректна на множестве значений входных параметров {X*,a1*,...,ac*} в противном случае данная программа является некорректной. Таким образом, данный метод не требует вычисления эталонных значений и за одну итерацию позволяет верифицировать корректность программы P на (n+1) значении входных параметров. При этом время верификации можно оценить как где ti и tx - время выполнения программы P при входных значениях ai и X* соответственно; tg и th-1 - время определения значения функции gc и множества A* соответственно: TP (X) - временная (не асимптотическая) сложность выполнения программы P; Kgh (X, c)- коэффициент временной сложности программной реализации функции gc и определения A* по отношению ко временной сложности программы P (по предположению он составляет константный мульти-пликативный фактор от TP (X), а его значение меньше 1). Для традиционного вышеуказанного метода тестирования время выполнения и сравнения полученного результата с эталонным значением составляет:
где tie и txe - время определения эталонных значений функции Y = f (X) при значениях ai и X* соответственно (в общем случае, не может быть меньше времени выполнения программы). Следовательно, относительный выигрыш по оперативности предложенного метода верификации (по отношению к методу тестирования программ на основе ее эталонных значений):
Так как, коэффициент Kgh < 1, а c Исследования процесса верификации расчетных программ В качестве примера работоспособности предложенного метода рассмотрим верификацию программы вычисления функции дискретного возведения в степень: y = fAM (x) = Ax modulo M. Выбор данной функции обусловлен тем, что она является одной из основных функций в различных теоретико-числовых конструкциях, например, в схемах электронной цифровой подписи, системах открытого распределения ключей и т.п. Это, в свою очередь, демонстрирует возможность применения предложенного метода при исследовании расчетных программ, решающих конкретные прикладные задачи. Кроме того, очевидно, что данная функция обладает свойством случайной самосводимо-сти, а исходя из результатов работы можно показать, что для данной функции существует (1/288, 1/8)-самотестирующаяся программа. Для экспериментальных исследований была выбрана программа EXP из библиотеки базовых криптографических функций CRYPTOOLS , которая реализует функцию дискретного возведения в степень (размерность переменных и констант не превышает 64 байтов). Была разработана интегрированная оболочка для проведения верификации, включающая ин-терфейс с пользователем и программные процедуры, реализующие некоторую совокупность проверочных тестов. Экспериментальные исследования состояли из определения временных характеристик процесса верифи-кации на основе использования ST-пары функций и определения возмож-ности обнаружения предложенным методом преднамеренно внесенных программных ошибок. Для этого были определены следующие ST-пары функций:
В процессе исследований менялась используемая ST-пара функций и варьировалась размерность параметров A, M и аргумента X. Результаты экспериментов полностью подтвердили приведенные выше временные за-висимости (технические результаты исследований авторы в данной работе опускают). Исследование возможности обнаружения предложенным методом преднамеренно внесенных ошибок заключалось в написании программы EXPZ. Спецификация для программ EXP и EXPZ одна и та же, отличие же заключается в том, что программа EXPZ содержит программную закладку деструктивного характера. Преднамеренно внесенная закладка при иссле-дованиях гарантировала сбой работы программы вычисления значения функции y = fAM (x) = Ax modulo M (то есть обеспечивала получение непра-ильного значения функции) примерно на каждой восьмой части входных значений экспоненты x. Было проведено свыше 2000 экспериментов . Все входные значения, на которых произошел сбой программы, были обнаружены, что в дальнейшем подтвердилось проверочными тестами, основанными на использовании малой теоремы Ферма и теореме Эйлера. Этот факт, в свою очередь, экспериментально показал, что программа, реализующая алгоритм ST, является (1/8,1/288)-самотестирующейся программой. Таким образом, предложенный метод позволяет в значительной степени сократить время испытания расчетных программ на предмет выявления непреднамеренных и преднамеренных программных дефектов. При этом по результатам испытаний можно получить количественные оценки вероятности наличия программных дефектов в верифицируемой расчетной программе. Однако, разработка формальных методов получения ST-пары функций для заданной расчетной программы, а также разработка методик ее испытания с помощью рассмотренного алгоритма требуют дальнейших теоретических и прикладных исследований. Метод создания самокорректирующейся процедуры вычисления теоретико - числовой функции дискретного экспоненцирования Обозначения и определения для функции дискретного возведения в степень вида gxmoduloM. Пусть In=Zq представляет собой множество {1,...,q}, где q= ?