Адаптивная установка порогового значения
Критическим аспектом нашего подхода, влияющим и на расходы, и на корректность, является определение момента времени, в который следует переключать уровни согласованности.
Пусть Cx обозначает стоимость выполнения операции обновления записи категории x. В этой стоимости отражаются только дополнительные расходы в расчете на запись в уже выполняемой транзакции; расходы на образование транзакции не учитываются. Пусть CO – это расходы, связанные с нарушением согласованности. Запись следует обрабатывать на уровне слабой согласованности, только если ожидаемая экономия от применения слабой согласованности превышает ожидаемые расходы EO(X), вызываемые несогласовавнностью:

Если CA - CC > EO(X), то запись следует обрабатывать на уровне сессионной согласованности (данные категории C). Если CA - CC < EO(X), то запись следует обрабатывать на уровне строгой согласованности (данные категории A). В предположении, что EO(X) = PC(X) × CO, запись следует обрабатывать в режиме слабой согласованности, если вероятность конфликта меньше значения (CA - CC) / CO:

Это же соотношение можно использовать и для оптимизации параметров, отличных от стоимости. Например, если оптимизируется пропускная способность системы, и мы предполагаем, что разрешение конфликтов снижает производительность, то можно использовать ту же формулу, заменив показатели стоимости показателями производительности.
Ключевым аспектом Общей политики является то, что пользователь можно просто либо указать фиксированную вероятность несогласованности, либо обеспечить функцию стоимости независимо от того, что означает стоимость в конкретном случае. Все остальное делается системой автоматически. В этом смысле гарантия согласованности становится вероятностной. Вероятность несогласованности будет корректироваться в зависимости от того, насколько значимой для пользователя является согласованность.
Архитектура
На рис. 1 показана общая архитектура, которую мы позаимствовали из . Клиенты подключаются через Internet к одному из серверов приложений. Серверы приложений работают в "облачной" среде поверх службы виртуальных машин Amazon Elastic Computing Cloud (EC2). Кроме того, в этой архитектуре в одной системе объединяются серверы баз данных и приложений, а для постоянного хранения данных используется Amazon Simple Storage Service. Следовательно, страницы данных хранятся в S3, и данные выбираются прямо из сервера приложений аналогично тому, как если бы имелась база данных с общими дисками. Чтобы координировать записи в S3, на каждом сервере приложений поддерживает набор протоколов. Протоколы, представленные в , разработаны в многоуровневом стиле, и на каждом уровне повышается уровень согласованности. В качестве индексной структуры используется B-дерево, которое также сохраняется в S3.
Мы использовали протоколы, описанные в , и построили над ними протоколы для сессионной согласованности и сериализуемости. Кроме того, мы усовершенствовали механизм журнализации, введя средства логической журнализации. Чтобы обеспечить гарантии адаптивной согласованности, мы реализовали управление необходимыми метаданными, политики и компонент, собирающий и обрабатывающий требуемую темпоральную статистику.

Рис. 2. Базовый протокол
Динамическая политика
Динамическая политика обеспечивает вероятностные гарантии согласованности за счет регулировки порогового значения.
Модель. Как и при рассмотрении Общей политики, мы предполагаем, что имеется интервал кэширования, и что обновления равномерно распределены между серверами. Следовательно, вероятность того, что значение некоторой записи станет отрицательно, выражается следующим образом:

Здесь Y – это случайная переменная, соответствующая общему объему изменений в течение интервала кэширования CI. Y отличается от X из соотношения (1) тем, что в значении этой переменной отражается не число выполненных операций обновления, а общий объем всех обновлений в течение интервала кэширования. P(T - Y < 0) соответствует вероятности нарушения ограничения согласованности (например, за счет покупки слишком большого числа товаров до того, как сервер начинает применять строгую согласованность).
Темпоральная статистика. Для сбора статистики для Y мы снова используем окно с размеров w и показателем скольжения δ. В отличие от случая Общей политики, мы полагаем, что показатель скольжения δ не кратен интервалу кэширования CI, а является его долей. Для этого имеются два основания. Во-первых, для Динамической политики требуется определение дисперсии. Более точные значения дисперсии получаются при использовании меньших показателей скольжения. Во-вторых, политика концентрируется на часто обновляемых значениях. События (т.е. обновления) не являются редкими, и, следовательно, требуемый объем данных можно собрать в течение меньшего времени.
Для каждого интервала скольжения собирается общий объем всех обновлений данных категории B. Все завершившиеся интервалы окна составляют гистограмму обновлений. Если в некоторой транзакции требуется обновить некоторую запись, то на основе гистограммы скользящего окна с использованием стандартной формулы вычисляется эмпирическая функция плотности вероятности (probability density function, PDF) f. Затем f свертывается (convoluted) CI / δ раз для построения PDF fCI для всего интервала кэширования:

Свертка требуется, поскольку для нас важно сохранить десперсию.
Чтобы можно было судить об обновлениях в системе целиком, должно быть известно число серверов n. Если свернуть n раз fCI, мы получим PDF для обновлений во всей системе:

При наличии fCI*n можно построить интегральную функцию распределения (cumulative distribution function, CDF), которую, в конце концов, можно использовать для определения порогового значения для P(T - X < 0) путем поиска такой вероятности, что

Для оптимизации PC(Y) можно использовать тот же метод, что и ранее:

Заметим, что пороговое значение T определяется при условии, что вероятность больше, чем PC(Y), а не меньше.
Хотя существуют эффективные алгоритмы свертки функций, если значение n*CI/δ достаточно велико и/или элемент часто обновляется, то центральная предельная теорема позволяет аппроксимировать CDF нормальным распределением. Это обеспечивает возможность более быстрого вычисления порогового значения для гарантирования процентиля согласованности. С использованием гистограммы плавающего окна можно вычислить арифметическое среднее значение


и стандартным отклонением

Мы используем статистические данные собираемые во время выполнения, для установки порогового значения для каждой отдельной записи в зависимости от частоты ее обновления. Как показывают результаты эксперимента 2, описываемые в разд. 7, это Динамическая политика превосходит все другие политики по показателям как производительности, так и стоимости. Поскольку статистика собирается во время выполнения, система также имеет возможность реагировать на изменение темпа поступления операций изменения записей.
Эксперимент 1: стоимость в расчете на транзакцию
Основная суть этой статьи состоит в оптимизации общей стоимости транзакции – стоимости, выраженной в долларах. Эта стоимость включает как стоимость выполнения транзакции, так и расходы, возникающие при продаже товаров сверх наличных запасов. В нашем первом эксперименте, результаты которого показаны на рис. 3, мы сравниваем общую стоимость транзакции при соблюдении разных гарантий согласованности.

Рис. 3. Стоимость транзакции ($/1000 транзакций); изменяются гарантии
Для данных категории A стоимость 1000 транзакций составляет примерно $0.15. Для данных категории C стоимость существенно зависит от распределения операций обновления. Для сильно скошенных распределений "80-20" возникает много продаж сверх имеющихся запасов из-за высокого уровня конкуренции операций записи за несколько записей данных. Для обеспечения адаптивной гарантии согласованности мы использовали Динамическую политику, поскольку она лучше всего подходит для сценария Internet-магазина. Эта политика обеспечивает наименьшую стоимость транзакций. Динамическая политика способствует нахождению правильного баланса между слабой согласованностью (позволяющей экономить расходы в время выполнения) и строгой согласованностью (гарантирующей отсутствие продаж сверх наличных запасов).
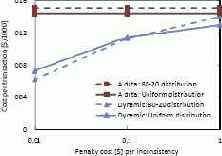
Рис. 4. Стоимость транзакции ($/1000 транзакций); изменяются расходы, вызываемые несогласованностью данных
На общую стоимость сильное влияние оказывает размер расходов, вызываемых несогласованностью данных. Это влияние демонстрируется на рис. 4. Для данных категории A общая стоимость транзакции при изменении размера этих расходов остается неизменной, поскольку несогласованность данных не возникает, и штрафных расходов просто нет. При возрастании размера расходов общая стоимость транзакций при применении Динамической политики приближается к стоимости транзакций с данными категории A. Динамическая политика настраивается на изменений размера штрафных расходов (см. п. 5.3.3) и при увеличении этого размера вынуждает выполняться в режиме строгой согласованности все большее число транзакций. Стоимость транзакций для данных категории C поразительно быстро растет. При увеличении размера штрафных расходов до $0.1 общая стоимость тысячи транзакций возрастает до $0.74 ($23) для равномерного распределения операций обновления (распределения "80-20"). Поэтому график возрастания стоимости транзакций для данных категории C на рис. 4 не показан.
Экстраполяция результатов экспериментов с использованием Динамической политики на приложения реального мира (такие как Amazon или eBay) показывает, что этот подход может привести к значительной экономии расходов.

Рис. 5. Время ответа (миллисекунды)
Эксперимент 2: время ответа
Более тщательное рассмотрение аспектов производительности системы позволило нам измерить время реакции системы на одиночные действия тестового набора TPC-W. На рис. 5 приведены основные экспериментальные данные. Наибольшее время ответа система демонстрирует для данных категории A. Каждая транзакция с данными категории A должна получить блокировку до выполнения операций чтения и записи. Наименьшее время ответа обеспечивается для данных категории C, поскольку в этом случае блокировки не требуются. При использовании Динамической политики время ответа увеличивается на 24%, поскольку в этом случае иногда блокировки требуются, чтобы избежать продаж сверх имеющихся запасов. На основании этого мы полагаем, что Динамическая политика может успешно конкурировать с другими современными политиками по отношению к производительности, позволяя в то же время оптимизировать стоимость транзакций (см. предыдущий эксперимент).
Эксперимент 3: политики
В третьем эксперименте детально изучались различия нескольких адаптивных политик. Мы фокусировались на числовых политиках, поскольку именно они применяются в сценарии Internet-магазина, и сравнивали Политику с фиксированным пороговым значением (с порогами T = 40 и T = 12) с Политикой разъединения и Динамической политикой. Тем не менее, поскольку Динамическая политика для числовых данных – это всего лишь развитая форма Общей политики, а Политика, основанная на времени, – это всего лишь особый случай Политики с фиксированным пороговым значением, полученные результаты могут служить и примерами для Политики, основанной на времени, и для Общей политики.

