Что это такое
Аннотатор позволяет автоматически составлять сжатые конспекты к русским и английским документам, выделяя фразы, наиболее отражающие смысл текста и ключевые слова в тексте любого объема и содержания. Результатом работы сервера является связная, легко читаемая аннотация заданного размера, в которой представлены основные тезисы и смысловое содержание текста. Система аннотирует тексты на русском и английском языке. Документы для аннотирования могут быть переданы в кодировках Windows-1251, DOS Cyrillic 866, KOI8-R, Mac Cyrillic и ISO 8859-5.
Немецко-русский, русско-немецкий словарь
Электронная версия двух современных словарей общей лексики суммарным объемом более 220 тыс. словарных статей (750 тыс. немецких и 850 тыс. русских слов). Включает Немецко-русский (основной) словарь Лейн К., Мальцевой Д.Г., Зуева А.Н. и др. (около 95 тыс. словарных статей), и Русско-немецкий словарь М.Я.Цвиллинга (около 150 тыс. слов и словосочетаний).
МультиЛекс 2.0 Немецкий
Немецко-русский, русско-немецкий словарь
Электронный словарь общей лексики МультиЛекс 2.0 Немецкий содержит немецко-русский и русско-немецкий словари общей лексики Э.Л.Рымашевской (44 тыс. словарных входов, 120 тыс. немецких и 130 тыс. русских слов).
МультиЛекс 2.0 Французский
Французско-русский, русско-французский словарь
МультиЛекс 2.0 Французский содержит «Новый французско-русский и русско-французский словарь» О. В. Раевской (М., «Русский язык», 1996), включающий 40 тыс. слов и словосочетаний во французско-русской и 60 тыс. — в русско-французской части. Особенность этого издания — наличие во всех словарных статьях французской фонетической транскрипции.
МультиЛекс 2.0 Итальянский
Итальянско-русский, русско-итальянский словарь
МультиЛекс 2.0 Итальянский содержит «Новый итальянско-русский словарь» Г.Ф.Зорько, Б.Н.Майзель, Н.А.Скворцова (М., «Русский язык», 1995). В нем более 300 тыс. слов и выражений.
МультиЛекс 2.0 Испанский
Испанско-русский, русско-испанский словарь
Единственный на рынке испанско-русский электронный словарь общей лексики включает «Испанско-русский словарь современного словоупотребления» А.В.Садикова и Б.П.Нарумова (М., «Русский язык», 1996), содержащий более 100 тыс. наиболее часто встречающихся слов и словосочетаний современного испанского языка.
МультиЛекс 2.0 Экономический
Большой экономический толковый словарь
Словарь создан при участии Института новой экономики и содержит электронную версию второго издания Большого экономического словаря под редакцией А.Н.Азрилияна (Институт новой экономики, 1997 год). Экономический словарь содержит 19 тыс. терминов и толкований, многие статьи дополнены различными пояснениями, комментариями.
Другие программные продукты компании
Следопыт 2.0. Программа для смыслового поиска документов с предварительной индексацией.
Персональная поисковая система осуществляет поиск текстов на русском, английском и немецком языках по запросу на естественном языке, с ранжированием результатов поиска по смысловой близости, с предварительной индексацией документов. Скорость индексации: 100–200 Мб в час. Скорость поиска – около 200 Мб в сек., интеграция с Microsoft Word 6.0, 7.0, 97. Обрабатываются тексты в форматах Word, ASCII, HTML
МЛ Аннотатор 1.0. Программа для автоматического аннотирования документов.
Автоматическое аннотирование текстов на русском и английском языках с заданным коэффициентом смыслового сжатия. 100 Кб в минуту, интеграция с Microsoft Word 6.0, 7.0, Microsoft Office 97.
Письмовник 1.0. Программа для составления и перевода деловых документов.
Позволяет быстро составить контракт, рекламное, деловое, научное, личное или официальное письмо, телеграмму или факс на английском языке, обладая минимальными знаниями этого языка. Вы составляете документ на русском языке, а в результате получаете его точный эквивалент на английском языке (или составляете английский документ, а получаете русский). В состав Письмовника входит англо-русский/русско-английский словарь общей и коммерческой лексики на 40 тыс. слов и выражений.
Более подробно прочитать о проектах, технологиях и программных продуктах компании и получить демо-версии Вы можете на сервере http://www.medialingua.ru
[1]
За что, по всей видимости, и получил название полнотекстового каталога.
[2]
Разумеется, это касается только тех таблиц, для которых были созданы полнотекстовые каталоги.
Функции CONTAINSTABLE и FREETEXTTABLE
При написании запросов к SQL-базе часто бывает удобно работать с полнотекстовыми запросами не как с предикатами в секции WHERE, а как с таблицами, и использовать характерные для таблиц операции, такие как связывание, упорядочивание или группирование. Для решения этой задачи в язык Microsoft Transact-SQL введены две функции CONTAINSTABLE и FREETEXTTABLE.
Результатом выполнения функций CONTAINSTABLE и FREETEXTTABLE являются таблицы. В зависимости от результатов поиска, эти таблицы могут содержать одну или несколько строк. А если подходящей информации найдено не было, то результирующие таблицы оказываются пустыми. Записи в этих таблицах состоят из двух полей. Первое поле называется KEY
и является уникальным ключом в таблице, по которой производится поиск. Второе поле является числовым, называется RANK
и имеет смысл степени соответствия найденной записи поисковому запросу. Такую степень соответствия часто называют рейтингом
или рангом найденной записи. В Microsoft SQL Server рейтинг варьируется от 0 (минимальная степень) до 1000 (максимальная степень соответствия запросу).
Теперь о параметрах этих функций. И CONTAINSTABLE, и FREETEXTTABLE имеют по три параметра. Первый параметр — это имя таблицы, по которой производится поиск. Второй параметр — это список полей, по которым ведется поиск, а третий — текст запроса. Синтаксис второго и третьего параметра в точности соответствует синтаксису соответствующих параметров предикатов CONTAINS или FREETEXT, которые подробно были рассмотрены выше.
Функции CONTAINSTABLE и FREETEXTTABLE редко используют самостоятельно. Чаще всего эти функции входят в состав запросов поиска по соответствующим таблицам. Приведем примеры использования этих функций.
Выше мы рассматривали взвешенный запрос поиска информации о курсе доллара и немецкой марки. Вот как выглядит оператор поиска этой информации с использованием функции CONTAINSTABLE:
SELECT Q.RANK, A.Header
FROM Articles AS A,
CONTAINSTABLE(Articles, Header ,'ISABOUT( "курс*",
"доллар*" WEIGHT(0.7),
FORMSOF(INFLECTIONAL, "немецкая марка") WEIGHT(0.3) )') AS Q
WHERE A.ID = Q.[KEY]
ORDER BY Q.RANK DESC
Этот запрос возвращает заголовки статей, соответствующие запросу, и их рейтинги в порядке убывания соответствия запросу. Вот пример результат действия данного запроса на реальной базе экономических новостей:
|
RANK |
Header |
|
258 |
На валютных торгах на ММВБ объявлен технических перерыв при промежуточном курсе 8,253 рублей за 1 доллар США. |
|
258 |
Е. Гайдар считает реальным курс15 рублей за доллар. |
|
242 |
Снижение курса акций на Нью-йоркской фондовой бирже привело к значительному падению курса доллара относительно иены. |
|
242 |
Значительные колебания курса американского доллара в последние дни и наблюдавшаяся тенденция к снижению его курса не связаны с изменением ситуации в Японии. |
|
238 |
Падение курса рубля привело к снижению курса немецкой марки. |
|
187 |
Курс немецкой марки к доллару США на американских рынках падает из-за финансового кризиса в России, считает руководитель экономического отдела компании "Bear Sterns International". |
|
187 |
Утром 2 ноября на торгах в Европе вырос курс йены по отношению к доллару и немецкой марке. |
|
184 |
Центробанк России установил предел отклонения курса покупки от курса продажи наличной иностранной валюты в размере 15%. |
|
173 |
ММВБ отказалась от установления единого расчетного курса гривны к доллару США. |
SELECT Q.RANK, A.Header
FROM Articles AS A,
FREETEXTTABLE(Articles, Header,
'Каково состояние рынка ценных бумаг?')