(M) - значение функции Эйлера для модуля M, а Z*M - множество вычетов по модулю M, где n= |log2M|. Пусть распределение Dp есть равномерное распределение вероятностей. Тогда равновероятный случайный выбор элемента a из множества ? будет обозначаться как a Алгоритм Axmodulo N можно вычислить многими способами [,], один из наиболее общеизвестных и применяемых, - это алгоритм, основанный на считывании индекса (значения степени) слева направо. Этот метод достаточно прост и нагляден, история его восходит еще к 200 г. до н.э. Пусть x[1,...,n] - двоичное представление положительного числа x и A, B и N - положительные целые числа в r-ичной системе счисления, тогда псевдокод алгоритма Axmodulo N, реализованного программой Exp(') имеет следующий вид. Псевдокод алгоритма AxmoduloN Program Exp(x,N,A,R); {вход x,N,A, выход R} begin B:=1; for i:=1 to n do begin B:=(B*B)modN; if [i]=1 then B:=(A*B)modN; end; R:=B; end. Из описания алгоритма видно, что число обращений к операции вида (A*B)moduloN будет logx+ ?(x), где ?(x) число единиц в двоичном представлении операнда x или вес Хэмминга x. Построение самотестирующейся/самокорректирующейся программной пары для функции дискретного экспоненцирования. Сначала рассмотрим следующие 4 алгоритма (см. рис.2.6 - 2.9). Для доказательства полноты и безопасности указанной пары доказывается сле-дующая теорема. Теорема 2.2. Пара программ S_K_exp(x,M,q,g,?) и S_T_exp(x,M,q,g,?) является (1/288,1/8,1/8)-самокорректирующейся/ самотестирующейся про-граммной парой для функции gxmoduloM, с входными значениями, выбранными случайно и равновероятно из множества In. Для доказательства теоремы необходимо доказать следующие две леммы. Лемма 2.1. Программа S_K_exp(M,q,g,?) является (1/8)-самокорректирующейся программой для вычисления функции gxmoduloM в отношении равномерного распределения Dn. Доказательство. Полнота программы S_K(') означает, что если оракульная программа P(x), обозначаемая как Exp(') выполняется корректно, то и самокорректирующаяся программа S_K(') будет выполняться кор-ректно. В данном случае полнота программы очевидна. Если P(x) коррект-но вычислима, то из
Рис. 2.6. Псевдокод алгоритма S_K_exp
Рис. 2.7. Псевдокод алгоритма S_T_exp Program L_T(n,R); {вход g,M,q, выход Rl} begin x1:=random(q); x2:=random(q); x:=(x1+x2)modq; Exp(g,x1,M,R1); Exp(g,x2,M,R2); Exp(g,x,M,R); if R1 R2=R then Rl:=1 else Rl:=0; end. Рис. 2.8. Псевдокод алгоритма теста линейной состоятельности L_T Program N_T(n,R); {вход g,M,q, выход Re} begin x1:=random(q); x2:=(x1+1)modq; Exp(g,x1,M,R1); Exp(g,x2,M,R2); if R1 g=R2 then Re:=1 else Re:=0; end. Рис. 2.9. Псевдокод алгоритма теста единичной состоятельности N_T Для доказательства безопасности сначала необходимо отметить, что так как x1 Так как вероятность ошибки ? Лемма 2.2. Программа S_T_exp(n,M,q,g,?) является (1/288,1/8)-самотестирующейся программой, которая контролирует результат вычисления значения функции gxmoduloM с любым модулем M. Доказательство. Полнота теста линейной состоятельности доказыва-ется аналогично доказательству полноты в лемме й, где x1,x2
Для доказательства условия самотестируемости необходимо отметить, что так как и в лемме 1 для того, чтобы вероятность корректных ответов Rl и Re в обоих тестах была не более 1-? достаточно выполнить тест линейной состоятельности 576ln(4/?) раз и тест единичной состоятельности 32ln(4/?) раз. Можно показать, основываясь на теоретико - групповых рассуждени-ях, что возможно обобщение программы S_T(') и для других групп (алгоритмы данной программы основываются на вычислениях в мультипликативной группе вычетов над конечным полем). То есть для всех y Исходя из определения самотестирующейся/ самокорректирующейся программной пары и основываясь на результатах доказательств лемм 1 и 2, очевидным образом следует доказательство теоремы 1. Замечания. Как видно из псевдокода алгоритма Axmodulo N в нем используется операция ABmodulo N. Используя ту же технику доказательств, как и для функции дискретного возведения в степень, можно построить (1/576,1/36,1/36)-самокорректирующуюся/ самотестирующуюся программ-ную пару для вычисления функции