Рис. 6. Стоимость транзакции ($/1000 транзакций)
На рис. 6 приведены стоимости 1000 транзакций в долларах. Политика с фиксированным пороговым значением T = 12 оптимизирована для равномерного распределения операций обновления записей данных (см. эксперимент 4). Эта политика обеспечивает самую низкую стоимость транзакций при равномерном распределении обновлений. При скошенных распределениях операций обновления та же политика приводит к очень высокой стоимости транзакций. Установка порогового значения T = 40 способствует снижению стоимости транзакций при скошенных распределениях обновлений, но повышает стоимость транзакций при равномерном распределении обновлений. Мы приходим к выводу, что Политика с фиксированным пороговым значением сильно зависит от величины порогового значения, и что она уступает по производительности более сложным политикам. Уже Политика разъединения обеспечивает более низкую стоимость транзакций при обоих видах распределений операций обновления, а Динамическая политика может превзойти и Политику разъединения.

Рис. 7. Время ответа (миллисекунды)
На рис. 7 показано время ответа системы при использовании разных политик. Как можно видеть, Динамическая политика обеспечивает наименьшее время ответа. Если в базе данных объем запасов некоторого товара становится меньше фиксированного порогового значения, Политика с фиксированным пороговым значением приведет к выполнению транзакций на уровне строгой согласованности. Чем выще пороговое значение, тем раньше эта политика начнет требовать строгую согласованность. Поэтому Политика с фиксированным пороговым значением демонстрирует увеличение времени ответа при увеличении значения порога. Даже при T = 12 Политика с фиксированным пороговым значением приводит к потребности в слишком большом числе блокировок по сравнению с Динамической политикой и Политикой разъединения.
Иначе говоря, Динамическая политика превосходит все другие политики, описываемые в этой статье, как по стоимости транзакций, так и по времени ответа. Это становится возможным за счет использования статистики, собираемой в время выполнения и игнорируемой другими, в большей мере статическими политиками.
Эксперимент 4: фиксированное пороговое значение
Наш последний эксперимент был посвящен еще более детальному изучению Политики с фиксированным пороговым значением. Целью являлось экспериментальное определение оптимального порогового значения в условиях нашего тестового набора. Мы хотели лучше понять эту политику принятия решений, а также подход рационализации согласованности в целом. В этом эксперименте операции обновления были равномерно распределены для всех продуктов, данные о которых содержались в базе данных.

Рис. 8. Расходы времени выполнения (в долларах) при изменении порогового значения
На рис. 8 приведены денежные показатели стоимости в расчете на 1000 транзакций при использовании Политики с фиксированным пороговым значением над данными категорий A, B и C. Мы изменяли пороговое значение. Поскольку это пороговое значение несущественно для данных категорий A и C, стоимость транзакций над такими данными остается неизменной. Расходы времени выполнения для данных категории B увеличиваются при возрастании порогового значения. Чем выше пороговое значение, тем раньше эта политика переключится на уровень строгой согласованности, который вызывает значительно больше накладных расходов (например, из-за потребности в блокировках и посылки большего числа сообщений).

Рис. 9. Продажи сверх имеющихся запасов при изменении порогового значения
На рис. 9 показан объем продаж сверх имеющихся запасов в расчете на 1000 транзакций. В нашей ситуации нагрузочного тестирования при работе с данными категории C образуется 7 продаж сверх имеющихся запасов на 1000 транзакций. Для данных категории A, конечно, такие продажи отсутствуют, поскольку данные всегда обновляются в режиме строгой согласованности. При работе с данными категории B чем выше пороговое значение, тем меньше продаж сверх наличных запасов. Так происходит из-за того, что Политика с фиксированным пороговым значением раньше переключается на уровень строгой согласованности. Начиная с порогового значения T = 14, продажи сверх имеющихся запасов исчезают.