AS Q
WHERE A.ID = Q.[KEY]
ORDER BY Q.RANK DESC
был получен следующий ответ:
|
RANK |
Header |
|
152 |
Комиссия по рынку ценных бумаг Латвии приостановила действие лицензии, выданной Rietumu banka на посреднические операции на рынке ценных бумаг. |
|
138 |
Правительство не в состоянии обеспечить доходность государственных ценных бумаг на фондовом рынке. |
|
123 |
Американский фондовый рынок не утратил интерес к российским ценным бумагам. |
|
118 |
Закон о налогообложении операций с ценными бумагами должен разрабатываться совместно с участниками фондового рынка. |
|
114 |
Перемены в правительстве России положительно отразились на результатах торгов российскими ценными бумагами на фондовом рынке США. |
|
114 |
Вторничные торги на ММВБ не оказали существенного влияния на результаты торгов российскими ценными бумагами на фондовом рынке США. |
|
114 |
Объемы сделок по российским ценным бумагам на фондовом рынке США продолжают расти. |
|
114 |
Объемы сделок по российским ценным бумагам на фондовом рынке США уменьшились, но остаются довольно высокими. |
|
114 |
На внебиржевом рынке США цены на российские ценные бумаги упали. |
II. Установка поисковой системы
В этом разделе рассмотрена установка программного продукта Следопыт для MS SQL Server 2000. Здесь также рассматриваются настройки Microsoft SQL Server 2000 и Microsoft SQL Server 7.0, необходимые для успешного использования Следопыта. Если Вы планируете работать с несколькими SQL-серверами на одной машине (а Microsoft SQL Server 2000 предоставляет такую возможность), сначала установите все экземпляры Microsoft SQL Server, и, только потом устанавливайте Следопыт.
III. Использование средств полнотекстового поиска в Microsoft SQL Server
Работа с системой полнотекстового поиска Microsoft SQL Server не требует каких-либо средств управления помимо входящих в комплект поставки SQL Server. В этом разделе будут рассмотрены типичные задачи, связанные с организацией полнотекстового поиска в Microsoft MS SQL, и возможные их решения. Более подробную информацию об управлении полнотекстовым поиском Вы можете получить из документации по Microsoft SQL Server 2000 (Microsoft SQL Server 7.0). Эта документация входит в электронном виде в комплект поставки SQL Server и носит название SQL Server Books Online. В дальнейшем мы будем рассматривать наиболее общие приемы работы с полнотекстовым поиском, и давать ссылки на различные разделы Books Online для более детального изучения.
Организацию полнотекстового поиска мы будем рассматривать на примере простой базы текстовых статей. База называется Demo и состоит из единственной таблицы Articles. Таблица Articles состоит из четырех полей:
| Поле | Тип | Содержимое | |||
| ID | int | Уникальный числовой идентификатор статьи | |||
| CreationTime | datetime | Дата и время создания статьи | |||
| Header | varchar(255) | Заголовок статьи | |||
| Body | text | Текст статьи |
При этом поле ID
является первичным ключом в таблице. Первичный ключ называется PK_Articles. Ставится следующая задача: необходимо организовать полнотекстовый поиск по текстовым полям Header и Body таблицы Articles.
При разборе этого примера мы будем пользоваться программами Enterprise Manager и Query Analyzer из стандартного комплекта Microsoft SQL Server. Предполагается, что пользователь знаком с этими программами, а также языком SQL. Также мы предполагаем, что используется нелокализованная «английская» версия Microsoft SQL Server.
Индексирование документов в столбце с типом “image” (Microsoft SQL Server )
Допустим, что статьи в таблице из нашего примера имеют прилагающийся файл, например, в формате Microsoft Word, Microsoft PowerPoint или Microsoft Excel. Для того чтобы можно было бы искать по содержимому документов, добавим в таблицу Articles два столбца:
| Поле | Тип | Содержимое | |||
| AttachedDoc | image | Документ в одном из форматов MS Word, MS Excel, MS PowerPoint, HTML, Plain Text | |||
| Extension | char(4) | Расширение типа документа c точкой (например, “.doc”) |
В мастере полнотекстового индексирования нужно обязательно связать добавленные поля, выбрав в окне мастера имя “Extension” в столбце типа документа в окне мастера. Это нужно для того, чтобы Microsoft SQL Server смог определить тип индексируемых файлов и применить соответствующий конвертер:

Далее, процедура индексирования продолжается, как и при индексировании текстовых данных. В каждой строке таблицы Articles, поле с именем “Extension” должно содержать расширение документа, помещенного в поле с именем “AttachedDoc”.
Индексирование текстовых данных (Microsoft SQL Server )
Запуск мастера полнотекстового индексирования (Microsoft SQL Server 2000)
После того, как Вы выбрали нужную таблицу, с помощью пункта меню Tools | Full-text Indexing… необходимо запустить мастер полнотекстового индексирования. Этот мастер автоматизирует процедуру индексирования данных.
Мастер полнотекстового индексирования задает ряд вопросов, необходимых для создания полнотекстового каталога. Прежде всего, запрашиваются имя уникального индекса обрабатываемой таблицы и имена текстовых полей, которые необходимо заиндексировать. Для нашей базы в качестве индекса необходимо указать индекс PK_Articles, а к качестве текстовых полей — поля Header
и Body:


IV. Заключение
Сотрудники компании МедиаЛингва надеются, что Следопыт для MS SQL Server 2000 окажется полезным для Вас и Вашего бизнеса. Поработав со Следопытом, Вы обнаружите, что использовать его просто, и он оказывает существенную помощь в Вашей работе. Мы надеемся, что Вы захотите познакомиться и с другими программными продуктами нашей компании.
Мы будем благодарны Вам, если Вы выскажете свои соображения о том, как можно улучшить или упростить Следопыт для MS SQL Server 2000.
Как это работает
Поисковая система Серверный Следопыт является так называемой индексирующей системой. Это означает, что прежде чем производить поиск документов, система производит накопление информации о положении всех слов на всех страницах Web-узла. Эта информация сохраняется внутри специализированной компактной базы данных, обеспечивающей в дальнейшем быстрое обнаружение требуемых документов.
Поисковая система выполнена по клиент-серверной технологии. Это означает, что функции индексирования, поиска и отображения информации распределены между различными компонентами системы. Такой подход позволяет при необходимости эффективно распределить нагрузку между различными компьютерами и, тем самым, повысить производительность системы в целом.
Для обмена между компонентами Серверного Следопыта используется стандартный протокол Internet TCP/IP, а для взаимодействия между поисковыми клиентами и Web-сервером протокол CGI/1.1. Это позволяет Следопыту работать с большинством количеством Web-серверов, работающих на платформе Windows/Intel.
Таким образом, Серверный Следопыт представляет собой мощную поисковую систему, позволяющую значительно упростить работу с информацией на web-узле.
MegaXS CD Searcher представляет собой комплекс программных модулей, предназначенных для индексного поиска по неизменяемым текстовым базам, таким как текстовые базы на CD-ROM.