модулярного умножения. Это справед-ливо исходя из следующих соображений. Вычисление функции fM(ab)=fM((a1+a2)(b1+b2)) следует из корректного выполнения программы с 4-х кратным вызовом оракульной программы P(a,b), то есть: [PM(a1,b1)+PM(a1,b2)+PM(a2,b1)+PM(a2,b2)](mod M). Алгоритм вычисления Axmodulo N выполняется для c=2. Однако, декомпозиция x, как следует из свойства самосводимости функции Axmodulo N, может осуществляться на большее число слагаемых. Хотя это приведет к гораздо большему количеству вызовов оракульной программы, но в то же время позволит значительно снизить вероятность ошибки. Применение самотестирующихся и самокорректирующихся программ Применение самотестирующихся, самокорректирующихся программ и их сочетаний возможно в самых различных областях вычислительной математики, а, следовательно, в самых разнообразных областях человече-ской деятельности, где широко применяются вычислительные методы. К ним относятся такие направления как цифровая обработка сигналов (а, следовательно, решение проблем в системах распознавания изображений, голоса, в радио- и гидроакустике), а также методы математического моделирования процессов изменения народонаселения, экономических процессов, процессов изменения погоды и т.п. Идеи самотестирования могут найти самое широкое применение в системах защиты информации, например, в системах открытого распределения ключей, в криптосистемах с открытым ключом, в схемах идентификации пользователей вычислительных систем и аутентификации данных, где базовые вычислительные алгоритмы обладают некоторыми алгоритмическими свойствами, например, свойством случайной самосводимости, описанным выше. Активными исследованиями в области создания самотестирующихся и самокорректирующихся программ в вычислительной математике ученые и практики начали заниматься с начала 90-х годов. В этот период были разработаны самотестирующиеся программы для ряда теоретико-числовых и теоретико-групповых задач, для решения задач с матрицами, полиномами, линейными уравнениями, рекуррентными соотношениями и аппроксимирующими функциями. Основная идея использования идей самотестирования в криптографии заключается в неформальном девизе "Защитить самих защитников". Так как криптографические методы используются для высокоуровневого обеспечения конфиденциальности и целостности информации, собственно программно-техническая реализация этих методов должна быть свободна от программных и/или аппаратных дефектов. Таким образом, самотестирование и самокоррекция программ может эффективно применяться в совре-менных системах защиты информации от несанкционированного доступа. К другим направлениям в теории и практике самотестирования можно отнести построение псевдослучайных генераторов, в котором центральным звеном является конструкция, которую можно рассматривать как самокорректирующую программу для решения задачи, эквивалентной проблеме дискретных логарифмов, а также разработку самотестирующихся программ для параллельных вычислений, где используется идея самотестирования для построения схемы константной глубины для проверки мажоритарных функций. Методы создания самотестирующихся и самокорректирующихся программ для решения вычислительных задачОбщие принципы создания двухмодульных вычислительных процедур и методология самотестирования Пусть необходимо написать программу P для вычисления функции f так, чтобы P(x)=f(x) для всех значений x.Традиционные методы верификационного анализа и тестирования программ не позволяют убедиться с вероятностью близкой к единице в корректности результата выполнения программы, хотя бы потому, что тестовый набор входных данных, как правило, не перекрывают весь их возможный спектр. Один из методов решения данной проблемы заключается в создании так называемых самокорректирующихся и самотестирующихся программ, которые позволяют оценить вероятность некорректности результата выполнения программы, то есть, что P(x) Чтобы добиться корректного результата выполнения программы P, вычисляющей функцию f, нам необходимо написать такую программу Tf, которая позволяла бы оценить вероятность того, что P(x) Обязательным условием для программы Tf является ее принципиальное отличие от любой корректной программы вычисления функции f, в том смысле, что время выполнения программы Tf, не учитывающее время вызовов программы P, должно быть значительно меньше, чем время выполнения любой корректной программы для вычисления f. В этом случае, вычисления согласно Tf некоторым количественным образом должны отличаться от вычислений функции f и самотестирующаяся