Рис. 10. Общая стоимость транзакции при изменении порогового значения
На рис. 10 показана общая стоимость транзакции для данных категорий A, C и B при применении Политики с фиксированным пороговым значением. Общая стоимость является суммой расходов времени выполнения и расходов, связанных с продажей товаров сверх имеющихся запасов. При использовании Политики с фиксированным пороговым значением минимальная стоимость достигается при значении порога T = 12. При этом пороговом значении стоимость транзакции над данными категорий A и C оказывается существенно более высокой.
Эти цифры хорошо демонстрируют то, что адаптация системы во время выполнения позволяет эффективно изменять уровень согласованности от сессионной согласованности до сериализуемости.
Экспериментальная среда
Тестовый набор TPC-W. Тестовый набор TPC-W моделирует Internet-магазин (см. наш первый сценарий использования в разд. 2). В этом тестовом наборе подразумевается, что клиенты обходят Web-сайт Internet-магазина и, в конце концов, совершают покупки. Всего имеются 14 различных действий (например, поиск товара, регистрация клиента и покупка товара) и три разных смеси этих действий. Больше всего операций обновления производится в смеси заказов (Ordering Mix), в которой 10% действий являются покупками товаров. Во всех своих экспериментах мы использовали именно Ordering Mix, чтобы получить более точные характеристики подхода рационализации согласованности.
База данных, определяемая в тестовом наборе TPC-W, содержит данные восьми разных типов (например, элемент данных, содержащий информацию о продукте, включая объем его запаса). Кроме того, в тестовом наборе TPC-W требуется, чтобы все транзакции над базой данных выполнялись на уровне строгой согласованности. В своих экспериментах мы ослабляем это требование. Для изучения характеристик рационализации согласованности мы назначаем разным типам данных разные категории согласованности (см. ниже).
До начала каждого эксперимента устанавливалось некоторое константное значение объема запасов каждого продукта. В тестовом наборе TPC-W определяется, что запасы продуктов должны периодически восполняться. В этом случае тестовый набор может выполняться бесконечно без возникновения ситуаций, когда объем запасов какого-либо продукта становится меньше некоторого порогового значения. Нас интересуют несогласованные состояния базы данных, в которых объем запасов какого-нибудь продукта становится отрицательным по причине параллельного выполнения не изолированных транзакций. Чтобы получить возможность оценить эти несогласованности, мы не восполняем запасы продуктов, а завершаем эксперименты по прошествии заданного времени и подсчитываем число продаж сверх имеющихся запасов. Все эксперименты выполнялись в течении 300 секунд и повторялись по 10 раз.
В смеси Ordering Mix 10% всех действий являются действиями по покупке товаров. В одном действии покупки может быть приобретено сразу несколько видов продуктов. Общее число видов товара, приобретаемых за одну покупку, является случайной целой величиной со значениями от 1 до 6 (включительно). Т.е. за один раз можно приобрести не более 6 видов продуктов. Число единиц товара, которые можно приобрести при покупке данного вида товара, подчиняется правилу 80-20 . Мы реализовали это правило с использованием автомодельного распределения (self-similar distribution) Джима Грея (Jim Gray) с параметрами h = 0.2 и N = 4 . За одну покупку можно приобрести не более 4 единиц одного вида товара.
Распределения данных по категориям. В своих экспериментах мы изучали влияние параметров категоризации. Разные типы данных тестового набора TPC-W приписывались к категориям согласованости: (1) категории данных A, (2) категории данных C, (3) смеси категорий.
(1) Сначала мы включали все типы данных в категорию A, т.е. все транзакции над базой данных были изолированными и сохраняли согласованность данных. Такая категоризация данных соответствует требованиям тестового набора TPC-W.
(2) Потом мы объявляли все данные данными категории C. Транзакции над базой данных были только сессионно согласованными. Данные могли устаревать, а их согласованность – не сохраняться. В частности, поскольку покупка товаров совершалась не в монопольном режиме, могли возникнуть случаи продаж сверх имеющихся запасов.
Таблица 1. Разбиение данных на категории
| Данные | Категория |
| XACTS | A (очень ценные данные) |
| Item | B (зависит от объема запаса) |
| Customer | C (немного параллельных обновлений) |
| Address | C (немного параллельных обновлений) |
| Country | C (немного параллельных обновлений) |
| Author | C (немного параллельных обновлений) |
| Orders | С (только добавление, обновления отсутствуют) |
| OrderLine | С (только добавление, обновления отсутствуют) |
Эта смесь содержала данные категорий A, B и C. Разбиение на категории типов данных тестового набора TPC-W показано в табл. 1. Данные о кредитных картах (XACTS) отнесены к категории A. Данным о продуктах (Item) назначена категория B, поскольку в них содержится числовое значение, к которому можно относиться, как к порогу (объем запаса товара). Все прочие данные отнесены к категории C.
Стоимости. Во всех наших экспериментах база данных размещалась в S3, и клиенты подключались к этой базе данных через серверы приложений, которые выполнялись в среде EC2. Расходы времени выполнения определяются денежной стоимостью выполнения серверов приложений в среде EC2, хранения данных в S3 и подключения к нашим дополнительным службам (т.е. усовершенствованной службе очередей и службе блокировок). Стоимость использования EC2 и S3 определяется компанией Amazon. Стоимость подключения к нашим дополнительным службам и их использования определяется нами, и при этом мы следуем модели SQS (Simple Queue Service) компании Amazon. В частности, ценообразование нашей усовершенствованной службы очередей точно такое же, как у SQS версии WSDL 2008-01-01. Мы используем такие же цены, чтобы избежать различия между службами компании Amazon и нашими дополнительными службами. Стоимость запроса и возврата блокировки равна стоимости чтения сообщения из очереди в SQS. Мы измеряем стоимость выполнения в долларах в расчете на 1000 транзакций. Одна транзакция соответствует в точности одному действию, определенному в тестовом наборе TPC-W.
Убытки, вызываемые несогласованностью, – это расходы, которые несет компания в тех ситуациях, когда оказывается невозможно оказать клиентам обещанную услугу. В данном случае такие расходы связаны с продажей товаров сверх их наличного запаса. Такие заказы невозможно выполнить, и покупатели оказываются обманутыми. В крупных компаниях суммы таких расходов хорошо известны. Поскольку мы очень сильно нагружаем свою системы (см. ниже) сумма расходов, связанных с продажей отсутствующих товаров, была установлена в размере $00.1 в расчете на один ошибочно проданный продукт.
Общая стоимость состоит из расходов времени выполнения и расходов, вызываемых несогласованностью данных.
Параметры. В своих экспериментах мы использовали 10 серверов приложений, размещенных в среде EC2. Эти серверы приложений выполняли транзакции в соответствии со смесью действий Ordering mix, определенной в тестовом наборе TPC-W. Число видов товаров в системе равнялось 1000. Значения запасов каждого товара устанавливались равномерно распределенной случайной величиной в диапазоне от 10 до 100. Интервал между выполнениями операции контрольной точки равнялся 30 секундам. Таким образом, не более чем через каждые 30 секунд актуальная версия страницы записывалась в S3. Время жизни страницы равнялось 5 секундам. Размер окна Динамической политики был установлен в 80 секунд, а показатель скольжения – в 5 секунд.
Чтобы четко выявить индивидуальные характеристики различных категорий согласованности и стратегий переключения уровней согласованности, мы подвергли свою систему нагрузочному тестированию. За 300 секунд выполнения тестового набора продавалось до 12000 единиц товара. Это составляет больше четверти от всего доступного объема товаров. Такая нагрузка системы позволила нам получить стабильные и повторяемые результаты. Конечно, в сценариях реального мира нагрузка гораздо ниже, но зато выше расходы из-за продажи товаров сверх запаса. Для получения стабильных результатов при таких нагрузках требуется очень долгое время выполнение тестов, что делает почти невозможным детальное изучение производительности, и поэтому мы приводим только результаты, полученные при высокой нагрузке системы. Однако, при выполнении нами некоторых экспериментов с более реалистичными сценариями были получены вполне сравнимые результаты.
Эксперименты
В этом разделе описываются эксперименты, которые мы выполняли для изучения сравнительных характеристик разных политик согласованности. Наши эксперименты основывались на эталонном тестовом наборе TPC-W . Тестовый набор TPC-W моделирует Internet-магазин и направлен на сравнение производительности разных реализаций. Для всех своих тестовых испытаний мы сообщаем время ответа и стоимость транзакции. Эти результаты демонстрируют высокий потенциал рационализации согласованности.
Категория A – сериализуемость
Для данных категории A обеспечивается сериализуемость (serializability) в традиционном транзакционном смысле. Данные этой категории всегда остаются согласованными, и все транзакции, модифицирующие данные категории A, являются изолированными. В "облачной" среде хранения данных поддержка сериализуемости требует существенных денежных затрат и приводит к падению производительности. Эти накладные расходы стоимости и производительности возникают из-за того, что в сильно распределенных средах для поддержки сериализуемости требуются более сложные протоколы . Эти протоколы предусматривают большее число взаимодействий с дополнительными службами (например, службами блокировок и выполнения запросов), что приводит к повышению стоимости и падению производительности (увеличению времени ответа) по сравнению системами, работающими на уровне сессионной согласованности.
Данные следует относить к категории A, если их согласованность и актуальность являются обязательными. Мы обеспечиваем сериализуемость на основе использования пессимистического протокола (протокола двухфазных блокировок, 2PL). Мы выбрали сериализацию, а не, например, изоляцию на основе мгновенных снимков, чтобы транзакции всегда видели последнее по времени состояние базы данных.
Категория B – адаптивность
В промежутке между данными с сессионной согласованностью (C) и данными, для которых поддерживается режим сериализации (A), существует широкий спектр типов данных и приложений, для которых требуемый уровень согласованности зависит от конкретной ситуации. Иногда требуется строгая согласованность, а иногда она может ослабляться. Принимая во внимание двойное влияние транзакционной согласованности в условиях "облачных" баз данных (на стоимость и производительность), мы вводим категорию B, включающую все данные, для которых имеются требования адаптивной согласованности.
Кроме того, для многих приложений, которые могли бы исполняться в среде "облачной" базы данных, можно определить количество расходов, возникающих из-за несогласованности данных (см. сценарии использования, описанные выше). К таким расходам относятся возвраты платежей клиентам, которым доставлены не те товары, накладные расходы, возникающие при избыточном бронировании, затраты на аннулирование заказов и т.д. Расходы в этом смысле означают либо прямые денежные затраты, либо, например, сокращение клиентской базы или дополнительные административные усилия для разрешения конфликта. Поскольку не все обновления данных категории B приводят к возникновению конфликта (разд. 2), возможны нетривиальные компромиссы между расходами по вине несогласованности данных и преимуществами от использования ослабленной согласованности.
В нашей реализации для данных категории B во время выполнения осуществляются переключения между режимами сессионной согласованности и сериализуемости. Если случается так, что одна транзакция работает в режиме сессионной согласованности, а другая оперирует с той же записью данных категории B в режиме сериализуемости, то общим результатом является сессионная согласованность.
Далее в этой статье мы подробно анализируем различные политики переключения между этими двумя возможными гарантиями согласованности. Эти политики расчитаны на то, чтобы такое переключение выполнялось автоматически и динамически, сокращая, тем самым, для пользователя "облачной" инфраструктуры как стоимость выполнения транзакций, так и расходы, возникающие из-за несогласованности данных.
Категория C – сессионная согласованность
Категория C включает данные, для которых поддерживается сессионная согласованность (session consistency). Сессионная согласованность определяется как минимальный уровень согласованности в распределенной среде, не приводящий к чрезмерной сложности разработки приложений . При поддержке сессионной согласованности приложения не обязательно видят свои собственные изменения данных и при последующих обращениях могут получить несогласованные данные.
Клиенты подключаются к системе в контексте сессий. Пока длится сессия, система гарантирует монотонность по чтению собственных записей (read-your-own-writes monotonicity). Гарантии монотонности не распространяются за границы сессий. Если некоторая сессия завершается, в новой сессии могут быть сразу не видны записи, произведенные в предыдущей сессии. В сессии одного клиента могут быть не видны изменения, произведенные в сессии другого клиента. По истечении некоторого времени (и при отсутствии сбоев) система достигает устойчивого состояния, и данные становятся согласованными (это свойство, полезное в распределенных вычислениях, называется согласованностью "в конечном счете" (eventual consistency). Например, в службе S3 компании Amazon, направленной на хранение файлов, обеспечивается согласованность "в конечном счете".
Разрешение конфликтов, возникающих при параллельном обновлении данных категории C, производится в зависимости от типа обновления. В случае некоммутативных обновлений (например, замены значений данных) выигрывает последнее обновление. При коммутативных обновлениях (выполнении численных операций, например, сложения) конфликты разрешаются путем поочередного применения обновлений. Тем не менее, оба подхода могут привести к несогласованности, если, например, обновленные данные нарушают некоторое ограничение целостности.
При поддержке сессионной согласованности дешевле обходятся выполнение транзакций и обеспечение требуемого времени отклика системы, поскольку требуется меньшее число сообщений, чем при соблюдении гарантий строгой согласованности, например, сериализуемости. Кроме того, оказывается возможным кэширование данных, позволяющее еще больше снизить расходы и повысить производительность. В "облачных" базах данных данные всегда относятся к категории C, если несогласованность возникнуть не может (например, в любой момент времени над данными выполняются операции не более одной транзакции), или если возникновение временной несогласованности данных не вызывает финансовых или административных расходов.
Компонент статистики и политики
Компонент статистики отвечает за сбор статистики во время выполнения. Статистика собирается локально. На основе этой локальной информации компонент судит о глобальном состоянии (разд. 5). Используя эти суждения, одиночный сервер может принять решение об использовании того или иного протокола (т.е. протоколов сессионной согласованности или сериализуемости). Более строгая согласованность обеспечивается только в тех случаях, когда все серверы принимают решение об использовании согласованности категории A. Таким образом, если размер окна достаточно велик, и все запросы равномерно распределены по серверам, для принятия пригодных решений не требуется какой-либо центральный сервер. Однако консолизация статистики и периодическая веерная рассылка информации о принятых решениях могут сделать систему более устойчивой. В будущем мы планируем использовать эти приемы.
Для вероятностных политик требуются разные виды статистических данных. Общая политика обрабатывает записи, для которых маловероятны параллельные обновления на разных серверах с гарантиями уровня C. Поэтому для этой политики требуется информация о частоте обновлений, и для нее наиболее интересны редко обновляемые элементы данных. С другой стороны, для Динамической политики особенно интересны часто обновляемые элементы данных. Эта политика допускает частые параллельные обновления с гарантиями уровня C, пока вероятность достижения порогового значения не станет слишком высокой.
Для обеих этих политик мы сохраняем статистическую информацию прямо при записи. Для Общей политики мы сокращаем размер области памяти, требуемой для хранения статистики, за счет простой аппроксимации. Если нашей целью является достижение доли конфликтов менее 1%, то моделирование с использованием соотношения (3) из п 5.1.1 показывает, что интенсивность входного потока должна быть меньше, чем

Мы используем это свойство для сокращения числа разрядов, требуемых для хранения значения для одного кадра, и выделяем специальное значение для числа обновлений, большего того, которое помещается в выделенное число разрядов.
Например, если мы предположим, что размер окна равен одному часу, показатель скольжения равен 5 минутам, и размер интервала кэширования составляет 2 минуту, то потребуется хранить значения для двенадцати кадров окна. Средняя интенсивность обновлений в расчете на кадр должна быть