Система состоит из двух частей: авторского и пользовательского комплектов. С помощью авторского комплекта издатель готовит мастер-диск, при этом авторский комплект не редистрибутируется конечному пользователю.
Пользовательский комплект содержит только модули, необходимые для осуществления поиска по готовой индексной базе. Этот комплект свободно распространяется с издаваемой текстовой базой и не требует сложной установки.
Какие преимущества предоставляет система MegaXS CD Searcher издателю?
Используя MegaXS CD Searcher в качестве программного пакета для подготовки и обеспечения доступа к текстовым базам, издатель может полностью сосредоточиться на содержательной части своего электронного издания: удобный инструментарий быстро обработает необходимый объем информации и останется только записать мастер-диск. В зависимости от размера планируемых тиражей и числа продуктов выбирается оптимальная для заказчика схема лицензионных отчислений, что позволяет издателю не замораживать оборотные средства.
Для работы комплекса не требуется никаких расширений Windows, за исключением Web-браузера, и все взаимодействие между пользователем и поисковым механизмом будет осуществляться с помощью стандартного интерфейса HTML -форм.
Как и все остальные поисковые продукты компании МедиаЛингва, MegaXS CD Searcher предоставляет пользователю возможность естественно-языкового полнотекстового поиска, сортирует найденные документы по смысловой близости к поисковому запросу так, что нужные документы оказываются к верхней части списка, сопровождает каждый документ краткой связной аннотацией и подсвечивает в тексте документа слова поискового запроса.
Основой системы автоматической классификации является система рубрик, представляющая собой базу данных, содержащую информацию о дереве рубрик и их индивидуальных признаках. Пользуясь этой базой, система автоматической классификации сравнивает каждый поступивший документ с семантическими образами рубрик и помещает его в соответствующие разделы. Пользователь имеет возможность не только просматривать дерево рубрик и содержащиеся в рубриках документы, но и выбирать из имеющегося списка наиболее интересные разделы. Эти данные заносятся в персональный профиль базы данных клиентов, и пользователь начинает получать сообщения о поступлении информации строго отвечающей его требованиям. Таким образом, пользователь избавляется от необходимости просматривать весь поток новостей.
Перечислим основные преимущества использования системы автоматической классификации:
Поставщики новостей будут уверены, что их информации не затеряется в потоке аналогичных сообщений и поступит к потребителю вовремя. Это позволит им увеличить число сообщений, не опасаясь, что информационные агентства проигнорируют их новость.
Для информационных агентств использование системы классификации и доставки новостей снизит затраты на обработку информации, позволит увеличить пропускную способность информационного канала и даст возможности предоставления дополнительных сервисов клиентам: например, создание персональных рубрик (не содержащихся в рубрикаторе) для потребителей эксклюзивной информации.
Клиенты системы получают возможность быстро и точно получать необходимую информацию, формировать персональный профиль в соответствии со своими специфическими требованиями и задачами
В процессе работы аннотатор вычисляет критерии значимости и семантической независимости для предложений входного текста на основе специальных вероятностных моделей и словарей, и по входному тексту составляет аннотацию заданного размера из наиболее значимых предложений. На выходе исходные предложения несколько переформулируются для придания аннотации большей связности.
О компании МедиаЛингва
Компания МедиаЛингва – это молодая, быстро растущая компания, которая объединяет более 35 профессиональных программистов и лингвистов, работающих над созданием интеллектуальных технологий. Основным направлением деятельности компании является разработка поискового и лингвистического программного обеспечения.
Компания МедиаЛингва была основана в 1995 году и в настоящее время занимает лидирующую позицию на российском рынке информационных технологий в области автоматической обработки текстов и обладает рядом уникальных технологий: поиска текста по запросу на естественном языке, классификации и аннотирования документов. За это время компанией были созданы передовые технологии обработки текстовой информации на русском, английском, немецком, французском, итальянском и испанском языках, которые успешно работают как в качестве самостоятельных программных продуктов, так и в составе различных систем управления информацией.
Общие понятия
Организация полнотекстового поиска в Microsoft SQL Server состоит из нескольких этапов.
Прежде всего, для таблиц базы нужно создать полнотекстовый каталог (full-text catalog). Под полнотекстовым каталогом в Microsoft SQL подразумевается специализированный индекс, в котором хранится информация обо всех появлениях слов и словосочетаний в записях базы. Нужно отметить, что этот индекс принципиально отличается от обычных индексов SQL. Во-первых, полнотекстовый каталог может быть построен только по полям текстового типа, т.е. только для полей типа char, varchar, text, (image – только для Microsoft SQL Server 2000, для поиска по документам) и их Unicode-аналогов: nchar, nvarchar и ntext. Во-вторых, в отличие от индексов SQL, полнотекстовый каталог хранится отдельно от файлов базы данных в отдельном каталоге[1]. Далее, в полнотекстовом каталоге может храниться информация о текстовых записях сразу нескольких таблиц базы. Наконец, последнее важное отличие полнотекстовых каталогов от обычных SQL-индексов. При изменении содержимого в базе данных SQL-индексы таблиц перестраиваются автоматически и, таким образом, всегда отражают состояние заиндексированных полей базы. Обновление же полнотекстовых каталогов производится по расписанию, т.е. независимо от изменений в базе. Таким образом, полнотекстовый каталог отражает состояние базы на момент последнего индексирования. В Microsoft SQL Server 2000 существует специальная опция “Change Tracking”, позволяющая синхронизировать полнотекстовый индекс с данными в таблицах при изменении последних. Более подробно – см. документацию по Microsoft SQL Server 2000.
После того, как будет создан полнотекстовый каталог, необходимо провести индексирование записей в базе. В документации Microsoft эта процедуру называют population. На этом этапе полнотекстовая поисковая система извлекает из записей базы данных текстовые поля. Затем выделенные фрагменты текста разбиваются на отдельные слова и вместе с информацией о том, где именно встретилось это слово, сохраняется в полнотекстовом каталоге. Различают полное и инкрементальное индексирование. При полном индексировании в каталоге сохраняется информация обо всех записях всех таблиц, хранящихся в данном полнотекстовом каталоге. Если объем данных велик, то полное индексирование такой базы может потребовать значительного времени. В случае, когда изменяется относительно небольшой объем данных, для экономии времени применяют инкрементальное индексирование. В этом режиме будут обработаны только те записи баз, которые были изменены (обновлены, добавлены или удалены) с момента последней индексации.
После того, как текстовые данные будут заиндексированы, можно осуществлять полнотекстовый поиск по полям базы.
Дополнительная информация о методике использования полнотекстового поиска находится в следующем разделе Books Online: Creating and Maintaining Databases / Full-text Indexes.
Поддержка русского языка в Microsoft SQL Server
С помощью Следопыта пользователи Microsoft SQL Server получают возможность использовать все достоинства полнотекстового поиска для баз данных, хранящих информацию на русском языке. При работе с такой русифицированной поисковой системой пользователь может искать информацию с учетом всех грамматических особенностей русского языка. Поисковая система автоматически правильно учтет различные формы слов, исключит из обработки различные шумовые слова, такие как предлоги или частицы. При этом добавление этих возможностей потребуют лишь минимальных доработок программных продуктов благодаря полной интеграции Следопыта с Microsoft SQL Server и его средствами управления.
Как показывает опыт, тексты на русском языке часто хранятся вместе с текстами на английском. Не менее часто встречаются и документы, состоящие из смеси русских и английских текстовых фрагментов. Следопыт учитывает эту особенность компьютерных текстов. Для этого в систему Следопыт включен альтернативный английский лингвистический модуль, который подменяет модуль из стандартного комплекта Microsoft SQL Server. Для текстов на английском языке его поведение практически не отличается от поведения стандартного английского модуля. Однако, при обработке текстов, содержащих блоки на русском и английском языке, он производит автоматическое переключение между русскими и английскими лингвистическими модулями. Таким образом, с помощью этого модуля реализуется возможность обработки и баз данных, содержащих русский или английский текст, а также их смесь.