программа может рассматриваться как независимый шаг при верификации программы P, которая предположительно вычисляет функцию f. Кроме того, желательное свойство для Tf должно заключаться в том, чтобы ее код был насколько это возможно более простым, то есть Tf должна быть эффективной в том смысле, что время выполненияTf даже с учетом времени, затраченное на вызовы P должно составлять константный мультипликативный фактор от времени выполнения P. Методы защиты программ от исследованияДля защиты программ от исследования необходимо применять методы защиты от исследования файла с ее исполняемым кодом, хранящемся на внешнем носителе, а также методы защиты исполняемого кода, загружаемого в оперативную память для выполнения этой программы. В первом случае защита может быть основана на шифровании секрет-ной части программы, а во втором - на блокировании доступа к исполняемому коду программы в оперативной памяти со стороны отладчиков . Кроме того, перед завершением работы защищаемой программы должен обнуляться весь ее код в оперативной памяти. Это предотвратит возмож-ность несанкционированного копирования из оперативной памяти дешифрованного исполняемого кода после выполнения защищаемой программы. Таким образом, защищаемая от исследования программа должна включать следующие компоненты: инициализатор; зашифрованную секретную часть; деструктор (деициниализатор). Инициализатор должен обеспечивать выполнение следующих функ-ций: сохранение параметров операционной среды функционирования (векторов прерываний, содержимого регистров процессора и т.д.); запрет всех внутренних и внешних прерываний, обработка кото-рых не может быть запротоколирована в защищаемой программе; загрузка в оперативную память и дешифрование кода секретной части программы; передача управления секретной части программы. Секретная часть программы предназначена для выполнения основных целевых функций программы и защищается шифрованием для предупреждения внесения в нее программной закладки. Деструктор после выполнения секретной части программы должен выполнить следующие действия: обнуление секретного кода программы в оперативной памяти; восстановление параметров операционной системы (векторов пре-рываний, содержимого регистров процессора и т.д.), которые были установлены до запрета неконтролируемых прерываний; выполнение операций, которые невозможно было выполнить при запрете неконтролируемых прерываний; освобождение всех незадействованных ресурсов компьютера и завершение работы программы. Для большей надежности инициализатор может быть частично зашифрован и по мере выполнения может дешифровать сам себя. Дешифроваться по мере выполнения может и секретная часть программы. Такое дешифрование называется динамическим дешифрованием исполняемого кода. В этом случае очередные участки программ перед непосредственным исполнением расшифровываются, а после исполнения сразу уничтожаются. Для повышения эффективности защиты программ от исследования необходимо внесение в программу дополнительных функций безопасности, направленных на защиту от трассировки. К таким функциям можно отнести: периодический подсчет контрольной суммы области оперативной памяти, занимаемой защищаемым исходным кодом; сравнение текущей контрольной суммы с предварительно сформированной эталонной и принятие необходимых мер в случае несовпадения; проверку количества занимаемой защищаемой программой опера-тивной памяти; сравнение с объемом, к которому программа адаптирована, и принятие необходимых мер в случае несоответствия; контроль времени выполнения отдельных частей программы; блокировку клавиатуры на время отработки особо секретных алго-ритмов. Для защиты программ от исследования с помощью дизассемблеров можно использовать и такой способ, как усложнение структуры самой программы с целью запутывания злоумышленника, который дизассемблирует эту программу. Например, можно использовать разные сегменты адреса для обращения к одной и той же области памяти. В этом случае злоумышленнику будет трудно догадаться, что на самом деле программа работает с одной и той же областью памяти. Методы защиты программ от несанкционированных измененийРешение проблемы обеспечения целостности и достоверности электронных данных включает в себя решение, по крайней мере, трех основных взаимосвязанных задач: подтверждения их авторства и подлинности, а также контроль целостности данных. Решение этих трех задач в случае защиты программного обеспечения вытекает из необходимости защищать программы от следующих злоумышленных действий: РПС может быть внедрены в авторскую