Операции сбора статистики достаточно просты: для каждой новой операции обновления требуется увеличить на единицу счетчик текущего кадра. Кадры обновляются циклическим образом, и специальный признак указывает на то, что данные явдяются новыми. Новые записи обрабатываются специальным образом: устанавливается флаг, позволяющий избежать неправильного поведения, пока для новой записи еще не собрано достаточное количество статистической информации.
Аналогичным образом проиводится сбор статистики для Динамической политики. Основным отличием является то, что собирается сумма обновлений, а не число операций. Поэтому объем памяти для хранения статистических данных невозможно оптимизировать так, как описывалось выше. По соображениям эффективности полная статистика собирается только для наиболее часто обновляемых записей. Все остальные записи обрабатываются с использованием порогового значения, назначенного для применения по умолчанию. Собираемая статистика имеет не очень большой объем и может сохраняться в основной памяти. Например, в системе с 10000 часто обновляемых записей категории B при наличии 100 кадров в окне и использовании 32 бит для хранения суммарных значений обновлений записей потребуется всего 10000 × 100 × 32 ≈ 4 мегабайта.
Оставшиеся вычисления описываются в разд. 5. Для уменьшения погрешности оценки мы свертываем точные функции распределения, если для некоторой записи в окне выполнялось менее 30 операций обновления. В противном случае, как описывалось в разд. 5, для сокращения вычислений используется аппрокимация на основе нормального распределения. Еще одной проблемой, свойственной Динамической политике, является начало работы системы, когда какая-либо статистика отсутствует. Эта проблема разрешается за счет использования в начале работы Политики разъединения и перехода к Динамической политике после накопления достаточного объема статистической информации.
Литература
28msec, Inc. Sausalito, Feb. 2009. Amazon. Simple Storage Service S3, Dec. 2008. D. Barbará and H. Garcia-Molina. The Demarcation Protocol: A Technique for Maintaining Constraints in Distributed Database Systems. VLDB J., 3(3):325–353, 1994. H. Berenson et al. A critique of ANSI SQL isolation levels. In Proc. of ACM SIGMOD, pages 1–10, Jun 1995. P. Bernstein, V. Hadzilacos, and N. Goodman. Concurrency Control and Recovery in Database Systems. Addison Wesley, 1987. M. Brantner, D. Florescu, D. A. Graf, D. Kossmann, and T. Kraska. Building a Database in the Cloud. Technical Report, ETH Zurich, 2009. M. Brantner, D. Florescu, D. A. Graf, D. Kossmann, and T. Kraska. Building a database on S3. In Proc. of ACM SIGMOD, pages 251–264, 2008. M. Cafarella et al. Data management projects at google. ACM SIGMOD Record, 37(1):34–38, 2008. Перевод на русский язык: Майкл Кафарелла, Эдвард Чанг, Эндрю Файкс, Элон Хэлеви, Вильсон Се, Альберто Лернер, Джаянт Мадхаван, С. Мутукришнан. Проекты по управлению данными в Google
F. Chang et al. Bigtable: A Distributed Storage System for Structured Data. In Proc. of OSDI, pages 205–218, 2006. S. S. Chawathe, H. Garcia-Molina, and J. Widom. Flexible Constraint Management for Autonomous Distributed Databases. IEEE Data Eng. Bull., 17(2):23–27, 1994. B. F. Cooper et al. PNUTS: Yahoo!’s hosted data serving platform. In Proc. of VLDB, volume 1, pages 1277–1288, 2008. L. Gao, M. Dahlin, A. Nayate, J. Zheng, and A. Iyengar. Application specific data replication for edge services. In Proc. of WWW, pages 449–460, 2003. D. Gawlick and D. Kinkade. Varieties of Concurrency Control in IMS/VS Fast Path. IEEE Database Eng. Bull., 8(2):3–10, 1985. J. Gray and A. Reuter. Transaction Processing: Concepts and Techniques. Morgan Kaufmann, 1994. J. Gray, P. Sundaresan, S. Englert, K. Baclawski, and P. J. Weinberger. Quickly generating billion-record synthetic databases. In Proc. of ACM SIGMOD, pages 243–252, 1994. H. Guo, P.-Å. Larson, and R. Ramakrishnan.
Caching with " good enough" currency, consistency, and completeness. In VLDB, pages 457–468, 2005. H. Guo, P.-Å. Larson, R. Ramakrishnan, and J. Goldstein. Relaxed Currency and Consistency: How to Say ”Good Enough” in SQL. In Proc. of ACM SIGMOD, pages 815–826, 2004. A. Gupta and S. Tiwari. Distributed constraint management for collaborative engineering databases. In CIKM, pages 655–664, 1993. P.-Å. Larson, J. Goldstein, and J. Zhou. MTCache: Transparent Mid-Tier Database Caching in SQL Server. In Proc. of ICDE, pages 177–189, 2004. J. Lee. SQL Data Services - Developer Focus (Whitepaper). 2008. Y. Lu, Y. Lu, and H. Jiang. Adaptive Consistency Guarantees for Large-Scale Replicated Services. In Proc. of NAS, pages 89–96, Washington, DC, USA, 2008. IEEE Computer Society. C. Olston, B. T. Loo, and J. Widom. Adaptive Precision Setting for Cached Approximate Values. In SIGMOD Conference, pages 355–366, 2001. P. E. O’Neil. The Escrow Transactional Method. TODS, 11(4):405–430, 1986. M. T. Ozsu and P. Valduriez. Principles of Distributed Database Systems. Prentice Hall, 1999. R. Kallman et all. H-store: a high-performance, distributed main memory transaction processing system. In Proc. of VLDB, pages 1496–1499, 2008. S. Shah, K. Ramamritham, and P. J. Shenoy. Resilient and Coherence Preserving Dissemination of Dynamic Data Using Cooperating Peers. IEEE Trans. Knowl. Data Eng., 16(7):799–812, 2004. E. A. Silver, D. F. Pyke, and R. Peterson. Inventory Management and Production Planning and Scheduling. Wiley, 3 edition, 1998. M. Stonebraker et al. Mariposa: A Wide-Area Distributed Database System. VLDB J., 5(1), 1996. M. Stonebraker et al. The end of an architectural era (it’s time for a complete rewrite). In Proc. of VLDB, pages 1150–1160, 2007. Перевод на русский язык: Майкл Стоунбрейкер, Сэмюэль Мэдден, Дэниэль Абади, Ставрос Харизопулос, Набил Хачем, Пат Хеллэнд. Конец архитектурной эпохи, или Наступило время полностью переписывать системы управления данными
A. T. Tai and J. F. Meyer. Performability Management in Distributed Database Systems: An Adaptive Concurrency Control Protocol. In Proc. of MASCOTS, page 212, 1996. A. Tanenbaum and M. van Steen. Distributed Systems: Principles and Paradigms. Prentice Hall, 2002. TPC. TPC-W Benchmark 1.8. TPC Council, 2002. W. Vogels. Data access patterns in the Amazon.com technology platform. In Proc. of VLDB, page 1, Sep 2007. G. Weikum and G. Vossen. Transactional Information Systems. Morgan Kaufmann, 2002. A. Yalamanchi and D. Gawlick. Compensation-Aware Data types in RDBMS, 2009. To appear in Proc. of ACM SIGMOD. H. Yu and A. Vahdat. Design and Evaluation of a Continuous Consistency Model for Replicated Services. In OSDI, pages 305–318, 2000.
Логическая журнализация
Чтобы обеспечить более высокий уровень параллелизма без порождения несогласованности, мы реализовали логическую журнализацию. Сообщение логического журнала содержит идентификатор модифицированной записи и код операции Op, выполненной над этой записью. Чтобы получить новое значение записи (например, при выполнении операции контрольной точки), операция Op из PU-очереди применяется к элементу данных.
В протоколах, представленных в , используется физическая журнализация. Логические обновления устойчивы по отношению к параллельно выполняемым обновлениям, если эти операции являются коммутационными. Другими словами, никакое обновление не потеряется из-за перезаписывания, и независимо от порядка выполнения будет виден эффект всех обновлений. Однако выполнение некоммутационных операций по-прежнему может привести к несогласованности. Чтобы избежать проблем с использованием разных классов коммутационных операций (например, умножения), мы ограничились в своей реализации сложением и вычитанием. Логическая журнализация работает только для числовых значений. Для нечисловых значений (например, строк) логическая журнализация ведет себя, как физическая журнализация (т.е. для строк выигрывает последнее обновление). В нашем подходе рационализации согласованности поддерживаются оба вида значений (см. разд. 5).
Метаданные
Для каждой коллекции в нашей системе сохраняются метаданные о ее типе. Эта информация наряду с самой коллекцией сохраняется в S3. Зная коллекцию, к которой относится запись, система устанавливает, какие гарантии согласованности требуется обеспечить. Если запись относится к категории A, то система знает, что для этого элемента данных должна применяться строгая согласованность. Если элемент же данных относится к категории C, то система работает с более низким уровнем гарантий. Для этих двух категорий данных (т.е. A и C) операции проверки типа оказывается достаточно для принятия решения о выборе протокола поддержки согласованности. Для данных категории B в метаданных содержится дополнительная информация: имя политики и дополнительные параметры для нее.
Модель
Предположим, что имеется распределенная система с n серверами (потоки управления (thread) считаются отдельными серверами), в которых реализуются разные уровни согласованности, описанные в разд. 3. Серверы кэшируют данные с использованием интервала кэширования (т.е. временем жизни) CI. В течение этого интервала данные категории C читаются из кэша без синхронизации. Кроме того, любые два обновления одного и того же элемента данных на разных серверах считаются конфликтом (при выполнении операций мы не используем семантическую информацию). Если мы дополнительно предположим, что все серверы ведут себя схожим образом (т.е. обновления равномерно распределены по серверам и не зависят одно от другого), то вероятность конфликтного обновления некоторой записи вычисляется по следующей формуле:

Здесь X – это случайная переменная, соответствующая числу обновлений одной и той же записи в течение интервала кэширования CI. P(X > 1) – это вероятность того, что в течение интервала кэширования CI произойдет более одного обновления одной и той же записи. Однако конфликт может возникнуть только в том случае, когда эти обновления производятся на разных серверах. Поэтому в части (ii) правой части соотношения вычисляется вероятность того, что обновления будут произведены в одном и том же сервере, и полученное значение вычитается из вероятности того, чтобы было произведено более чем одно обновление. В соотношении не учитывается вероятность возникновения двойного конфликта для одной и той же записи. Это связано с тем, что мы предполагаем наличие возможности распознавать и устранять конфликты (например, просто путем отбрасывания конфликтующих обновлений), а также считаем пренебрежимо малой вероятность возникновения двух конфликтов для одной и той же записи за время, которое требуется для обнаружения конфликта (например, время интервала кэширования).
Как и в , мы предполагаем, что поступление транзакций в систему является пуассоновским процессом, и это позволяет нам переписать соотношение (1) с использованием средней скорости потока (mean arrival rate) λ.
Для пуассоновского распределения функция плотности вероятности (probability density function, PDF) задается соотношением
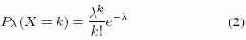
Поэтому соотношение (1) можно переписать следующим образом:

Если n > 1, и вероятность возникновения конфликта считается достаточно малой (например, не больше 1%), то вторым элементом (iv) правой части этого соотношения можно пренебречь (моделирование показывает, что при k > 3 составляющие этого элемента принебрежимо малы). Следовательно, в качестве верхней границы вероятности конфликта можно использовать значение следующего выражения:

Если требуется большая точность, можно учесть первые одно или два слагаемых из (iv).
Модель разработки
Рационализация согласованности приводит к усложнению процесса разработки приложений, выполяемых над "облачной" системой хранения данных. Во-первых, данные должны быть разделены (рационированы) на категории согласованности. Этот процесс производится на основе операционной стоимости транзакций и расходов, вызываемых несогласованностью данных. Во-вторых, требуемый уровень согласованности должен быть определен для коллекции данных (т.е. отношения) вместе с соответствующей политикой и всеми ограничениями целостности. Это можно сделать путем аннотирования схемы, аналогично тому, что предлагается в .
Мы думаем, что процессы разработки приложения и рационализации согласованности можно разделить. В течение процесса разработки предполагается наличие строгой согласованности. Программист будет следовать обычной модели программирования приложений баз данных с явно определяемыми транзакциями. Независимо от категоризации данных программист будет всегда задавать команду start transaction в начале транзакции и команду commit transaction в конце транзакции. При развертывании приложения данные рационируются в соответствии со стоимостью. Рационализация может производится специалистом не из отдела разработки. Конечно, при этом предполагается. что разделение разработки и рационирования не влияет на корректность системы. Вопрос о том, какими свойствами должно обладать приложение, чтобы можно было разделить процессы разработки и рационирования данных, в этой статье не обсуждается и заслуживает дополнительных исследований.
Общая политика
Общая политика работает на основе вероятности конфликтов. Путем отслеживания частоты обращений к элементам данных, можно вычислить вероятность возникновения конфликтных обращений. Более высокие уровни согласованности требуется обеспечить только в тех случаях, когда вероятность конфликтов достаточно велика.
Политика разграничения
Протокол разграничения (Demarcation protocol) изначально был предложен для реплицируемых систем. Идея этого протокола состоит в том, что каждому серверу назначается некоторый объем ценностей (например, часть запаса товаров), и весь объем ценностей распределяется между серверами. Каждый сервер может изменять свой локальный объем ценностей, но не выходить за локальные границы. Эти границы обеспечивают глобальную согласованность без потребности в коммуникации серверов. Если границы нарушаются, сервер должен запросить дополнительную долю от других серверов или синхронизоваться с ними для регулировки границ. Этот протокол гарантирует, что общий объем ценностей никогда не станет меньше некоторого порогового значения, и что координация будет производиться только при реальной потребности.
Мы можем перенять протокол разграничения следующим образом. У каждого сервера имеется некоторая доля ценностей, которые он может использовать без блокировок. Далее мы без потери общности будем предполагать, что для каждой записи предельным значением является ноль. Если n – это число серверов, и v – общий объем ценностей (например, размер запаса продуктов), то мы можем определить долю, которую сервер может использовать без строгой согласованности, как


Все серверы вынуждаются использовать строгую согласованность, только если им нужно использовать ценности в объеме, превышающем выделенную им долю. За счет применения строгой согласованности сервер видит текущее реальное значение, и несогласованности удается избежать. Поскольку все серверы выдут себя одинаковым образом и сокращают свой объем ценностей одним и тем же образом, этот метод гарантирует, что общий объем ценностей не станет отрицательным.
В контексте "облачных" служб Политика разграничения не всегда может обеспечивать должную согласованность, потому что предполагается, что серверы не могут осуществлять коммуникации в произвольный момент времени. Значения записей актуализируются только после истечения некоторого интервала времени (т.е.
интервала кэширования). Может случиться так, что сервер исчерпает выделенную ему долю и будет продолжать, например, продавать товары (теперь в режиме с блокировками), в то время как другой сервер будет продолжать продавать товары из своего все еще имеющегося запаса без блокировок. В таких ситуациях объем ценностей может сократиться ниже установленной границы. Тем не менее, идея, лежащая в основе протокола разграничения, является очень привлекательной, и можно предположить, что такие ситуации возникают крайне редко.
Дополнительным недостатком Политики разграничения является то, что при большом числе серверов n пороговое значение стремится к v. Тогда Политика разграничения будет трактовать данные категории B как данные категории A, и для большинства транзакций потребуются блокировки. Проблемой является и скошенное распределение данных: если некоторый элемент используется редко или неравномерно, пороговое значение может быть увеличено без соответствующего повышения расходов, вызываемых несогласованностью данных.
Политика с фиксированным пороговым значением
При использовании Политики с фиксированным пороговым значением, если значение некоторой записи меньше некоторого порогового значения, то эта запись обрабатывается при соблюдении строгих гарантий согласованности. Таким образом, транзакция, желающая вычесть некоторую величину Δ из некоторой записи, работает на уровне строгой согласованности, если разность между текущим значением v и Δ меньше порогового значения T или равна ему:

В отличие от Общей политики, в Политике с фиксированным пороговым значением не предполагается, что обновления, выполняемые на разных серверах, конфликтуют. Операции обновления коммутируют, и поэтому их можно выполнять корректно. Тем не менее, может возникнуть несогласованность, если суммарный эффект всех обновлений на разных серверах приводит к получению значения, меньшему порогового значения.
Аналогично нахождению оптимальной вероятности в Общей политике, можно оптимизировать и пороговое значение T. Простой способ нахождения оптимального порогового значения состоит в его экспериментальной настройке во времени. Другими словами, можно настраивать значение T до тех пор, пока не установится желаемый баланс между расходами времени выполнения и расходами, вызываемыми несогласованностью данных. Чтобы найти хорошее исходное значение T, всегда можно проанализировать статистику отдела продаж соответствующей компании. Обычно в отделах продаж применяются похожие методы для определения цен или управления запасами.
Наибольшим недостатком Политики с фиксированным пороговым значением является статический характер порога. Если изменяются потребности в каком-либо продукте, или какие-то продукты отличаются особой привлекательностью, Политика с фиксированным пороговым значением ведет себя не оптимальным образом (см. описание эксперимента 2 в разд. 7).
Политики адаптации
В этом разделе мы описываем пять разных политик адаптации гарантий согласованности, обеспечиваемых для отдельных элементов данных категории B. Во всех случаях адаптация состоит в переключении с уровня сериализуемости (категория A) на уровень сессионной согласованности (категория B) и наоборот. Политики различаются способами определения потребности в переключении. Например, Общая политика (General policy) основывается на исследовании вероятности конфликта на заданном элементе данных, и переключение на уровень сериализуемости происходит, если эта вероятность достаточно велика. Политика, основанная на времени, (Time policy) вызывает переключение между уровнями гарантии согласованности на основе времени; обычно работа выполняется на уровне сесионной согласованности до некоторого заданного момента времени, а затем производится переключение на уровень сериализуемости. Эти две первые политики могут применяться к любому элементу данных независимо от его типа.
Для очень распространенного случая числовых данных (например, данных о ценах и запасах) мы предлагаем три дополнительные политики. Политика фиксированного порогового значения (Fixed threshold policy) приводит к переключению уровня гарантий на основе абсолютной величины элемента данных. Поскольку эта политика зависит от порогового значения, который может оказаться трудно определяемым, в последних двух политиках используются более гибкие пороги. В Политике разграничения (Demarcation policy) анализируются относительные величины с учетом глобального порогового значения, а в Динамической политике (Dynamic policy) используются идеи Общей политики применительно к числовым данным, для которых анализируются частота обновлений и реальные значения элементов данных.
Политики для числовых типов
Во многих сценариях использования большинство конфликтующих обновлений связано с числовыми величинами. К числу примеров таких величин относятся объем запаса товаров в магазине, число доступных билетов в системе резервирования, остаток на счету в банковской системе. Для подобных сценариев часто характерно наличие некоторого ограничения целостности, определяющего предельно допустимые значения данных (например, объем запаса товаров должен быть неотрицательным), и коммутационных операций обновления (например, сложение, вычитание). Эти характеристики позволяют нам оптимизировать Общую политику за счет анализа реальных обновляемых значений для принятия решения о требуемом уровне согласованности. Это можно сделать с применением одной из трех следующих политик. Политика с фиксированным пороговым значением (Fixed threshold policy) основывается на сравнении реальных значений элементов данных и их сравнении с пороговым значением. В Политике разграничения (Demarcation policy) применяется идея протокола разграничения (Demarcation protocol) , и для принятия решения анализируется некоторый диапазон значений. Наконец, в Динамической политике (Dynamic policy) модель конфликтов Общей политики расширяется применительно к числовым типам.
Политики, основанные на времени
Такая политика основывается на временной метке, достижение которой означает необходимость изменения гарантий согласованности. Все сценарии использования подобных политик напоминают сценарий аукциона, в котором уровни согласованности повышаются при приближении к крайнему сроку.
Простейшая политика, основанная на времени, состоит в установке некоторого предопределенного значения (например, 5 минут). До момента времени, на пять минут меньшего крайнего срока, данные обрабатываются только на уровне сессионной согласованности. После этого происходит переключение на уровень строгой согласованности. Тем самым, эта политика работает так же, как и расcматриваемая ниже Политика фиксированного порогового значения за тем исключением, что решение о смене гарантий согласованности основывается на времени, а не на значении.
Как и раньшего, очень важно правильно определить это пороговое значение. Аналогично Общей политике, мы можем определить вероятность конфликта Pc(XT). Различие состоит в том, что случайная переменная XT изменяется во времени t.
В этом контексте часто не имеет смысла собирать статистику для записей. Например, в случае аукциона число обращений к записи возрастает по мере приближения к крайнему сроку, а после его достижения падает до нуля. Поэтому простой метод установки порогового значения состоит в анализе выборочного набора проведенных ранее аукционов и получении вероятности возникновения конфликта в момент времени t до наступления крайнего срока. Более развитые методы можно позаимствовать из областей управления запасами или маркетинга, поскольку аналогичные задачи решаются при предсказании жизненного цикла продуктов. Однако в этой статье такие методы не обсуждаются.
Рационализация согласованности
Сценарии использования, рассмотренные в разд. 2, показывают, что не для всех данных требуются одни и те же гарантии согласованности. Этот факт хорошо известен в области стандартных приложений баз данных, и ситуация регулируется за счет обеспечения разных уровней согласованности различным транзакциям. Хотя можно ослабить любое из свойств ACID (Atomicy, Consistency, Isolation, Durability), в этой статье мы фокусируемся на изоляции (Isolation) и согласованности (Consistency) в предположении, что атомарность (Atomicy) и долговечность хранения (Durability) обеспечиваются.
В направлении ослабления гарантий согласованности получены ценные результаты как в области распределенных систем (например, согласованность "в конечном счете" (eventual consistency), монотонность чтения-записи (read-write monotonicity) и сессионная согласованность (session consistency) ), так и в области управления транзакциями (например, режимы чтения зафиксированных данных (read committed), чтения незафиксированных данных (read uncommitted), сериализуемости (serializability) и (обобщенный) метод изоляции на основе мгновенных снимков (snapshot isolation) ). Основной вывод, который можно сделать на основе этих работ, состоит в том, что назначением моделей ослабленной согласованности является обеспечение наилучшего соотношения затрат и прибыли при сохранении понимаемого разработчиками поведения приложений. Имея это в виду, мы рассматриваем только два уровня согласованности (сессионная согласованность и сериализуемость) и подразделяем данные на три категории.
Рационализация согласованности в "облаках": не платите за то, что вам не требуется
Тим Краска, Мартин Хеншель, Густаво Алонсо, Дональд Коссман
Перевод: Сергей Кузнецов
Оригинал: Tim Kraska, Martin Hentschel, Gustavo Alonso, Donald Kossmann. Consistency Rationing in the Cloud: Pay only when it matters. Proceedings of the 35th VLDB Conference, August 24-28, 2009, Lyon, France
Реализация
В этом разделе описывается реализация рационализации согласованности поверх Simple Storage Service (S3) компании Amazon. Реализация основана на архитектуре и протоколах, представленных в . В системе, описанной в , уже обеспечиваются разные уровни согласованности поверх Amazon S3, и имеется коммерческий вариант этой системы под названием Sausalito . В конце раздела также приводятся краткие соображения относительно возможности реализации рационализации согласованности на других платформах, таких как PNUTS компании Yahoo.