Полнотекстовый поиск в Microsoft SQL Server 2000
Дополнительно к возможностям полнотекстового поиска Microsoft SQL Server 7.0, в Microsoft SQL Server 2000 появилась возможность поиска по документам форматов Microsoft Word (расширение “.doc”), Microsoft Power Point (“.ppt”), Plain Text (“.txt”), HTML (“.htm”), Microsoft Excel (“.xls”), расположенным в таблицах баз данных в полях типа “image”. Также, в Microsoft SQL Server 2000 появилась возможность динамического отслеживания изменений в базе данных и обновления полнотекстового индекса (“Change Tracking”). Все эти возможности полнотекстового поиска Следопыт для MS SQL Server 2000 реализует для русского языка.
Поиск по грамматическим формам слова
Поиск префиксных форм в некоторых случаях позволяет учесть правила изменения слов в языке. Однако построение лингвистически правильных запросов, учитывающих все особенности словообразования в естественном языке, требуют определенного навыка. В особенности это непросто для русского языка, в котором слова подвержены значительным изменениям. Чтобы снять с пользователя подобную нагрузку, в поисковой системе предусмотрен поиск по всем грамматическим формам слова. Такой поиск называется поиском по образованным формам слова (Generation term). По такому запросу поисковая система вызовет лингвистический модуль, который построит все возможные формы слов запроса. Далее будет проведен поиск уже по всем этим формам. Для того чтобы подать запрос по образованным формам нужно в условии поиска указать операцию FORMSOF. С его помощью можно переписать приведенный выше оператор для поиска словосочетаний типа валютная биржа:
SELECT Header FROM Articles WHERE CONTAINS(Header, 'FORMSOF(INFLECTIONAL, ”Валютная биржа”)')
Вот этот оператор даст возможность поиска словосочетания валютная биржа
с полным учетом грамматики русского языка. Первый параметр операции FORMSOF (слово INFLECTIONAL) является обязательным и никогда не меняется. Кстати, FORMSOF позволит отыскать формы слова, которые построить с помощью префиксной формы просто не удастся. Так, для префиксного поиска слова человек и люди являются двумя совершенно разными словами, а для FORMSOF — разными формами одного слова человек.
Поисковая система Microsoft SQL позволяет также производить поиск слов, встречающихся в тексте в непосредственной близости, причем порядок следования слов не важен. Такой вид поиска получил название поиск близких слов (proximity terms). Этот вид поиска существенно отличается от поиска по фразам, в которых порядок следования слов фиксирован. Поиск близких терминов реализуется при помощи оператора NEAR или его синонима символа ‘~’. Пример такого поиска:
SELECT Header FROM Articles WHERE CONTAINS(Header, 'курс NEAR доллара')
Нужно отметить, что поиск близких терминов сочетается с поиском по префиксным формам, но не может использоваться вместе с поиском по образованным формам.
Поиск по тексту документов в полях с типом “image” (Microsoft SQL Server )
Как указано выше, Microsoft SQL Server 2000 поддерживает возможность полнотекстового поиска по документам форматов Microsoft Word (расширение “.doc”), Microsoft Power Point (“.ppt”), Plain Text (“.txt”), HTML (“.htm”), Microsoft Excel (“.xls”), расположенным в таблицах баз данных в полях типа “image”. Запросы для полнотекстового поиска по тексту документов могут содержать предикаты CONTAINS и FREETEXT и строятся также как и при полнотекстовом поиске по текстовым полям. Если Вы планируете использовать возможность поиска по документам, в таблице должно присутствовать текстовое поле, хранящее расширение документа и, на этапе создания полнотекстового индекса, установлена связь между этим полем и полем типа “image”, в котором хранятся документы. Также см. раздел Books Online: Accessing and Changing Relational Data – Full-Text Search - Using Full-text Predicates to Query image Columns.
Поиск префиксных форм слова
До этого момента мы рассматривали запросы, которые производили поиск точных форм слов или фраз. Однако возможности полнотекстовой поисковой системы Microsoft SQL Server позволяют использовать различные виды «приближенного» поиска.
Простейшей формой приближенного поиска является поиск префиксных форм слова (prefix term). В этом режиме производится поиск слов, начинающихся с определенного фрагмента. Для того чтобы использовать этот вид поиска нужно указать начало слова, а затем поставить символ ‘*’, что будет означать «произвольное окончание». Таким образом, при поиске по префиксной форме не учитываются никакие правила изменения слов в языке, а, фактически, производится поиск по шаблону. Так запись ‘рубл*’ будет соответствовать словам рубль, рублем и т.п., а также слову рубленый. Префиксные формы также можно использовать и для поиска фраз. Приведенный ниже запрос иллюстрирует эту возможность.
SELECT Header FROM Articles WHERE CONTAINS(Header, '”Валютн* бирж*”')
Кстати, по этому запросу будут найдены и словосочетания типа валютно-фондовая биржа.
Поиск взвешенных форм
Наконец, последним видом приближенного поиска является поиск взвешенных форм (Weighted Term). При взвешенном поиске мы можем указать степень важности появлений отдельных слов и фраз в тексте. При поиске эти веса скажутся на рейтинге, т.е. степени соответствия, найденных записей. Поясним это на примере. Предположим, что мы интересуемся курсом доллара и немецкой марки. Однако сведения о курсе доллара представляют для нас больший интерес. В таком случае мы можем приписать появлению слова доллар
рядом со словом курс вес больший, чем словосочетанию немецкая марка. В таком случае может образоваться следующий запрос:
SELECT Header FROM Articles WHERE CONTAINS(*, 'ISABOUT( "курс*",
"доллар*" WEIGHT(0.7),
FORMSOF(INFLECTIONAL, "немецкая марка") WEIGHT(0.3) )')
Здесь оператор ISABOUT указывает на поиск по взвешенным формам. Первый параметр задает «основной» термин в запросе, а остальные две записи задают возможные варианты словосочетания, причем модификации курс доллара приписан вес 0.7, а сочетанию курс немецкой марки — 0.3. Обратите внимание, что слово доллар задано в префиксной форме, а словосочетание немецкая марка — в виде образованных форм. К сожалению, информацию о весах найденных записей с помощью предиката CONTAINS получить нельзя. Однако эта информация доступна при использовании функции CONTAINSTABLE. По этой причине операция ISABOUT чаще всего применяется именно в сочетании с CONTAINSTABLE.
Полнотекстовые запросы к базе
После того, как будет произведено индексирование базы, можно переходить к полнотекстовому поиску данных. Для организации полнотекстовых запросов компания Microsoft ввела в язык SQL несколько дополнительных ключевых слов, которые могут быть использованы в произвольном запросе[2]. Это следующие ключевые слова:
CONTAINS
FREETEXT
CONTAINSTABLE
FREETEXTTABLE
Рассмотрим эти операции подробнее.
Полнотекстовый поиск по-русски в базах данных
Мы благодарны Вам за интерес к поисковой системе Следопыт для MS SQL Server 2000.
Продукт «Следопыт для MS SQL Server 2000» работает как с Microsoft SQL Server 7.0, так и с Microsoft SQL Server 2000. В тексте данного руководства, там, где версия продукта не важна, под Microsoft SQL Server будут подразумеваться Microsoft SQL Server 7.0 или Microsoft SQL Server 2000, там, где версия продукта Microsoft SQL Server будет важна, ее номер будет указываться.