программу или эта программа может быть полностью заменена на программу-носитель РПС; могут быть изменены характеристики (атрибуты) программы; злоумышленник может выдать себя за настоящего владельца программы; законный владелец программы может отказаться от факта правообладания ею. Наиболее эффективными методами защиты от подобных злоумышленных действий предоставляют криптографические методы защиты. Это обусловлено тем, что хорошо известные способы контроля целостности программ, основанные на контрольной сумме, продольном контроле и контроле на четность, как правило, представляют собой довольно простые способы защиты от внесения изменений в код программ. Так как область значений, например, контрольной суммы сильно ограничена, а значения функции контроля на четность вообще представляются одним-двумя битами, то для опытного нарушителя не составляет труда найти следующую коллизию: f(k1)=f(k2), где k1 - код программы без внесенной нарушителем закладки, а k2 - с внесенной программным закладкой и f - функция контро-ля. В этом случае значения функции для разных аргументов совпадают при тестировании и, следовательно, закладка обнаружена не будет. Для установления подлинности (неизменности) программ необходимо использовать более сложные методы, такие как аутентификация кода программ, с использованием криптографических способов, которые обнаруживают следы, остающиеся после внесения преднамеренных искажений. В первом случае аутентифицируемой программе ставится в соответствие некоторый аутентификатор, который получен при помощи стойкой криптографической функции. Такой функцией может быть криптографически стойкая хэш-функция (например, функция ГОСТ Р 34.11-94) или функция электронной цифровой подписи (например, функция ГОСТ Р 34.10-94). И в том, и в другом случае аргументами функции может быть не только код аутентифицируемой программы, но и время и дата аутентификации, идентификатор программиста и/или предприятия - разработчика ПО, какой-либо случайный параметр и т.п. Может использоваться также любой симметричный шифр (например, DES или ГОСТ 28147-89) в режиме генерации имитовставки. Однако, это требует наличия секретного ключа при верификации программ на целостность, что бывает не всегда удобно и безопасно. В то время как при использовании метода цифровой подписи при верификации необходимо иметь только некоторую общедоступную информацию, в данном случае открытый ключ подписи. То есть контроль целостности ПО может осуществить любое заинтересованное лицо, имеющее доступ к открытым ключам используемой схемы цифровой подписи. Можно еще более усложнить действия злоумышленника по нарушению целостности целевых программ, используя схемы подписи с верификацией по запросу [,]. В этом случае тестирование программ по ассоциированным с ними аутентификаторам можно осуществить только в присутствии лица, сгенерировавшего эту подпись, то есть в присутствии разработчика программ или представителей предприятия-изготовителя программного обеспечения. В этом случае, если даже злоумышленник и получил для данной программы некий аутентификатор, то ее обладатель может убедиться в достоверности программы только в присутствии специалистов-разработчиков, которые немедленно обнаружат нарушения целостности кода программы и (или) его подлинности. Международные стандарты в области информационной безопасностиОбщие вопросы За рубежом разработка стандартов проводится непрерывно, последовательно публикуются проекты и версии стандартов на разных стадиях согласования и утверждения. Некоторые стандарты поэтапно углубляются и детализируются в виде совокупности взаимосвязанных по концепциям и структуре групп стандартов. Принято считать, что неотъемлемой частью общего процесса стандартизации информационных технологий (ИТ) является разработка стандартов, связанных с проблемой безопасности ИТ, которая приобрела большую актуальность в связи с тенденциями все большей взаимной интеграции прикладных задач, построения их на базе распределенной обработки данных, систем телекоммуникаций, технологий обмена электронными данными. Разработка стандартов для открытых систем, в том числе и стандартов в области безопасности ИТ, осуществляется рядом специализированных международных организаций и консорциумов таких, как, например, ISO, IЕС, ITU-T, IEEE, IАВ, WOS, ЕСМА, X/Open, OSF, OMG и др. Значительная работа по стандартизации вопросов безопасности ИТ проводится специализированными организациями и на национальном уровне. Все это позволило к настоящему времени сформировать достаточно обширную методическую базу, в