Рис. 1. Архитектура
Реализация протоколов
Основная идея, направленная на достижение более высокого уровня согласованности поверх S3, состоит во временной буферизации обновлений страниц в очередях, показанных на шаге 1 на рис. 2. Очереди, используемые на первом шаге, называются очередями отложенных обновлений (pending update queue, PU-очередь). По истечении некоторого интервала времени один из серверов монопольным образом сливает обновления, буферизованные в PU-очереди, с соответствующей страницей S3, предварительно запрашивая для этой очереди блокировку. Это называется операцией контрольной точки (checkpointing, шаг 2 на рис. 2).
Реализационные альтернативы
Архитектура в основывается на предположении об использовании службы хранения данных, обеспечивающей гарантии согласованности "в конечном счете". Более высокие уровни согласованности достигаются за счет использования дополнительных служб и протоколов. В последнее время появилось несколько систем, которые сами обеспечивают гарантии согласованности более высокого уровня (например, PNUTS компании Yahoo ).
В PNUTS поддерживается более развитый API с операциями типа Read-any, Read-latest, Test-and-set-write (required version) и т.д. С использованием этих примитивов можно реализовать сессионную согласованность прямо поверх "облачной" службы без потребности в дополнительных протоколах и очередях. Средствами такого API невозможно реализовать сериализуемость, но в PNUTS имеется операция Test-and-set-write (required version), на основе которой можно реализовать оптимистическое управления параллелизмом доступа к данным категории A. Описываемые в статье средства управления метаданными, сбора и обработки статистики и поддержки политик можно было бы легко приспособить для использования и в такой среде. Но, к сожалению, Yahoo PNUTS не является общедоступной системой. Поэтому мы не имели возможности более детально проработать реализацию и/или включить эту систему в состав своих экспериментов. Тем не менее, разработчики PNUTS утверждают, что, например, Read-any является более дешевой операцией, чем Read-latest. Следовательно, в этой системе поддерживается такой же баланс между стоимостью и согласованностью, и к PNUTS можно было бы применить рационализацию согласованности для оптимизации стоимости и производительности.
Еще одной новой системой является Microsoft SQL Data Services . В этой службе в качестве базовой системы используется MS SQL Server, а сама служба основана на схемах репликации и балансировки нагрузки. За счет использования MS SQL Server система может обеспечивать строгую согласованность. Однако в этой системе имеются сильные ограничения: данные не могут распределяться по нескольким серверам, а транзакции не могут распространяться на несколько машин.
Поэтому масштабируемость системы ограничена.
Рационализацию согласованности можно было бы реализовать и внутри Microsoft SQL Data Services. В частности, введение категорий A и C, а также простых стратегий типа Политики разъединения могло бы помочь повысить производительность. Однако поскольку в этом случае строгая согласованность достигается более дешевым способом (не требуется обмен сообщениями между серверами), выигрыш, скорее всего, был бы далеко не так велик, как в реальной распределенной среде, где объем данных может возрастать неограниченным образом, и данные могут распределяться между несколькими машинами.
Наконец, рационализация согласованности могла бы хорошо подойти и для традиционных распределенных систем баз данных, в частности, для кластерных решений. Если ослабление согласованности является приемлемым, рационализация согласованности может помочь уменьшить число сообщений, требуемых для обеспечения строгой согласованности. И в этом случае можно было бы прямо применить большинство компонентов нашей системы.
Родственные работы
В литературе, посвященной тематике распределенных систем и баз данных, предлагалось много моделей транзакций и согласованности. В литературе из области баз данных к наиболее часто упоминаемым источникам относятся , и . В области распределенных систем стандартным является учебник, в котором описываются альтернативные модели согласованности, а также свойственные им соотношения согласованности и доступности. В нашей работе эти традиционные модели расширяются за счет возможности определения уровней согласованности на основе данных и изменения гарантий согласованности во время выполнения.
Подходы, наиболее близкие к тому, что мы предлагаем в этой статье, описываются в , и . В представлена инфрастуктура для обеспечения адаптивных гарантий согласованности данных на основе обнаружения случаев их несогласованности (Infrastructure for DEtection-based Adaptive consistency guarantees, IDEA). При обнаружении несогласованностей IDEA устраняет их, если текущий уровень согласованности не удовлетворяет определенным требованиям. В отличие от этого, наш подход направлен на то, чтобы с самого начала избегать возникновения несогласованностей за счет использования информации времени выполнения. В предлагаются набор показателей, покрывающих весь спектр согласованности (например, числовая ошибка, ошибка порядка), и различные протоколы, поддерживающие разные виды согласованности. Эти протоколы похожи на политику разграничения (п. 5.3.2). Однако в упор делается на обеспечение максимально допустимого отклонения значения от того, каким оно должно было бы быть при поддержке строгой согласованности. В своей работе мы сосредотачиваемся на поддержке определенных ограничений согласованности (например, размер запасов должен быть ненулевым). В авторы подразделяют данные на категории, для которых обеспечиваются разные стратегии репликации. Предлагаемая стратегия репликации для данных об объеме запасов снова похожа на политику разграничения, но является более консервативной, поскольку она никогда не приводит к продаже продукта сверх имеющихся запасов, а при некоторых обстоятельствах может даже не позволить продать имеющийся товар.
Понятие категории данных B до некоторой степени напоминает IMS/FastPath и транзакционную модель Escrow . В модели Escrow сокращается продолжительность блокировок, и допускается параллельное выполнение большего числа транзакций за счет отправки при начале транзакции в центральную систему некоторых предикатов. Если центральная система принимает эти предикаты, то в пределах этой транзакции можно считать, что их истинность сохранится без удержания блокировок. По сравнению с этим, в IMS/FastPath не гарантируется, что истинность предикатов сохранится на протяжении всей транзакции. Вместо этого предикаты заново вычисляются во время фиксации транзакции. Оба подхода гарантируют строгую согласованность. Мы расширяем идеи IMS/FastPath и Escrow путем введения понятий вероятностных гарантий и и адаптивного поведения. Кроме того, в IMS/FastPath и Escrow требуется глобальная синхронизация для упорядочивания поступления предикатов, а в своем подходе мы везде, где можно, избегаем синхронизации.
Аналогичным образом, большая работа в направлениях распределенных ограничений согласованности и лимитирования расхождений реплик была выполнена в и соответственно. При распределенном управлении ограничениями согласованности либо обеспечивается строгая согласованность, либо согласованность ослабляется на небольшие промежутки времени, что, в свою очередь, может привести к несогласованности данных. В работах, посвященных лимитированию расхождений реплик, для повышения производительности ослабляются критерии согласованности реплик, но в то же время ограничиваются расхождения между репликами (например, по значениям или времени последнего обновления). Мы расширяем эти подходы посредством вероятностных гарантий согласованности и использования в качестве целей оптимизации производительности и стоимости.
В авторы предлагают метод реализации ограничений согласованности локальных кэшированных копий в системах обработки SQL-запросов. При таком подходе пользователи читают данные из локальных устаревших мгновенных снимков данных, если эти данные находятся в пределах границ, определяемых ограничениями согласованности.
Все записи перенаправляются в основное хранилище, для чего требуются традиционные транзакционные модели. В нашей работе не требуется централизованное хранилище, и идеи расширяются понятием вероятностных грарантий.
Система Mariposa – это распределенная система управления данными, в которой поддерживается высокий уровень мобильности данных . В Mariposa на стороне клиентов могут храниться кэшированные копии элементов данных. Все записи в элемент данных должны выполняться над основной копией. Модель стоимости в Mariposa определяет, где располагается основная копия. Наша работа ортогональна по отношению к Mariposa, потому что мы не занимаемся локальностью данных и концентрируемся на изменении протоколов согласованности во время выполнения.
Авторы предлагают адаптивное управление параллелизмом на основе стохастической модели. Однако в их модели не принимается во внимание несогласованность. Вместо этого реализация переключается с оптимистического управления параллелизмом на пессимистическое управление и наоборот при обеспечении одного и того же уровня гарантий.
В H-Store предпринимается попытка полностью избежать любого вида синхронизации за счет анализа транзакций и разделения данных. В H-Store обеспечиваются гарантии строгой согласованности, но требуется заранее знать все запросы и транзакции. Мы не делаем подобного предположения. Кроме того, может оказаться возможным объединить эти два подхода, добившись соответствующего повышения производительности.
Исследования, описываемые в этой статье, мотивируются, главным образом, наличием "облачных" служб баз данных с точными ценовыми показателями (в денежном выражении) в расчете на одну транзакцию. В Simple Storage Service компании Amazon и BigTable компании Google обеспечиваются гарантии согласованности "в конечном счете" (eventual consistency). В последнее время некоторые исследовательские работы фокусируются на обеспечении более строгих гарантий. В PNUTS компании Yahoo обеспечиваются гарантии монотонности и изоляция с использованием мгновенных снимков на уровне записей.Мотивация этой работы аналогична нашей: чем выше уровень согласованности, тем выше стоимость и ниже производительность. В MegaStore компании Google и SQL Data Services компании Microsoft обеспечиваются транзакционные гарантии, но с ограничениями на размер данных (например, при использовании SQL Data Services транзакционные гарантии обеспечиваются только при размере данных в пределах одного гигабайта на контейнер). Но даже для поставщиков услуг, обеспечивающих гарантии согласованности более высокого уровня, насущным остает вопрос стоимости, поскольку поддержка более высокого уровня согласованности означает более высокую стоимость транзакций.
Сценарии использования
Потребность в разных стратегиях поддержки согласованности данных легко выявляется в различных приложениях и уже исследовалась в других контекстах (например, в , ). Ниже мы представляем различные сценарии, в которых можно было бы применить рационализацию согласованности.