Следопыт для MS SQL Server 2000 является развитием линии поисковых программных продуктов, разработанных компанией МедиаЛингва. Следопыт поможет Вам организовать полнотекстовый поиск в Ваших базах данных. Следопыт расширяет возможности встроенной в Microsoft SQL полнотекстовой поисковой машины и дает возможность производить поиск по SQL-базам, содержащим текстовую информацию и документы на русском языке. Следопыт для MS SQL Server 2000 обеспечит Вам принципиально новые возможности по управлению и анализу Ваших текстовых данных.
в комплект поставки Microsoft SQL
Начиная с версии 7.0, компания Microsoft включила в комплект поставки Microsoft SQL Server специальную компоненту: систему полнотекстового поиска по базе данных. Эта система дает возможность пользователю находить нужные записи по разнообразным условиям, таким как поиск слов и словосочетаний, поиск слов в различных грамматических формах, а также средства поиска записей, похожих на заданный фрагмент текста. Причем для работы с этой системой пользователю не требуются дополнительные программные средства: все операторы полнотекстового поиска включены в язык Transact-SQL, используемый в этой СУБД.
Схематически работу полнотекстового поиска в Microsoft SQL можно изобразить с помощью следующей диаграммы:

Работу системы полнотекстового поиска можно разделить на два этапа.
Первый этап — индексирование текстовых данных. На этом этапе поисковая система производить выборку текстовых данных из указанных баз SQL-сервера. Далее данные передаются на обработку лингвистическим модулям, которые выделяют из текста отдельные слова и словосочетания. Далее все эти слова и фразы, вместе с информацией о записях, их содержащих, сохраняются в полнотекстовом индексе.
Вторым этапом работы такой полнотекстовой системы является собственно поиск. На этом этапе пользователь с помощью SQL-команды указывает, какие тексты ему хотелось бы найти. Этот запрос SQL-сервер передает в модуль полнотекстового поиска. Поисковый модуль производит обработку запроса с помощью лингвистических модулей. Далее, с помощью информации, сохраненной в полнотекстовом индексе, производится поиск и формируется список найденных записей. Этот список возвращается в SQL, который формирует уже окончательную таблицу результата поиска. Таблица эта предъявляется пользователю базы данных.
Разумеется, для того, чтобы поиск был произведен корректно, в поисковой системе должны иметься лингвистические модули для всех языков, с которыми работают пользователи базы. В стандартную поставку Microsoft SQL Server входит комплект лингвистических модулей для основных западноевропейских и дальневосточных языков. Следопыт для Microsoft SQL Server пополняет этот список русским языком.
Предикат CONTAINS
Предикат CONTAINS служит для поиска в базе слов или отдельных фраз. С точки зрения языка SQL ключевое слово CONTAINS рассматривается как логическая функция, используемая в разделе WHERE запросов. CONTAINS имеет два параметра: первый указывает на поле таблицы, в котором производится поиск слова или фразы, второй — задает условие поиска. Вот пример простейшего поискового запроса с использованием CONTAINS:
SELECT Header FROM Articles WHERE CONTAINS(Header, 'биржа')
По этому запросу будут выдаваться все тексты заголовков статей, содержащие слово биржа. Нужно отметить, что слово биржа
будет найдено точно в этой же форме, т.е. другие формы этого слова, такие как бирже или биржей, найдены не будут. Несложно видеть, что в данном случае предикат CONTAINS ведет себя аналогично предикату LIKE. Данный запрос можно было бы переписать и так:
SELECT Header FROM Articles WHERE Header LIKE '%биржа%'
однако функция CONTAINS обеспечивает большую гибкость поиска по сравнению с LIKE.
Первое отличие заключается в том, что вне зависимости от настроек SQL-сервера, функция CONTAINS при поиске не делает различий между заглавными и строчными буквами (case insensitive search). Другое отличие рассмотрим на примере поиска словосочетания фондовый рынок:
SELECT Header FROM Articles WHERE CONTAINS(Header, '”Фондовый рынок”')
Данный запрос выдаст статьи, содержащие указанную фразу, причем при поиске будет совершенно не важно каким количеством пробелов разделены эти два слова. Более того, при поиске не будут учтены запятые, дефисы, точки и другие разделительные знаки. Нужно отметить, что такой запрос с помощью LIKE построить уже затруднительно. Однако это далеко не все возможности CONTAINS.
CONTAINS позволяет проводить поиск слов и фраз сразу по всем текстовым полям таблицы. Для этого необходимо указать в качестве первого параметра символ ‘*’. Так, для того чтобы найти словосочетание фондовый рынок во всей таблице Articles нужно выполнить SQL-оператор:
SELECT Header, Body FROM Articles WHERE CONTAINS(*, '”Фондовый
рынок”')
Далее, функция CONTAINS позволяет объединять разыскиваемые слова и фразы логическими операторами AND, AND NOT и OR. Так, запрос
SELECT Header FROM Articles WHERE CONTAINS(Header, 'Доллар AND курс')
вернет заголовки статей, в которых встречается одновременно и слово доллар, и слово курс.
Предикат FREETEXT
Возможности поиска, предоставляемые CONTAINS, очень велики. Удачно сформулированные запросы позволяют пользователь находить информацию, точно соответствующую его пожеланиям. Однако зачастую пользователь не имеет времени или желания разбираться в тонкостях правильного построения логических запросов. Все, чего хочется пользователю— это быстро получить информацию об интересующем его предмете. Для обслуживания таких потребностей пользователей служит предикат FREETEXT.
Синтаксис предиката FREETEXT напоминает синтаксис CONTAINS: FREETEXT также употребляется в секции WHERE SQL-запроса. Так же, как и CONTAINS, предикат FREETEXT выполняет функции индикатора соответствия отдельных записей таблицы запросу. Подобно CONTAINS, оператор FREETEXT имеет два параметра, причем первый, как и в CONTAINS, определяет поле, по которому производится поиск. В качестве этого параметра также можно использовать символ ‘*’. Однако второй параметр имеет другой смысл: в операторе FREETEXT в качестве второго параметра передается текст запроса на естественном языке. Здесь пользователь не стеснен каким бы то ни было формальным синтаксисом: в качестве запроса годится любая фраза или целое предложение, которое представляется похожим на интересующую пользователя информацию. Примером такого полнотекстового поиска может служить следующий запрос:
SELECT * FROM Articles WHERE FREETEXT(*, 'Каково состояние рынка ценных бумаг?' )
При обработке такого запроса сервис полнотекстового поиска самостоятельно выделит из запроса все слова и словосочетания, построит запрос по этим терминам и проведет поиск. В результате этого поиска совершенно не обязательно будут найдены ровно эти же фразы: слова могут находиться в других формах, какие-то части исходного запроса могут отсутствовать.
Кроме того, при обработке такого запроса, поисковая система присвоит каждой найденной записи числовую степень соответствия запросу — ее рейтинг. Как и в случае с предикатом CONTAINS, в запросах, содержащих FREETEXT, эти рейтинги не доступны. Для того чтобы получить их, необходимо воспользоваться другой формой полнотекстового запроса — функцией FREETEXTTABLE. Эта функция, наряду с функцией CONTAINSTABLE, обсуждается в следующем разделе.
Предварительные действия и настройки (Microsoft SQL Server )
Прежде чем устанавливать Следопыт для MS SQL Server 2000, необходимо убедиться в правильности настроек Microsoft SQL Server 2000. Некоторые настройки Microsoft SQL Server можно сделать только при его установке, при дальнейшей работе все эти настройки остаются неизменными. Рекомендуем Вам установить Microsoft SQL Server 2000 в соответствии с перечисленными ниже рекомендациями.