виде международных, национальных и отраслевых стандартов, а также нормативных и руководящих материалов, регламентирующих деятельность в области безопасности ИТ. Основные нормативно-технические документы в области информационной безопасности приведены в таблице 4.1 (название некоторых документов приводятся в сокращенном виде, - их полное название можно найти в тексте данного раздела или списке литературы). При этом существующие нормативно-методические и нормативно-технические документы привязаны к этапам жизненного цикла автоматизированных систем. Архитектура безопасности Взаимосвязи открытых систем Большинство современных сложных сетевых структур, лежащих в качестве телекоммуникационной основы существующих АС проектируются с учетом идеологии Эталонной модели (ЭМ) Взаимосвязи открытых систем (ВОС), которая позволяет оконечному пользователю сети (или его прикладным процессам) получить доступ к информационно-вычислительным ресурсам значительно легче, чем это было раньше. Вместе с тем концепция открытости систем создает ряд трудностей в организации защиты информации в ВС. Требование защиты ресурсов сети от НСД является обязательным при проектировании и реализации большинства современных ИВС, соответствующих ЭМ ВОС. В 1986 г. рядом международных организаций была принята Архитектура безопасности ВОС (АБ ВОС). В архитектуре ВОС выделяют семь уровней иерархии: физический, канальный, сетевой, транспортный, сеансовый, представительный и прикладной. Однако в АБ ВОС предусмотрена реализация механизмов защиты в основном на пяти уровнях. Для защиты информации на физическом и канальном уровне обычно вводится такой механизм защиты, как линейное шифрование. Канальное шифрование обеспечивает закрытие физических каналов связи с помощью специальных шифраторов. Однако применение только канального шифрования не обеспечивает полного закрытия информации при ее передаче по ИВС, так как на узлах коммутации пакетов информация будет находиться в открытом виде. Поэтому НСД нарушителя к аппаратуре одного узла ведет к раскрытию всего потока сообщений, проходящих через этот узел. В том случае, когда устанавливается виртуальное соединение между двумя абонентами сети и коммуникации, в данном случае, проходят по незащищенным элементам ИВС, необходимо сквозное шифрование, когда закрывается информационная часть сообщения, а заголовки сообщений не шифруются. Это позволяет свободно управлять потоками зашифрованных сообщений. Сквозное шифрование организуется на сетевом и/или транспортном уровнях согласно ЭМ ВОС. На прикладном уровне реализуется большинство механизмов защиты, необходимых для полного решения проблем обеспечения безопасности данных в ИВС. АБ ВОС устанавливает следующие службы безопасности (см. табл.4.2.). обеспечения целостности данных (с установлением соединения, без установления соединения и для выборочных полей сообщений); обеспечения конфиденциальности данных (с установлением соединения, без установления соединения и для выборочных полей сообщений); контроля доступа; аутентификации (одноуровневых объектов и источника данных); обеспечения конфиденциальности трафика; обеспечения невозможности отказа от факта отправки сообщения абонентом - передатчиком и приема сообщения абонентом - приемником. Состояние международной нормативно-методической базы С целью систематизации анализа текущего состояния международной нормативно-методической базы в области безопасности ИТ необходимо использовать некоторую классификацию направлений стандартизации. В общем случае, можно выделить следующие направления. Общие принципы управления информационной безопасностью. Модели безопасности ИТ. Методы и механизмы безопасности ИТ (такие, как, например: методы аутентификации, управления ключами и т.п.). Криптографические алгоритмы. Методы оценки безопасности информационных систем. Безопасность EDI-технологий. Безопасность межсетевых взаимодействий (межсетевые экраны). Сертификация и аттестация объектов стандартизации. Стандартизация вопросов управления информационной безопасностью Анализ проблемы защиты информации в информационных системах требует, как правило, комплексного подхода, использующего общеметодологические концептуальные решения, которые позволяют определить необходимый системообразующей контекст для редуцирования общей задачи управления безопасностью ИТ к решению частных задач. Поэтому в настоящее время возрастает роль стандартов и регламентирующих материалов общеметодологического назначения. На роль такого документа претендует, находящийся в стадии утверждения проект международного