Internet-магазин. Допустим, что на основе "облачной" службы хранения построен традиционный Internet-магазин. Программное обеспечение типичного Internet-магазина сохраняет различные виды данных . Например, имеются данные о профилях пользователей и информация о кредитных картах, данные о продаваемых продуктах и записи о предпочтениях пользователей (например, "пользователи, покупающие данный товар, также покупают то-то и то-то"), а также журнальная информация. Эти примеры уже показывают, что имеются разные категории данных в зависимости от их значимости и потребности в согласованности. Информация о кредитных картах пользователей и ценах товаров должна поддерживаться очень тщательно. В то же время, данные о предпочтениях пользователей и журнальная информация могут быть утрачены без какого-либо серьезного вреда (например, если возникает аварийный отказ системы, и данные из кэша не выталкивались на диск).
Разработчики такого Internet-магазина могли бы использовать рационализацию согласованности следующим образом:
Учетная информация считается относящейся к категории данных A, и доступ к таким данным осуществляется при соблюдении гарантий строгой согласованности (т.е. сериализуемости).
Данные о наличном количестве товаров относятся к категории данных B. При наличии достаточно больших запасов система допускает некоторую несогласованность данных. Если объем запасов становится ниже некоторого порога, доступ к данным производится с соблюдением гарантий строгой согласованности, чтобы избежать продаж сверх имеющихся запасов.
Предпочтения покупателей и журнальная информация классифицируются, как данные категории C. Системе не требуется видеть последнее по времени состояние большинства таких данных, а для их изменения не обязательно нужно предоставлять монопольный доступ к ним.
Поскольку общая стоимость поддержки функционирования такого Internet-магазина в "облачной" среде определяется стоимостью выполнения отдельных операций, применение рационализации согласованности непременно снизит общую стоимость за счет использования во всех возможных случаях более дешевых операций, минимизируя в то же время затраты, вызываемые несогласованностью данных.
Той же модели функционирования, что и Internet-магазины, следуют системы резервирования билетов в театры и кино, а также системы бронирования авиабилетов. Единственным отличием является то, что затраты на устранение последствий несогласованности (например, продаж лишних билетов) могут оказаться гораздо более высокими, чем в случае Internet-магазина. Преимущество рационализации согласованности состоит в том, что она позволяет разработчикам согласовать функцию стоимости и стратегии адаптации для оптимизации общих операционных расходов. В нашем подходе транзакции не обязаны работать с данными только одной категории, а могут охватывать несколько категорий данных (подраздел 4.4). Это позволяет разделять (рационировать) данные для оптимизации общих расходов с использованием любой схемы разделения.
Система поддержки проведения аукционов. Для онлайновой системы поддержки проведения аукционов типичным является то, что предмет, продаваемый с аукциона, набирает популярность на финальных стадиях своей продажи. Наибольший интерес для аукционеров представляют последние минут продажи предмета с аукциона. В этот период времени текущая цена предмета должна точно соответствать последнему предложению аукционеров, и она должна изменяться при соблюдении гарантий строгой согласованности. Если до конца продажи предмета с аукциона остается еще несколько суток, то предлагаемая цена может изменяться с использованием более низких уровней согласованности без оказания на систему какого-либо эффекта.
В системе проведения аукционов эту информацию можно использовать для реализации различных стратегий для поддержки актуальных данных о предмете, продаваемом на аукционе.
Если аукцион заканчивается в ближайшем будущем (например, через один или два часа), для этих данных должна обеспечиваться строгая соглсованность. И наоборот, если до конца аукциона остается еще много времени, для данных об предмете аукциона достаточно соблюдение более низких гарантий согласованности.
Различие между сценариями системы поддержки аукциона и Internet-магазина состоит в том, что выбор протокола согласованности производится на основе времени, а не значимости данных. В данном случае именно время используется в качестве порога, определяющего, какого рода гарантии согласованности следует выбрать. В отличие от этого, в примере с Internet-магазином в качестве порога использовалась значимость элемента данных.
Совместное редактирование. Средства совместного редактирования (Collaborative Editing) позволяют людям одновременно работать над одними и тем же документами или исходными текстами программ (к таким средствам относятся, например, Google Docs, системы управления версиями, Wiki и т.д.). Основная функциональность такой системы состоит в выявлении конфликтов, возникающих в процессе редактирования, и отслеживании истории изменений. Традиционно такие системы работают на уровне строгой согласованности. Если система обнаруживает конфликт, то от пользователя обычно требуется его устранение. Только после устранения конфликта пользователю предоставляется возможность внести изменение, если к этому времени не образовался какой-либо другой конфликт. Хотя в реальных ситуациях могут иметься некоторые части документа, часто изменяемые участниками процесса редактирования (например, цитаты из какой-либо статьи), люди обычно стараются организовать материал таким образом, чтобы избегать конфликтов с самого начала. Поэтому для большинства частей документа конфликты маловероятны, и не требуется никакого управления параллелизмом. В отличие от этого, для тех частей, которые часто изменяются несколькими участниками, лучше всего было бы соблюдать гарантии строгой согласованности, чтобы избежать всех конфликтов.
В отличие от предыдущих примеров, в данном случае выбор протокола согласованности основывается на вероятности конфликтов, в не на значимости или времени. В нашей общей политике, описываемой в подразделе 5.1, проблемы этого случая разрешаются путем автоматического применения стратегии, основанной на частоте обновлений.
Сериализуемость
Для обеспечения сериализуемости, требуемой для данных категории A, мы реализовали двухфазный протокол блокировок (two-phase locking protocol, 2PL). 2PL особенно устойчив к высокой частоте возникновения конфликтов и поэтому хорошо подходит в ситуациях, в которых конфликты ожидаются. Чтобы обеспечить права монопольного доступа, требуемые 2PL, мы реализовали службу блокировок. Чтобы всегда видеть наиболее последнее по времени состояние записей, мы были вынуждены реализовать усовершенствованную службу очередей, обеспечивающую более высокий уровень гарантий, чем Amazon Simple Queue Service. В частности, любое сообщение в любое время можно изъять из очереди, и идентификаторы сообщений монотонно возрастают.
Возрастание значений идентификаторов в нашей службе очередей позволило нам упростить протокол монотонности, представленный в . Для гарантирования монотонности достаточно сохранить в странице только изменения, соответствующие сообщению с наибольшим идентификатором. Если система считывает в S3 страницу с меньшим идентификатором, мы знаем, что эта страница нуждается в обновлении. Чтобы привести страницу в актуальное состояние, из очереди выбираются все сообщения, и применяются только сообщения с идентификаторами, большими идентификатора страницы.
Поскольку в этой статье мы фокусируемся на переключении протоколов согласованности во время выполнения, мы не будем больше говорить о реализациях 2PL, монотонности и усовершенствованных служб. Больше информации можно найти в .
Сессионная согласованность
В уже обсуждался протокол, обеспечивающий монотонность по чтению собственных записей (read-your-writes monotonicity). Идея состоит в том, чтобы для каждой страницы, которую сервер в прошлом кэшировал, сохранялась временная метка последней фиксации. Если сервер получает от S3 старую версию страницы (старше версии, которую сервер видел ранее), он выявляет это и читает страницу из S3 заново.
Сессионную согласованность обеспечивает перенаправление в течение сессии всех запросов от одного клиента к одному и тому же серверу. В нашей реализации такая маршрутизация производится на основе использования идентификаторов сессий и соответствующей переадресации запроса.
До постановки сообщений в очереди в них включаются векторные часы (vector clocks), которые проверяются вместе с ограничениями целостности во время выполнения операции контрольной точки для выявления и, при необходимости, устранения конфликтов.
Смеси категорий
В нашей "облачной" инфраструктуре баз данных гарантии согласованности обеспечиваются для данных, а не для транзакций. Это мотивируется тем, что у данных имеются разные стоимостные характеристики. Например, для данных о банковских счетах и запасах требуется изоляция, а для журнальных данных или профилей клиентов – нет. Определение согласованности на данных, а не на транзакциях позволяет обращаться с данными в соответствии с их важностью. Однако побочным эффектом этого подхода является то, что транзакции при доступе к разным данным могут выдеть разные уровни согласованности.
Если в одной транзакции обрабатываются данные разных категорий, то каждая запись, затрагиваемая этой транзакцией, обрабатывается в соответствии с гарантиями согласованности, свойственными категории этой записи. Поэтому операции чтения данных категории A получают согласованные данные, а операции записи оставляют их в согласованном состоянии. При чтении данных категории A всегда выбираются актуальные данные. При чтении данных категории C в зависимости от эффектов кэширования могут выбираться устаревшие данные. Логическим следствием является то, что для результатов операций соединения, объединения и т.д. данных категорий A и C обеспечиваются только гарантии категории C. В большинстве ситуаций это не приносит вреда и является ожидаемым/желательным поведением. Например, в результате соединения данных об остатках на счетах (данные категории A) и данных о профилях клиентов (данные категории C) будет содержаться только актуальная информация о балансах счетов, но, возможно, устаревшие данные об адресах клиентов.
Если это необходимо с точки зрения приложения, для транзакций можно указать требуемые им гарантии. Это позволяет транзакции видеть актуальное состояние любой записи. Однако это не гарантирует, что у этой транзакции имеется монопольное право на обновление этой записи. Если одна транзакция производит запись в режиме сессионной согласованности, а другая – в режиме сериализуемости, то все равно может возникнуть несогласованность.
Темпоральная статистика
Для вычисления вероятности конфликта во время выполнения без потребности в какой-либо централизованной службе в каждом сервере собирается темпоральная статистика по поводу запросов. Мы используем скользящее окно (sliding window) размера w с показателем скольжения (sliding factor) δ. Размер окна определяет число содержащихся в нем интервалов. Показатель скольжения указывает гранулярность перемещения окна. Для каждого временного окна подсчитывается число обновлений всех данных категории B. Все завершившиеся интервалы окна образуют гистограмму обновлений. Размер окна действует как показатель сглаживания (smoothing factor). Чем больше размер окна, тем лучше статистика, и тем больше требуется времени для адаптации к изменению скоростей потоков. Показатель скольжения влияет на гранулярность гистограммы. Для простоты мы считаем, что показатель скольжения δ кратен интервалу кэширования CI. Чтобы получить на основе локальных статистических данных скорость потока для всей системы λ, достаточно вычислить среднее арифметическое значение