1. На Вашем компьютере установлена система полнотекстового поиска для Microsoft SQL Server. В инсталляторе в списке устанавливаемых модулей ей соответствует компонента Full-Text Search. Эта компонента входит в комплект поставки Microsoft SQL Server 2000, и устанавливается при инсталляции “Typical”. Отметим, что система полнотекстового поиска может быть в любой момент добавлена в уже существующую установку Microsoft SQL Server 2000.
2. Для того чтобы система полнотекстового поиска правильно обрабатывала русский текст, желательно проверить корректность языковых настроек Microsoft SQL Server 2000. Убедитесь, что Microsoft SQL Server 2000 был установлен со способом сравнения текстовых строк (Collation Designator) “Cyrillic_General” и порядком сортировки “Accent Sensitive”. Из программы “Enterprise Manager”, в свойствах установленного сервера, на вкладке “General” значение свойства “Server Collation” должно быть “Cyrillic_General_CL_AS”.
Если у Вас данное свойство имеет какое-либо другое значение, то система поиска не сможет во всех случаях корректно обработать русскоязычные данные. Возможным решением, в таком случае, является хранение текстовых данных в формате Unicode, т.е. в полях типа nchar, nvarchar или ntext. Тем не менее, если Вы планируете работать с русскоязычными текстами, желательно все же сделать вышеуказанные установки (их можно сделать, выбрав тип инсталляции “Custom” в программе установки Microsoft SQL Server 2000). Это позволит избежать лишних проблем с обработкой и отображением текстов на русском языке.
Прежде чем устанавливать Следопыт для MS SQL Server 2000 для работы с Microsoft SQL Server 7.0, необходимо убедиться в правильности настроек Microsoft SQL Server 7.0. Некоторые настройки Microsoft SQL Server можно сделать только при его установке, при дальнейшей работе все эти настройки остаются неизменными. Рекомендуем Вам установить Microsoft SQL Server 7.0 в соответствии с перечисленными ниже рекомендациями.
3. Прежде всего, убедитесь, что Вы устанавливаете Следопыт на компьютер с уже установленным Microsoft SQL Server 7.0 Standard
или Enterprise Edition.
Наш программный продукт не работает с Microsoft SQL Server 7.0 Desktop Edition. Это связано с тем, что в поставку Desktop Edition не входит система полнотекстового поиска. Установка Следопыта невозможна, также, и на компьютер под управлением Windows 95/98: компонента полнотекстового поиска не может быть установлена на этих операционных системах.
4. Убедитесь, что на Вашем компьютере установлена система полнотекстового поиска для Microsoft SQL. В инсталляторе в списке устанавливаемых модулей ей соответствует компонента Full-Text Search. Эта компонента входит в комплект поставки Microsoft SQL Server 7.0, но по умолчанию не устанавливается. Для установки ее Вы должны запустить программу установки Microsoft SQL Server, и в списке серверных компонент выбрать компоненту Full-Text Search:

Отметим, что система полнотекстового поиска может быть в любой момент добавлена в уже существующую установку Microsoft SQL Server 7.0, как это было описано выше.
5. Для того чтобы система полнотекстового поиска правильно обрабатывала русский текст, необходимо сделать корректные языковые настройки Microsoft SQL Server. Убедитесь что при установке Microsoft SQL Server 7.0 для записи ANSI-текстовых полей (т.е. полей типа char, varchar, text), Вами была выбрана страница 1251-Cyrillic. Настройки кодовой страницы ANSI могут быть сделаны с помощью инсталлятора Microsoft SQL, как показано на следующем рисунке:

Если у вас выбрана какая-либо другая страница, то система поиска не сможет корректно обработать русскоязычные данные, хранящиеся в полях ANSI-типов. Возможным решением, в таком случае, является хранение текстовых данных в формате Unicode, т.е. в полях типа nchar, nvarchar или ntext. Тем не менее, если Вы планируете работать с русскоязычными текстами, желательно все же установить страницу 1251-Cyrillic. Это позволит избежать лишних проблем с обработкой и отображением текстов на русском языке. К сожалению, изменить настройки кодовой страницы SQL Server возможно только путем полной переустановки сервера.
Если Вы уверены в том, что все выше изложенные действия по установке Microsoft SQL Server были Вами уже сделаны, Вы можете приступить к установке программы Следопыт для MS SQL Server 2000.
Проблема поиска текстовой информации в реляционных базах данных
На сегодняшний день большие объемы информации, критически важной для повседневного ведения дел, располагаются в реляционных базах данных. Роль реляционных баз, как средства хранения и управления различными видами данных, трудно переоценить. Объемы баз данных, в первую очередь баз, построенных на основе языка SQL, непрерывно растут.
Несмотря на то, что реляционная технология предназначена для хранения, в первую очередь, структурированных данных, все чаще в базах данных оказывается слабо структурированная информация, такая как массивы текстовой информации или данные мультимедиа. При обработке таких данных возникает масса проблем, связанных, в первую очередь, со сложностью поиска по таким данным.
Производители систем управления базами данных выдвинули ряд технологических решений этой проблемы. Одним из таких решений являются системы полнотекстового поиска по текстовым полям базы данных. С помощью таких систем пользователь СУБД получает возможность сочетать в одном SQL-запросе обычные средства поиска по таблицам SQL-баз с интеллектуальными средствами поиска фрагментов текста в полях базы.
Программные продукты и технологии компании МедиаЛингва
Передовые технологии компании «МедиаЛингва» были воплощены в программном обеспечении, рассчитанном на информационные службы, Интернет/Интранет сервера, корпоративные сети и т.п. Это мощное программное обеспечение, предназначенное для быстрой и успешной работы с большими объемами информации — поиска, классификации, аннотирования документов. Мы предлагаем программное обеспечение, которое поможет обработать любой объем информации: поисковую систему для Internet/Intranet серверов — Серверный Следопыт, система поиска по CD-ROM — MegaXS CD Searcher, аннотатор и классификатор. Эти системы предназначены для тех, кто постоянно сталкивается с большим потоком неструктурированной информации.
Регистрация и поддержка
До или после установки Следопыта полезно зарегистрировать Вашу покупку в компании МедиаЛингва. Регистрация даст Вам возможность:
· Получать по телефону или по электронной почте ответы на любые вопросы, связанные с установкой и использованием программы.
· Получать своевременную информацию о выпуске новых версий Следопыта и других программных продуктов, выпускаемых компанией МедиаЛингва.
· Влиять на нашу техническую политику. Любая информация от Вас, будь то критика или пожелания, в конечном счете, позволит Вам быстрее получить те рабочие инструменты, в которых Вы нуждаетесь.
Зарегистрироваться очень легко:
В дистрибутив входит Анкета, содержащая необходимые вопросы для регистрации и приобретения продукта (файл anketa.html – на русском языке, файл anketa_e.html, - на английском языке).
· По почте
— заполните Анкету, распечатайте ее и отправьте по адресу: Россия, г. Москва, 115446, Коломенский проезд, дом 1А, компания «МедиаЛингва».
· При помощи факса — Отправьте заполненную Анкету по факсу +7 (095) 115-97-75;
· При помощи электронной почты — в конце Анкеты кликните на «отправить по e-mail».
При возникновении технических вопросов или неполадок в работе системы Следопыт для Microsoft SQL Server мы рекомендуем Вам обратиться в службу поддержки компании МедиаЛингва:
· по телефону Службы Поддержки: +7 (095) 115-97-11.
· по электронной почте: support@medialingua.ru.
По этим же адресам и телефонам Вы можете обращаться с пожеланиями и предложениями, которые могли бы, на Ваш взгляд, улучшить или упростить данный программный продукт.