стандарта ISO/IEC DTR 13335-1,2,3 - "Информационная технология. Руководство по управлению безопасностью информационных технологий". Данный документ содержит: определения важнейших понятий, непосредственно связанных с проблемой управления безопасностью ИТ; - определение важных архитектурных решений по созданию систем управления безопасностью ИТ (СУБ ИТ), в том числе, определение состава элементов, задач, механизмов и методов СУБ ИТ; описание типового жизненного цикла и принципов функционирования СУБ ИТ; описание принципов формирования политики (методики) управления безопасностью ИТ; методику анализа исходных данных для построения СУБ ИТ, в частности методику идентификации и анализа состава объектов защиты, уязвимых мест информационной системы, угроз безопасности и рисков и др.; методику выбора соответствующих мер защиты и оценки остаточного риска; принципы построения организационного обеспечения управления в СУБ ИТ и пр. Стандартизация моделей безопасности ИТ С целью обеспечения большей обоснованности программно-технических решений при построении СУБ ИТ, а также определения ее степени гарантированности, необходимо использование возможно более точных описательных моделей как на общесистемном (архитектурном) уровне, так и на уровне отдельных аспектов и средств СУБ ИТ. Построение моделей позволяет структурировать и конкретизировать исследуемые объекты, устранить неоднозначности в их понимании, разбить решаемую задачу на подзадачи, и, в конечном итоге, выработать необходимые решения. Можно выделить следующие международные стандарты и другие документы, в которых определяются основные модели безопасности ИТ: ISO/IEC 7498-2-89 - "Информационные технологии. Взаимосвязь открытых системы. Базовая эталонная модель. Часть 2. Архитектура информационной безопасности"; ISO/IEC DTR 10181-1 - "Информационные технологии. Взаимосвязь открытых систем. Основы защиты информации для открытых систем. Часть 1. Общее описание основ защиты информации ВОС"; ISO/IEC DTR 10745 - "Информационные технологии. Взаимосвязь открытых систем. Модель защиты информации верхних уровней"; ISO/IEC DTR 11586-1 - "Информационные технологии. Взаимосвязь открытых систем. Общие функции защиты верхних уровней. Часть 1. Общее описание, модели и нотация"; ISO/IEC DTR 13335-1 - "Информационные технологии. Руководство по управлению безопасностью информационных технологий. Часть 1. Концепции и модели безопасности информационных технологий".< Стандартизация методов и механизмов безопасности ИТ На определенном этапе задача защиты информационных технологий разбивается на частные подзадачи, такие как обеспечение, конфиденциальности, целостности и доступности. Для этих подзадач должны вырабатываться конкретные решения по организации взаимодействия объектов и субъектов информационных систем. К таким решениям относятся методы: аутентификации субъектов и объектов информационного взаимодействия, предназначенные для предоставления взаимодействующим сторонам возможности удостовериться, что противоположная сторона действительно является тем, за кого себя выдает; шифрования информации, предназначенные для защиты информации в случае перехвата ее третьими лицами; контроля целостности, предназначенные для обеспечения того, чтобы информация не была искажена или подменена; управления доступом, предназначенные для разграничения доступа к информации различных пользователей; - повышения надежности и отказоустойчивости функционирования системы, предназначенные для обеспечения гарантий выполнения информационной системой целевых функций; управления ключами, предназначенные для организации создания, распространения и использования ключей субъектов и объектов информационной системы, с целью создания необходимого базиса для процедур аутентификации, шифрования, контроля подлинности и управления доступом. Организации по стандартизации уделяют большое внимание разработке типовых решений для указанных выше аспектов безопасности. К ним, в первую очередь отнесем следующие международные стандарты: ISO/IEC 9798-91 - "Информационные технологии. Защита информации. Аутентификация объекта". Часть 1. Модель. Часть 2. Механизмы, использующие симметричные криптографические алгоритмы. Часть 3. Аутентификация на базе алгоритмов с открытыми ключами. Часть 4. Механизмы, использующие криптографическую контрольную функцию. Часть 5. Механизмы, использующие алгоритмы с нулевым разглашением. ISO/IEC 09594-8-88 - " Взаимосвязь открытых систем. Справочник. Часть 8. Основы аутентификации"; ISO/IEC 11577-94 - "Информационные технологии. Передача