Поскольку статистика собирается с использованием скользящего окна, система может динамически адаптироваться к изменениям в характере доступа.
Поскольку частота обновлений элемента данных, который разумно было бы отнести к категории C, должна быть небольшой, при малых размерах окна локальная статистика может легко исказить глобальную статичтику. Для преодоления этой проблемы можно соединять локальную статистику в централизованную картину. Проще всего добиться этого, периодически рассылая локальную статистику всем серверам. Кроме того, если при самой записи содержится соответствующая статистическая информация (см. разд. 6), такая широковещательная рассылка явно и не требуется. При связывании информации с записью статистическая информация может собираться, когда соответствующий элемент данных кэшируется.
Транзакционные данные в облаках – синергия идей СУБД и распределенных систем
Все более широкое распространение сервис-ориентированной архитектуры приложений, коммунальных компьютерных служб и "облачных" сред приводит, с одной стороны, к возрастающей привлекательности этих подходов для разработчиков и пользователей приложений баз данных, а другой стороны (возможно, в качестве следствия) – к повышающейся интенсивности соответствующих исследований в сообществе баз данных. В этих исследованиях развиваются и/или пересматриваются многие идеи, методы и алгоритмы, которые использовались при организации систем баз данных в течение десятилетий, и все это представляется мне потрясающе интересным.
По сути дела, такие исследования ведутся в двух направлениях, которые, судя по публикациям, развиваются практически независимо: "облачные" средства управления аналитическими данными и "облачные" системы поддержки транзакционных приложений баз данных. Первому направлению, в частности, посвящены статьи Майкла Стоунбрейкера и др. и
,
Джо Хеллерстейна и др. , Эрика Фридмана и др. ,
Ави Зильбершаца и др. .
Я старался комментировать свои переводы этих статей, по поводу одной из них написал отдельную заметку , частично обсуждал предлагаемые подходы в статье , но, похоже, что следует провести специальный анализ этого направления, постараться более подробно классифицировать и сравнить имеющиеся подходы.
По поводу второго направления мы тоже публиковали переводы наиболее интересных статей: Майкла Стоунбрейкера и др. и
,
Даниелы Флореску и Дональд Коссмана .
В этой статье нас интересуют возможности реализации средств типа систем баз данных поверх "облачного" хранения данных. В этом контексте невозможно избежать уровня строгой согласованности. Основное наблюдение, на котором основывается исследование, описываемое в статье, состоит в том, что не все данные требуется обрабатывать на одном и том же уровне согласованности. Например, в Internet-магазине для информации о кредитных картах и состоянии счетов, естественно, требуются более высокие уровни согласованности, а данные о предпочтениях пользователей (например, пользователи, покупающие данный товар, также покупают то-то и то-то) можно обрабатывать на более низких уровнях согласованности.
Это разграничение является важным, поскольку в облачной системе хранения данных согласованность означает не только корректность данных, но и реальный размер расходов на выполнение транзакций.
Стоимость конкретного уровня согласованности можно измерить в терминах числа системных вызовов, требуемых для его поддержки. Поскольку существующие платформы обеспечивают только базовые гарантии, дополнительные уровни согласованности (значительно) повышают стоимость выполнения каждой операции. Аналогично, стоимость несогласованности данных можно измерить в терминах процентного соотношения числа некорректных операций, выполняемых из-за поддержки более низких уровней согласованности. Это процентное соотношение часто можно точно отобразить в соответствующие денежные расходы (например, убытки в связи с компенсацией ущерба от ошибочно выполненных заказов или потерей заказчиков). Объемы таких расходов обычно хорошо известны компаниям, предоставляющим подобные услуги.
Нахождение правильного баланса между стоимостью, согласованностью и доступностью является нетривиальной задачей. В крупномасштабных системах обеспечение высокого уровня согласованности приводит к высокой стоимости транзакций и сниженному уровню доступности , но позволяет избежать убытков от некорректно выполненных операций. Низкий уровень согласованности означает более низкую стоимость выполнения операций, но может привести к большим убыткам (например, при продаже товаров в Internet-магазине сверх имеющихся запасов). Эта ситуация усложняется тем, что упомянутый баланс зависит от нескольких факторов, включая семантику приложений. В этой статье мы предлагаем путь к обходу этой дилеммы за счет использования динамической стратегии поддержки согласованности: снижение требований к согласованности, когда это возможно, (например, это не приведет к большим убыткам) и повышение их, когда это разумно (например, убытки могут оказаться слишком большими). Такая адаптация управляется моделью стоимости и разными стратегиями, которые диктуют требуемое поведение системы.
Мы называем этот подход рационализацией согласованности (Consistency Rationing) по аналогии с рационализацией запасов (Inventory Rationing). Рационализация запасов – это стратегия управления запасами, при которой запасы отслеживаются с разной точностью в зависимости от наличного числа инвентарных объектов. Следуя этой идее, мы разделяем данные на три категории (A, B и C) и обращаемся с каждой категорией по-своему в зависимости от обеспечиваемого уровня согласованности.
Категория A содержит данные, нарушение согласованности которых привело бы к крупным убыткам. К категории C относятся данные, (временная) несогласованность которых является приемлемой (т.е. либо несогласованность данных вызовет лишь небольшие убытки, либо в действительности несогласованность не возникает). Категория B включает все данные, требования к согласованности которых изменяются во времени в зависимости, например, от реальной доступности некоторого элемента. Обычно такие данные параллельно изменяются многими пользователями и часто являются узким местом в системе. В этой статье мы фокусируемся на категории B. Именно для этой категории можно добиться оптимального соотношения расходов на выполнение операций и обеспечиваемого уровня согласованности. Мы описываем несколько сценариев использования, обосновывающих выделение такой категории данных B. Затем мы излагаем модель стоимости системы и обсуждаем различные стратегии динамического изменения уровней согласованности в зависимости от потенциальных убытков. Эти стратегии направлены на минимизацию общей стоимости выполнения операций над "облачной" системой хранения данных. Наши эксперименты с "облачным" сервисом, реализованным поверх службы S3 компании Amazon, показывают, что динамические политики, которые описываются в этой статье, могут принести значительную экономию затрат. Основным вкладом статьи является следующее:
Вводится понятие рационализации согласованности (Consistency Rationing), позволяющее приложениям получать требуемые уровни согласованности с наименьшими возможными затратами.
Определяется и анализируется ряд политик для изменения протоколов согласованности во время выполнения. Наши эксперименты показывают, что политики динамического выбора уровня согласованности оказываются эффективнее политик статического назначения гарантий согласованности.
Вводится понятие вероятностых гарантий согласованности (т.е. процентили) с использованием темпоральных статистик числовых и нечисловых данных. Такие статистические гарантии очень важны с точки зрения соглашений об уровне обслуживания (service level agreement), хотя, насколько мы знаем, в нашей работе вероятностные гарантии согласованности подробно исследуются впервые.
Представляется законченная реализация концепции рационализации согласованности на основе S3 компании Amazon. Мы приводим данные о показателях (денежной) стоимости и производительности пропуска тестового набора TPC-W для нескольких категорий согласованности, смеси категорий и различных политик категории B. Результаты этих экспериментов обепечивают правильное представление о стоимостных характеристиках таких систем, о стоимостной структуре каждой операции и о том, как можно оптимизировать эти стоимостные показатели с использованием соответствующих моделей стоимости.
Основная часть статьи организована следующим образом. В разд. 2 описываются сценарии использования рационализации согласованности в "облачных" средах. В разд. 3 обсуждаются родственные работы. В разд. 4 рассматриваются рационализация согласованности, приводится анализ категорий A, B и C и обсуждается, как можно обеспечить смешанные гарантии согласованности. В разд. 5 представляются альтернативные стратегии для управления данными категории B. В разд. 6 описывается реализация рационализации согласованности в "облачной" среде. В разд. 7 приводится сводка результатов экспериментов с использованием тестового набора TPC-W. Разд. 8 содержит заключение.
к службе связаны соответствующие расходы.
В среде "облачных" служб хранения данных с каждым обращением к службе связаны соответствующие расходы. В частности, можно очень точно оценить в денежном выражении расходы на поддержку протоколов согласованности данных (нужно всего лишь умножить число обращений к службе, требуемых для обеспечения требуемого уровня согласованности, на стоимость одного такого обращения). Поэтому в этой среде согласованность влияет не только на производительность и доступность систем, но и на общую операционную стоимость. В этой статье мы предложили новую концепцию рационализации согласованности, направленную на оптимизацию расходов времени выполнения системы баз данных в ситуациях, когда несогласованность данных вызывает штрафные расходы. Эта оптимизация основана на том, что в базе данных допускается несогласованность данных, если это способствует снижению стоимости транзакций, но не приводит к слишком большому повышению штрафных расходов.
В предложенном подходе данные разделяются (рационируются) на три категории сгласованности: A, B и C. Для данных категории A обеспечивается строгая согласованность, и транзакции над такими данными обладают наибольшей стоимостью. Для данных категории C гарантируется сессионная согласованность; транзакции дешевы, но вероятно возникновение несогласованных данных. Данные категории B обрабатываются на уровнях строгой или сессионной согласованности в зависимости от задаваемой политики. В этой статье мы представляем и сравниваем несколько таких политик переключения уровней согласованности, включая политики, обеспечивающие вероятностные гарантии согласованности. Как показывают наши эксперименты, рационализация согласованности позволяет существенно снизить общие расходы и повысить эффективность "облачных" систем баз данных. Кроме того, эти эксперименты показывают, что изменение уровней согласованности на основе темпоральной статистики обеспечивает наилучшие стоимостные показатели, поддерживая при этом приемлемую производительность.
Мы полагаем, что предложенные в статье статистические политики являются только первым шагом на пути к вероятностным гарантиям согласованности. В будущих работах будут исследованы многие возможные усовершенствования: улучшенные и убыстренные статистические методы, автоматическая оптимизация с учетом других параметров (например, энергопотребления), добавление бюджетных ограничений к функции стоимости и ослабление других принципов парадигмы ACID (например, долговечности хранения – durability).