Ручной запуск индексирования Microsoft SQL Server
Текущее состояние каталога можно посмотреть в Enterprise Manager в списке полнотекстовых каталогов базы:

Из этого списка можно дать команду на немедленное переиндексирование каталога. Для этого нужно вызвать из меню команду Action| Start Population, а затем выбрать полный или инкрементальный режим индексирования.
В Books Online процедура создания полнотекстовых каталогов обсуждается в следующем разделе: Creating and Maintaining Databases / Full-text Indexes.
Системные требования
Для установки Следопыта для MS SQL Server 2000 требуется компьютер со следующими минимальными характеристиками:
· Процессор Intel Pentium c частотой не менее 166 MHz;
· не менее 32 MБ оперативной памяти (рекомендуется 64 MБ);
· не менее 20 MБ дискового пространства;
· привод CD-ROM;
· видеоадаптер VGA (рекомендуется SVGA);
· манипулятор «мышь».
· Операционная система Microsoft Windows NT Server v4.0/2000 или Microsoft Windows NT Server v4.0/2000 Enterprise Edition + Service Pack 4;
· Microsoft SQL Server v.7.0 Standard или Enterprise Edition c установленной системой полнотекстового поиска (Full-Text Search) или Microsoft SQL Server 2000 c установленной системой полнотекстового поиска.
Сочетание полнотекстовых и формальных критериев при поиске
Полнотекстовые и формальные критерии поиска информации по SQL-базам могут сочетаться произвольным образом. Так, при помощи следующего запроса Вы можете получить заголовки сообщений о курсе доллара за август-сентябрь 1998 года:
SELECT CreationTime, Header FROM Articles
WHERE CreationTime>=’1998-08-01’ AND CreationTime<’1998-10-01’
AND CONTAINS(*, 'курс* ~ доллар*')
ORDER BY Time
Подводя итоги обсуждения операторов поиска, можно сказать, что эти операторы задают разнообразные режимы полнотекстового поиска, которые могут применяться по отдельности или совместно в зависимости от стоящих перед пользователем задач. Так, операторы CONTAINS и CONTAINSTEXT позволяют пользователю производить поиск в полнотекстовой базе по различным логическим критериям. Эти возможности дополняются возможностью поиска на естественном языке при помощи операторов FREETEXT и FREETEXTTABLE.
В Books Online использование полнотекстовых запросов подробно рассматривается в разделе: Accessing and Changing Data / Advanced Query Concepts / Full-text querying SQL Server Data. Полный синтаксис полнотекстовых операторов SQL можно найти в разделе Building SQL Server Applications / Transact-SQL Reference.
Создание полнотекстового индекса (Microsoft SQL Server )
Далее следует процедура создания полнотекстового индекса. Для создания полнотекстового каталога нужно указать его имя и имя каталога на диске, в котором будут храниться данные полнотекстового индекса.

В нашем примере мы указали имя каталога test.
Если бы в нашей базе существовали другие таблицы, требующие полнотекстового поиска, то при следующих запусках мастера на этом этапе у нас появилась бы альтернатива. Мы могли бы для очередной таблицы либо создать новый полнотекстовый каталог, либо подключиться к одному из уже существующих. Принципиальной разницы между этими вариантами нет. Выбор того или иного варианта влияет лишь на объем данных в каждом из каталогов, а также на расписание индексирования таблиц.
Далее следует процедура создания полнотекстового индекса. Для создания полнотекстового каталога нужно указать его имя и имя каталога на диске, в котором будут храниться данные полнотекстового индекса.

В нашем примере мы указали имя каталога ArticlesFT.
Если бы в нашей базе существовали другие таблицы, требующие полнотекстового поиска, то при следующих запусках мастера на этом этапе у нас появилась бы альтернатива. Мы могли бы для очередной таблицы либо создать новый полнотекстовый каталог, либо подключиться к одному из уже существующих. Принципиальной разницы между этими вариантами нет. Выбор того или иного варианта влияет лишь на объем данных в каждом из каталогов, а также на расписание индексирования таблиц.
Создание полнотекстового каталога
Для организации полнотекстового поиска, прежде всего, нужно создать полнотекстовый каталог. Для этого необходимо открыть Enterprise Manager, выбрать нужный SQL-сервер и открыть нужную базу данных. В нашем случае это будет база Demo. Далее в базе необходимо открыть список таблиц базы и выбрать нужную таблицу, т.е. таблицу Articles в нашем примере:

Перед созданием каталога и индексированием проверьте, что таблица, по которой Вы собираетесь организовывать полнотекстовый поиск, имеет хотя бы один уникальный индекс (unique index). Это практически единственное ограничение на таблицы, обрабатываемые системой полнотекстового поиска. Обычно в качестве такого уникального индекса используют первичный ключ (primary key) таблицы. В нашем примере таблица Articles имеет первичный ключ — поле ID, и этот ключ называется PK_Articles.
Технические характеристики
Следопыт для MS SQL Server 2000 позволяет:
· Производить индексирование текстовых полей типов char, varchar
и text, записанных в кодировке Windows-1251, содержащих русский, английский текст или их смесь;
· Производить индексирование документов типов MS Word (.doc), MS Excel (.xls)., MS PowerPoint (.ppt), HTML (.htm), Plain Text (.txt), находящихся в полях таблиц с типом данных image (только Microsoft SQL Server 2000)
· Производить индексирование текстовых полей, хранящихся в формате Unicode (nchar, nvarchar и ntext), содержащих русский, английский текст или их смесь;
· Выделять из текста записей базы и поисковых запросов шумовые слова и исключать их из дальнейшей обработки;
· производить полнотекстовый поиск по базам Microsoft SQL Server с учетом грамматики русского и английского языка.
Следопыт для MS SQL Server 2000 полностью интегрирован со средствами управления Microsoft SQL Server 7.0 и Microsoft SQL Server 2000.
Технические подробности
В Серверном Следопыте реализована технология динамического индексирования информации, что позволяет часто обновлять содержимое сервера. Быстрое пополнение индекса по заданному графику не мешает поиску и сразу же делает новые документы доступными для поиска. Следопыт одинаково эффективно производит индексирование и поиск по документам на русском и английском языке, при этом все слова запроса находятся во всех возможных грамматических формах. Система устойчива к высокой нагрузке и позволяет обрабатывать десятки тысяч поисковых запросов в сутки, что проверено клиентами компании на практике.
Механизм обработки запроса на естественном языке не только облегчит пользователю задачу формулировки поискового запроса, но позволит найти документы, соответствующие смыслу, и не содержащие в точности слова поискового запроса. Например, по запросу “морские глубины” будут найдены документы содержащие “глубина моря” и “глубокие моря”. Краткая содержательная аннотация, передающая смысл найденного документа, позволит пользователю оценить содержание найденного текста, не обращаясь к оригиналу. Следопыт подсвечивает в тексте документа слова запроса, что дает пользователю возможность сразу обратить внимание на нужные части документа. Переход между найденными документами и вхождениями слов запроса в тексте можно осуществлять с помощью удобной системы стрелок.
На стадии подготовки мастер диска используется генератор индексной базы и автоматических аннотаций. Настройки поисковой формы и шаблона отчета производится путем редактирования HTML форм. На мастер-диске размещаются: база HTML текстов, индексная база, аннотации и клиентский комплект MegaXS CD Searcher.
Ядром клиентского комплекта MegaXS CD Searcher является поисковый агент. Он вычисляет запросы по индексной базе и извлекает аннотации к найденным документам. Поисковый агент не имеет собственного пользовательского интерфейса и общается с Web- браузером посредством ActiveX модулей.