данных и обмен информацией между системами. Взаимосвязь открытых систем. Протокол защиты информации на сетевом уровне"; ISO/IEC DTR 10736 - "Информационные технологии. Передача данных и обмен информацией между системами. Протокол защиты информации на транспортном уровне"; ISO/IEC CD 13888 - "Механизмы предотвращения отрицания". Часть 1. Общая модель. Часть 2. Использование симметричных методов. Часть 3. Использование асимметричных методов; ISO/IEC 8732-88 - "Банковское дело. Управление ключами"; ISO/IEC 11568-94 - "Банковское дело. Управление ключами". Часть 1. Введение. Управление ключами. Часть 2. Методы управления ключами для симметричных шифров. Часть 3. Жизненный цикл ключа для симметричных шифров; ISO/IEC 11166-94 - "Банковское дело. Управление ключами посредством асимметричного алгоритма". Часть 1. Принципы процедуры и форматы. Часть 2. Принятые алгоритмы, использующие криптосистему RSA; ISO/IEC DIS 13492 - "Банковское дело. Управление ключами, относящимися к элементам данных"; ISO/IEC CD 11770 - "Информационные технологии. Защита информации. Управление ключами". Часть 1. Общие положения. Часть 2. Механизмы, использующие симметричные методы. Часть 3. Механизмы, использующие асимметричные методы; ISO/IEC DTR 10181- "Информационные технологии. Взаимосвязь открытых систем. Основы защиты информации для открытых систем". Часть 1. Общее описание основ защиты информации в ВОС. Часть 2. Основы аутентификации. Часть 3. Управление доступом. Часть 4. Безотказность получения. Часть 5. Конфиденциальность. Часть 6. Целостность. Часть 7. Основы проверки защиты. К этому же уровню следует отнести стандарты, описывающие интерфейсы механизмов безопасности ИТ: ISO/IEC 10164-7-92. "Информационные технологии. Взаимосвязь открытых систем. Административное управление системы. Часть 7. Функции уведомления о нарушениях информационной безопасности". ISO/IEC DTR 11586. "Информационные технологии. Взаимосвязь открытых систем. Общие функции защиты верхних уровней". Часть 1. Общее описание, модели и нотация. Часть 2. Определение услуг сервисного элемента обмена информацией защиты. Часть 3. Спецификация протокола сервисного элемента обмена информацией защиты. Часть 4. Спецификация синтаксиса защищенной передачи. В стандартах этого уровня, как правило, не указываются конкретные криптографические алгоритмы, а декларируется, что может быть использован любой криптоалгоритм, при этом подразумевалось использование определенных зарубежных криптографических алгоритмов. Поэтому в ряде случаев при использовании некоторых стандартов может потребоваться их адаптация к отечественным криптоалгоритмам. Стандартизация международных криптографических алгоритмов ISO стандартизировала ряд криптографических алгоритмов в таких международных стандартах, как, например: ISO/IEC 10126-2-91 - "Банковское дело. Процедуры шифрования сообщения. Часть 2. Алгоритм DEA"; ISO/IEC 8732-87 - "Информационные технологии. Защита информации. Режимы использования 64-битного блочного алгоритма"; ISO/IEC 10116-91- "Банковское дело. Режимы работы n-бит блочного алгоритма шифрования"; ISO/IEC 10118-1,2-88 - "Информационные технологии. Шифрование данных. Хэш-функция для цифровой подписи"; ISO/IEC CD 10118-3,4 - "Информационные технологии. Защита информации. Функции хэширования"; ISO/IEC 9796-91 - "Информационные технологии. Схема электронной подписи, при которой производится восстановление сообщения"; ISO/IEC CD 14888 - "Информационные технологии. Защита информации. Цифровая подпись с добавлением". Однако широкое внедрение этих алгоритмов представляется малореальным, поскольку политика крупных государств направлена, как правило, на использование собственных криптоалгоритмов. Модель угроз и принципы обеспечения безопасности программного обеспеченияИспользование при создании программного обеспечения КС сложных операционных систем, инструментальных средств разработки ПО импортного производства увеличивают потенциальную возможность внедрения в программы преднамеренных дефектов диверсионного типа. Помимо этого, при создании целевого программного обеспечения всегда необходимо исходить из возможности наличия в коллективе разработчиков программистов - злоумышленников, которые в силу тех или иных причин могут внести в разрабатываемые программы РПС. Характерным свойством РПС в данном случае является возможность внезапного и незаметного нарушения или полного вывода из строя КС. Функционирование РПС реализуется в рамках модели угроз безопасности ПО, основные элементы которой рассматриваются в следующем разделе. |