Когда пользователь нажимает кнопку Поиск, его запрос принимается ActiveX модулем получения запроса и передается для вычисления поисковому агенту. Далее из списка формируется отчет о найденных файлах, который передается для загрузки в браузер.
Важно отметить, что данная реализация не требует от пользовательского компьютера какого-либо сетевого протокола или DCOM и единственным требованием для успешного функционирования системы является наличие Internet Explorer.
Классификатор предназначен для структурирования больших массивов информации без использования ручного труда, путем определения принадлежности входящих документов к заранее созданным рубрикам.
Главными чертами системы являются: полная автоматизация процессов обработки, сортировки, а также возможность поддержки индивидуальных настроек для каждого пользователя системы.
Удаление Следопыта для MS SQL Server
Для удаления программного продукта Следопыт для MS SQL Server 2000 необходимо войти в систему с правами Администратора. Далее, откройте Панель Управления (Control Panel) и откройте стандартный апплет Установка и удаление программ (Add/Remove Programs). В списке установленных на Ваш компьютер программ выберите Следопыт для MS SQL Server 2000
или Sledopyt for MS SQL Server 2000
и нажмите кнопку Добавить/Удалить
(Add/Remove). По этой команде запустится процедура автоматического удаления программного продукта.
После удаления необходимо будет перезагрузить операционную систему и заново пересоздать и переиндексировать все полнотекстовые каталоги.
Установка Следопыта для MS SQL Server
Прежде чем приступать к установке Следопыта для MS SQL Server 2000, ознакомьтесь с текстом Лицензионного Соглашения, входящим в комплект поставки данного программного продукта. Если Вы не согласны с условиями Лицензионного Соглашения, Вы должны отказаться от установки и использования Следопыта для MS SQL Server на своем компьютере.
Для успешной установки необходимы права и привилегии Администратора системы. Без привилегий Администратора системы процедура установки не может быть успешно выполнена.
Для начала установки Следопыт для MS SQL Server 2000 вставьте диск в CD-ROM или загрузите программу из Интернета, затем запустите файл sled2000. После запуска программы установки Вам необходимо будет ответить на несколько вопросов. Прервать установку Вы можете в любой момент. Ниже описаны все этапы установки программного продукта.
Выбор языка. Прежде всего, Вам предложат выбрать язык, на котором программа установки будет задавать последующие вопросы. Вы можете выбрать либо русский, либо английский язык.
Копирование файлов.
После этого производится копирование необходимых файлов на жесткий диск Вашего компьютера.
Перезагрузка Windows NT.
После копирования файлов Вам будет предложено перегрузить компьютер.
После установки не забудьте заполнить и отправить в компанию МедиаЛингва Анкету!
В процессе установки Следопыт изменяет установки Microsoft SQL Server. Для того чтобы установки вступили в силу, необходимо после завершения установки пересоздать и переиндексировать все существующие в SQL Server полнотекстовые каталоги.
Для этого необходимо запустить Enterprise Manager. Затем необходимо выбрать существующую базу данных и открыть список полнотекстовых каталогов (папка Full-text catalogs). После этого нужно удалить все каталоги, созданные в данной базе. Это можно сделать из меню с помощью команды Action|Remove All Catalogs. После этого полнотекстовые каталоги могут быть созданы вновь. Методы создания и управления полнотекстовыми каталогами разбираются в разделе Создание полнотекстового каталога и индексирование текстовых данных данного руководства.
Выбор расписания индексирования (Microsoft SQL Server )
Наконец, последним этапом создания полнотекстового каталога является указание режимов и расписания индексирования данных. Мы будем использовать два режима индексирования: полный и инкрементальный. Полное индексирование, как правило, применяют эпизодически для полного обновления каталога. Для быстрого же обновления базы и обеспечения поиска по свежим данным чаще всего применяют режим инкрементального индексирования.
Несколько слов о расписании индексирования. Microsoft SQL Server имеет достаточно гибкую систему создания расписаний. Вы можете указать произвольное количество заданий: однократных, ежедневных, еженедельных или ежемесячных, — привязать их к определенным дням и времени и т.п. В нашем случае мы ограничимся двумя заданиями:
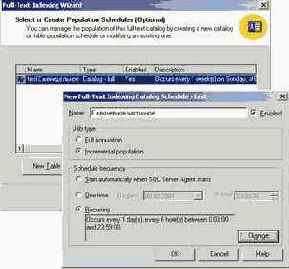
Это значит, что мы будем раз в неделю производить полное переиндексирование базы и ежедневно с интервалом в 6 часов проводить инкрементальное индексирование.
На этом процедура создания полнотекстового каталога завершается: производится создание и настройка файлов полнотекстового индекса и по расписанию производится индексирование данных.
Наконец, последним этапом создания полнотекстового каталога является указание режимов и расписания индексирования данных. Режимов индексирования, как отмечалось выше, существует два: полный и инкрементальный. Полное индексирование, как правило, применяют эпизодически для полного обновления каталога. Для быстрого же обновления базы и обеспечения поиска по свежим данным чаще всего применяют режим инкрементального индексирования.
Несколько слов о расписании индексирования. Microsoft SQL Server имеет достаточно гибкую систему создания расписаний. Вы можете указать произвольное количество заданий: однократных, ежедневных, еженедельных или ежемесячных, — привязать их к определенным дням и времени и т.п. В нашем случае мы ограничимся двумя заданиями:

Это значит, что мы будем раз в неделю производить полное переиндексирование базы и ежедневно с интервалом в 6 часов проводить инкрементальное индексирование.
На этом процедура создания полнотекстового каталога завершается: производится создание и настройка файлов полнотекстового индекса и по расписанию производится индексирование данных.
Зачем это нужно
Быстрое развитие Интернет предъявляет новые требования к организации информации на корпоративном web-сайте. Задача построения наглядной, прозрачной для пользователя структуры сайта постоянно стоит перед web-мастером, усложняясь по мере увеличения объема информации. Наличие интеллектуальной поисковой системы становится необходимым компонентом современного web-сайта.
Какой бы ни была сложной структура сайта, сколько бы документов на нем ни располагалось, web-мастер может быть уверен: если соответствующий интересам пользователя документ содержится на сайте - он будет найден. При этом система сама решит проблемы множественных кодировок кириллицы. В случае наличия нескольких версий сайта на разных языках, поиск будет производиться во всех его частях, в том числе и по смешанному поисковому запросу.
Пользователь получает возможность сформулировать поисковый запрос, не вдаваясь в тонкости логического языка построения запросов. В поисковую систему встроен модуль аннотирования, поэтому пользователь получает результаты поиска с автоматически составленными, гладкими и легко читаемыми аннотациями найденных документов, что позволяет быстро оценить содержание найденных документов.
Так как данная поисковая система предназначена для работы в Internet, то это означает, что она должна быть совместима с существующими Internet-технологиями и стандартами, и должна устойчиво работать в условиях высокой нагрузки, характерной для Web-серверов. Такие требования обусловили ряд технологических решений, примененных в Серверном Следопыте. Остановимся на основных технологических особенностях Следопыта:
Запуск мастера полнотекстового индексирования (Microsoft SQL Server
После того, как Вы выбрали нужную таблицу, с помощью пункта меню Tools| Full-text Indexing… необходимо запустить мастер полнотекстового индексирования. Этот мастер автоматизирует процедуру индексирования данных.
Мастер полнотекстового индексирования задает ряд вопросов, необходимых для создания полнотекстового каталога. Прежде всего, запрашиваются имя уникального индекса обрабатываемой таблицы и имена текстовых полей, которые необходимо заиндексировать. Для нашей базы в качестве индекса необходимо указать индекс PK_Articles, а в качестве текстовых полей — поля Header
и Body:

