Альтернативные архитектуры СУБД
Очевидно, что оптимизация систем баз данных категории OLTP на основе использования основной памяти является хорошей идеей, если соответствующие базы данных помещаются в основную память. Но возможен и ряд других вариантов организации систем баз данных, например:
Системы баз данных без журнализации. Такие системы баз данных либо могут не нуждаться в восстановлении баз данных, либо могут производить восстановление на основе данных, хранимых в других узлах кластера (как это предлагалось в системах Harp [LGG+91], Harbor [LM06] и C-Store [SAB+05]).
Однопотоковые системы баз данных. Хотя режим многопотоковой обработки традиционно являлся важным в системах баз данных OLTP для скрытия времени ожидания, возникающего из-за медленного выполнения записи на диск, он гораздо менее важен для систем, которые размещают базы данных целиком в основной памяти. Однопотоковая реализация в некоторых случаях может оказаться вполне достаточной, особенно, если она обеспечивает хорошую производительность. Конечно, требуется какой-либо способ получения преимуществ от наличия в одном процессоре нескольких ядер, но современные достижения в технологии виртуальных машин обеспечивают возможность придать этим ядрам вид отдельных процессорных узлов без слишком больших накладных расходов [BDR97], что делает однопотоковые реализации вполне пригодными.
Системы баз данных без поддержки транзакций. Во многих системах поддержка транзакций не требуется. В частности, в распределенных Internet-приложениях транзакционной согласованности часто предпочитается конечная согласованность [Bre00, DHJ+07]. В других случаях могут быть приемлемыми легковесные формы транзакций, например, такие, в которых все чтения должны быть произведены до первой записи [AMS+07, SMA+07].
На самом деле, в сообществе баз данных имеется несколько предложений по построению систем баз данных со всеми этими характеристиками или некоторыми из них [WSA97, SMA+07]. Однако открытым остается вопрос, как будут работать эти разные конфигурации, если их действительно построить? Это и есть центральный вопрос данной статьи.
Измерение накладных расходов OLTP
Для поиска ответа на этот вопрос авторы воспользовались современной системой баз данных с открытыми исходными кодами (Shore) и провели ее испытание на подмножестве тестового набора TPC-C. Исходная реализация, выполняемая на современной настольной машине, показывала результат примерно в 640 транзакций в секунду (transactions per second, TPS). Затем эта реализация модифицировалась путем удаления из системы различных возможностей по одной за раз, и всякий раз полученный вариант системы испытывался на том же подмножестве TPC-C. Это делалось до тех пор, пока от системы не осталось крошечное ядро, содержащее код обработки запросов, на котором удалось достичь скорости в 12700 TPS. Это ядро является однопотоковой системой баз данных в основной памяти, не поддерживающей блокировки и восстановление. В ходе этой декомпозиции авторам удалось выделить четыре основных компонента, удаление которых привело к существенному повышению пропускной способности системы:
Журнализация. Сборка журнальных записей и отслеживание всех изменений в структурах базы данных уменьшает производительность. От журнализации можно отказаться, если не требуется восстанавливаемость баз данных, или если восстанавливаемость обеспечивается другими средствами (например, на основе других узлов сети).
Блокировки. Традиционная двухфазная схема блокировок требует существенных накладных расходов, поскольку весь доступ к структурам базы данных управляется отдельной сущностью – менеджером блокировок.
Защелки (latching). В многопотоковых системах баз данных для многих структур данных должны срабатывать кратковременные блокировки (защелки, latch) до того, как к ним станет возможен доступ. Устранение этой потребности и переход к однопотоковому подходу значительно влияет на производительность.
Управление буферами. В системе баз данных с хранением данных в основной памяти не требуется доступ к дисковым страницам через буферный пул, в результате чего устраняется уровень косвенности при доступе к любой записи.
Результаты
На рис. 1 показано, как эти модификации влияют на итоговую производительность Shore (измеряемую числом выполненных команд центрального процессора на транзакцию New Order из TPC-C). Как можно видеть, каждая из этих подсистем занимает от 10 до 35% общего объема работы системы (1.73 миллиона команд, соответствующих общей высоте рисунка).
«Оптимизации, произведенные вручную» здесь представляют набор оптимизаций, которые были внесены в код авторами и направлены, прежде всего, на улучшение эффективности пакета для работы с B-деревьями. Реальные команды, обрабатывающие данный запрос и называемые на рисунке «полезной работой», – это команды минимальной реализации, выполненной авторами поверх вручную закодированного пакета поддержки B-деревьев в основной памяти. Число команд минимальной реализации при выполнении запроса составляет около одной шестидесятой от общего числа выполненных команд исходной системы. Белый прямоугольник под «buffer manager» представляет версию Shore после того, как из системы было удалено все, что было возможно, – в ней все еще выполняются транзакции, но используется около 1/15-ой от числа команд исходной системы, или в четыре раза больше числа команд полезной работы. Дополнительный выигрыш, обеспечиваемый минимальной реализацией, объясняется глубиной стека вызовов в Shore и тем фактом, что авторы не смогли полностью избавиться в Shore от всего наследия транзакций и менеджера буферов.

Рис. 1. Анализ выполнения команд в разных подсистемах СУБД для транзакции New Order из TPC-C. Верхняя часть столбиковой диаграммы соответствует производительности исходной системы Shore при поддержке всей базы данных в основной памяти и отсутствии конкуренции между потоками. Нижняя пунктирная линия – это полезная работа, измеренная путем выполнения той же транзакции на ядре без накладных расходов
Вклад авторов и организация статьи
Основными достижениями этой статьи являются:
анализ того, на что уходит время при работе современной системы баз данных; тщательное измерение производительности различных облегченных вариантов такой системы; использование этих измерений для обсуждения производительности разных систем управления базами данных – например, систем без поддержки транзакций или журналов, – которые можно было бы построить.
Оставшаяся часть статьи организована следующим образом. В разд. 2 обсуждаются средства поддержки OLTP, которые скоро могут стать (или уже становятся) неупотребительными. В разд. 3 приводится обзор СУБД Shore как стартовой точки исследования авторов и описывается производившаяся ими декомпозиция. В разд. 4 описываются эксперименты авторов над Shore. Затем в разд. 5 полученные результаты используются для обсуждения их последствий для будущих СУБД и рассуждений по поводу производительности некоторой гипотетической системы управления базами данных. В разд. 6 рассматриваются дополнительные родственные исследования, и разд. 7 содержит заключение.
Современные системы баз данных общего
Современные системы баз данных общего назначения, ориентированные на OLTP, обладают стандартным набором характерных черт: коллекцией структур данных на диске для хранения таблиц, включающей неупорядоченные файлы и B-деревья; поддержкой параллельного выполнения нескольких запросов и операций обновления базы данных на основе блокировок; восстановлением на основе журнала и наличием эффективного менеджера буферов основной памяти. Эти средства были разработаны для поддержки обработки транзакций в 1970-е и 1980-е гг., когда объем баз данных OLTP во много раз превосходил размеры доступной основной памяти, и компьютеры, поддерживающие эти базы данных, стоили сотни тысяч, если не миллионы долларов.
Сегодня имеется совсем другая ситуация. Во-первых, современные процессоры являются очень быстрыми, так что время вычислений для многих транзакций категории OLTP измеряется микросекундами. За несколько тысяч долларов можно купить систему с гигабайтами основной памяти. Кроме того, организации нередко владеют сетевыми кластерами, включающими много рабочих станций, общий объем памяти которых измеряется сотнями гигабайт, и этого хватает для хранения в основной памяти многих баз данных OLTP.
Во-вторых, развитие Internet и появление разнообразных приложений, для которых требуется обработка больших объемов данных, приводит к повышению интереса к системам, похожим на системы баз данных, но не поддерживающим полный набор возможностей стандартной системы баз данных. Конференции по тематике операционных систем и сетей заполнены докладами с предложениями архитектур систем хранения данных, «похожих на системы баз данных», в которых поддерживаются различные формы целостности, надежности, параллелизма, репликации и поддержки запросов [DG04, CDG+06, GBH+00, SMK+01].
Эта возрастающая потребность в службах, подобных службам баз данных, в сочетании с существенным повышением производительности и снижением стоимости аппаратуры наводит на мысль о ряде интересных альтернативных систем, которые можно построить таким образом, чтобы они обладали не тем набором характерных черт, которые имеются у стандартных серверов баз данных OLTP.
Базы данных, хранимые в основной памяти
Существенный рост размеров доступной основной памяти в течение последних нескольких десятилетий дает все основания надеяться, что многие базы данных OLTP уже помещаются или скоро будут помещаться в основной памяти, в особенности, в совокупной основной памяти крупного кластера. Это связано, главным образом, с тем, что размер большинства баз данных OLTP растет далеко не так быстро, как объем доступной основной памяти, поскольку число заказчиков, продуктов и других объектов реального мира, информация о которых сохраняется в этих базах данных, не возрастает в темпе, диктуемом законом Мура. С учетом этого наблюдения поставщикам СУБД имеет смысл создавать системы, оптимизируемые в расчете на распространенную ситуацию, когда база данных целиком помещается в основной памяти. В таких системах важно принимать во внимание оптимизацию индексных структур [RR99, RR00], а также остерегаться использования форматов кортежей и страниц, оптимизированных в расчете на использование дисковой памяти [GS92].
Кластерные вычисления
Почти все СУБД нынешнего поколения были изначально написаны в 1970-х гг. в расчете на мультипроцессоры с общей памятью. В 1980-е гг. многие компании-поставщики добавили в свои системы поддержку архитектур с общими дисками. В последние два десятилетия появились СУБД с архитектурой без общих ресурсов («shared nothing») в стиле Gamma [DGS+90] и кластеры из персональных компьютеров массового класса, позволяющие решать многие масштабные вычислительные задачи. Любая будущая система баз данных, предназначенная для использования на этих кластерах, должна разрабатываться с нуля.
Однопотоковый режим в системах OLTP
Во всех современных СУБД имеется обширная поддержка многопотокового режима, включая набор протоколов транзакционного управления параллелизмом, а также насыщенность кода командами кратковременных блокировок («защелок», latch), обеспечивающими корректность доступа нескольких потоков управления к совместно используемым структурам, таким как буферные пулы и индексные страницы. Традиционные аргументы в пользу многопотокового режима состоят в том, что он позволяет избежать простоя при обработке нескольких транзакций, когда одна или несколько транзакций ждут поступления данных с диска, а также предотвратить торможение длинными транзакциями выполнения коротких транзакций.
Авторы утверждают, что ни один из этих аргументов более не является весомым. Во-первых, если базы данных постоянно находятся в основной памяти, то никогда не возникает потребность в ожидании обменов с диском. Кроме того, производственные транзакционные системы не предполагают какого-либо ожидания действий пользователей – транзакции почти всегда выполняются на основе хранимых процедур. Во-вторых, рабочие нагрузки в системах OLTP являются очень простыми. Типичная транзакция состоит в выполнении нескольких индексных поисков и обновлений, которые в системе баз данных в основной памяти могут быть выполнены за сотни микросекунд. Более того, при разделении современной индустрии баз данных на рынки обработки транзакций и хранилищ данных долговременные (аналитические) запросы теперь обслуживаются системами хранилищам данных.
Одна из проблем состоит в том, что многопотоковый режим требуется для поддержки машин с несколькими процессорами. Однако авторы полагают, что эту проблему можно решить путем трактовки одного физического узла с несколькими процессорами как нескольких узлов кластера без совместно используемых ресурсов, возможно, управляемого монитором виртуальной машины, которая динамически распределяет ресурсы между этими логическими узлами [BDR97].
Еще одной проблемой является то, что сети становятся новыми дисками, привнося задержки в распределенные транзакции и требуя повторного выполнения транзакций. Безусловно, это верно в общем случае, но для многих транзакционных приложений можно разделить рабочую нагрузку таким образом, чтобы она стала «одноузловой» («single-sited») [Hel07, SMA+07], и каждая транзакция могла полностью выполняться в одном узле кластера.
Следовательно, в некоторых классах приложений баз данных не требуется поддержка многопотокового режима. В таких системах унаследованный код для поддержки блокировок и защелок становится неоправданным накладным расходом.
Как показывают литература, несколько исследовательских
Как показывают литература, несколько исследовательских групп, включая Amazon [DHJ+07], HP [AMS+07], NYU [WSA97] и MIT [SMA+07] демонстрируют интерес к построению систем, существенно отличающихся от традиционных СУБД, которые ориентируются на OLTP. В частности, система H-Store [SMA+07], разработанная в MIT, демонстрирует, что устранение всех упомянутых выше характеристик может привести к повышению пропускной способности транзакций на два десятичных порядка. Это наводит на мысль, что какая-либо из этих систем баз данных, вероятно, обеспечит выдающуюся производительность.
Следовательно, как полагают авторы, поставщикам традиционных СУБД следует обдумать возможность производства продуктов с явным образом отключаемыми некоторыми из этих характеристик. С целью помочь этим разработчикам в понимании влияния на производительность разных вариантов систем, которые они могут захотеть построить, авторы приступают к детальному исследованию производительности Shore и созданных ими вариантов этой системы.
Тенденции в области OLTP
Как отмечалось во введении, истоки большинства популярных реляционных СУБД отслеживаются в системах, разработанных в 1970-х гг. В этих СУБД используются дисковые индексные структуры и неупорядоченные файлы, поддерживаются транзакции на основе журнала и блокировочное управление параллелизмом. Однако со времени принятия таких архитектурных решений прошло уже 30 лет. В настоящее время компьютерный мир совсем другой, нежели тогда, когда разрабатывались эти традиционные системы; назначение этого раздела состоит в том, чтобы проанализировать влияние этих изменений. Аналогичные наблюдения описывались в [SMA+07].
Варианты транзакций
Хотя для многих систем OLTP, несомненно, требуется транзакционная семантика, в последнее время появились предложения (в частности, из области Internet) по поводу систем управления данными с ослабленной согласованностью. Обычно требуется некоторая форма конечной согласованности [Bre00, DHJ+07] при наличии убежденности в том, что доступность более важна, чем транзакционная семантика. Системы баз данных для таких сред, по всей вероятности, мало нуждаются в механизмах, разработанных для поддержки транзакций (например, журналы, блокировки, двухфазная фиксация и т.д.).
Даже если требуется какая-то форма строгой согласованности, имеется много слегка ослабленных моделей. Например, широкое принятие изоляции на основе мгновенных снимков (не являющейся транзакционной) свидетельствует о том, что пользователи готовы поменять транзакционную семантику на производительность (в этом случае за счет устранения блокировок для чтения).
И, наконец, современные исследования показывают, что имеются ограниченные формы транзакций, для поддержки которых требуется гораздо меньше механизмов, чем для поддержки стандартных транзакций над базами данных. Например, если все транзакции являются «двухфазными» – то есть все операции чтения в них выполняются до первой операции записи, и для них гарантируется отсутствие аварийного окончания после завершения фазы чтения, – то не требуется журнализация UNDO [AMS+07, SMA+07].
Высокая доступность в противовес журнализации
Для производственных систем обработки транзакций требуется доступность баз данных 24 часа в сутки семь дней в неделю. По этой причине в большинстве систем используется некоторая форма обеспечения высокой доступности, как правило, основанная на наличии двукратной (или большей) избыточности аппаратуры для гарантированного наличия доступной резервной системы в случае отказа.
Последние публикации [LM06] показывают, что, по крайней мере, для систем хранилищ данных можно использовать эти доступные резервные системы при восстановлении. В частности, вместо использования журнала REDO, восстановление может быть произведено путем копирования недостающего состояния из других реплик базы данных. В своей предыдущей статье авторы утверждали, что это можно сделать и для транзакционных систем [SMA+07]. Если это действительно так, то код унаследованных СУБД, предназначенный для восстановления баз данных, также становится неоправданным накладным расходом.
Удаление компонентов Shore
В табл.1 резюмируются свойства и характеристики современных систем OLTP (левый столбец), позволяющие удалить из СУБД некоторые функциональные возможности. Эти оптимизации использовались авторами в качестве руководства по модификации Shore. Из-за тесной интеграции всех менеджеров Shore было невозможно точно разделить все компоненты, чтобы их можно было удалять в произвольном порядке. Наилучшим возможным подходом было удаление функциональных возможностей в порядке, диктуемом структурой кода, что обеспечивало некоторую гибкость. Это порядок был следующим:
удаление журнализации; удаление блокировок ИЛИ защелок; удаление защелок ИЛИ блокировок; удаление кода, относящегося к менеджеру буферов.
Таблица 1. Возможный набор оптимизаций для OLTP
| Свойства OLTP и новые платформы | Модификация СУБД |
| архитектуры без поддержки журнала | удаление журнализации |
| разделение, коммутативность | удаление блокировок (когда это возможно) |
| поочередное выполнение транзакций | однопотоковый режим выполнения, удаление блокировок, удаление защелок |
| хранение в основной памяти | удаление менеджера буферов |
| нетранзакционные базы данных | устранение учета транзакций |
Кроме того, авторы обнаружили, что в любой точке процесса удаления компонентов возможны следующие оптимизации:
ускорение и жесткое кодирование логики сравнения ключей B-деревьев, как это делается в большинстве коммерческих систем; ускорение поиска в каталогах; увеличение размера страницы для устранения потребности в частом распределении памяти (это предполагается указанным выше Шагом 4); удаление транзакционных сессий (начала транзакции, фиксации, различных проверок).
Далее описывается подход, примененный авторами для реализации упомянутых действий. Вообще говоря, для удаления из системы некоторого компонента либо добавлялись условные операторы, которые позволяют избежать выполнения кода, относящегося к этому компоненту, либо, если добавление условного оператора приводило к ощутимым накладным расходам, методы переписывались целиком для полного устранения вызовов удаляемого компонента.
Удаление журнализации. Удаление журнализации состоит из трех шагов. Первый шаг заключается в устранении генерации запросов ввода-вывода, а также тех точек работы системы, которые ассоциированы с выполнением этих запросов (позже, на рис. 7 эта модификация называется устранением «дисковой журнализации» («disk log»)). Это достигается путем установки режима групповой фиксации транзакций и увеличения размера буфера журнала в такой степени, чтобы он не выталкивался в течение экспериментов. Потом «закомментированию» подвергаются все функции, используемые для подготовки и записи в буфер журнальных записей (на рис. 7 это называется «журнализацией в основной памяти» «main log»). Последний шаг состоит в добавлении условных операторов в разных местах кода для устранения обработки LNS.
Удаление блокировок (а также и защелок). В ходе своих экспериментов авторы обнаружили, что можно безопасно чередовать порядок удаления блокировок и защелок (если уже удалена журнализация). Поскольку защелки используются и внутри кода обработки блокировок, устранение одного механизма снижает уровень накладных расходов другого. Для удаления блокировок авторы, прежде всего, поменяли все методы менеджера блокировок таким образом, чтобы сразу после обращения из них происходил возврат, как если бы запрос блокировки был успешно обработан, и все проверки блокировок были удовлетворены. После этого они модифицировали методы чтения записей, поиска их в каталоге и доступа к ним через B-дерево. В каждом случае удалялся код, относящийся к неудовлетворенным запросам блокировок.
Удаление защелок (а также и блокировок). Удаление защелок было похоже на удаление блокировок. Сначала код реализации мьютексов был изменен таким образом, чтобы все запросы немедленно удовлетворялись. Затем в код были добавлены условные операторы, позволяющие избежать запросов защелок. Потребовалось заменить методы B-дерева на такие, в которых не используются защелки, поскольку добавление условных операторов вызвало бы существенные накладные расходы по причине тесной интеграции кода защелок в методах B-дерева.
Удаление вызовов менеджера буферов. Наиболее пространной модификацией выполненной авторами, являлось удаление методов менеджера буфера, притом что журнализация, блокировки и защелки уже не действовали. Для создания новых записей авторы отказались от механизма выделения страниц Shore и вместо этого воспользовались стандартной библиотекой malloc. Malloc вызывается для каждой новой записи (записи больше не располагаются в страницах), и для будущего доступа используются указатели. Потенциально распределение памяти может производиться более эффективно, в особенности, если заранее известны размеры размещаемых объектов. Однако дальнейшая оптимизация распределения основной памяти является следующим этапом сокращения накладных расходов, и авторы оставили эту работу на будущее. Оказалось, что невозможно полностью удалить страничный интерфейс к буферным фреймам, поскольку его удаление привело бы к несостоятельности большей части оставшегося кода Shore. Вместо этого авторы ускорили отображение между страницами и буферными фреймами, сократив накладные расходы до минимума. Аналогично, чтение и модификация записи по-прежнему проходит через уровень менеджера буферов, хотя и очень тонкий (на рис. 7 этот набор модификаций называется «страничным доступом» («page access»)).
Прочие оптимизации. Выполнены еще четыре вида оптимизации, которые можно производить в любой точке процесса удаления упомянутых выше компонентов. Они состоят в следующем.
Ускорение выполнения кода пакета B-дерева путем ручного кодирования сравнения ключей для того распространенного случая, когда ключи являются несжатыми целыми числами (эта оптимизация называется «ключами B-дерева» («Btree keys») на рис. 5-8).
Ускорения поиска в каталоге за счет использования единого кэша для всех транзакций (эта оптимизация на рис. 7 называется «поиском в каталоге» («dir lookup»)).
Увеличение размера страницы от 8 до 32 килобайт, что является предельно возможным размером в Shore (на рис. 7 эта оптимизация называется «небольшие страницы» («small page»)).
Более крупные страницы, хотя и непригодны для систем баз данных OLTP с хранением баз данных на дисках, могут помочь в системе с хранением баз данных в основной памяти за счет уменьшения числа уровней в B-деревьях (из-за укрупненных узлов), а также позволяют сократить частоту выделения страниц для вновь создаваемых записей. Альтернативным подходом было бы уменьшение размера узла B-дерева до размера блока кэша, как это предлагалось в [RR99], но тогда потребовалось бы отказаться от того, что размер узла B-дерева совпадает с размером страницы Shore, или сделать размер страницы Shore меньшим одного килобайта (что в Shore не допускается).
Устранение накладных расходов на подготовку и завершение сессии для каждой транзакции, а также на соответствующее отслеживание выполняемых транзакций путем объединения всех транзакций в одну сессию (на рис. 7 это называется «Xactions»).
Полный набор изменений/оптимизаций, произведенных авторами над Shore, а также набор эталонных тестов и документация по организации экспериментов доступны на сайте проекта H-Store.
В следующем разделе авторы переходят к обсуждению вопросов производительности.
Архитектура Shore
В Shore имеется несколько компонентов, которые не описываются в данной статье, поскольку не являются для нее существенными. В их число входят управление дисковыми томами (авторы статьи загружают всю базу данных в основную память), восстановление (авторы не рассматривают ситуации аварийных отказов приложений), распределенные транзакции и методы доступа, отличные от B-деревьев (такие как R-деревья). Примерная организация оставшихся компонентов показана на рис. 2.

Рис. 2. Основные компоненты Shore (подробное описание см. в тексте)
Shore предоставляется пользователям в виде некоторой библиотеки. Пользовательский код (в данном случае – реализация тестового набора TPC-C) компонуется с этой библиотекой, и в нем должна использоваться библиотека потоков управления, которая используется и в Shore. Каждая транзакция выполняется в некотором потоке Shore, имея доступ как к локальным переменным пользовательского пространства, так и к поддерживаемым Shore структурам данных и методам. К OLTP имеют отношения методы, требуемые для создания и заполнения файла базы данных, загрузки его в буферный пул, начала, фиксации или аварийного завершения транзакции, выполнения операций уровня записи, таких как выборка, модификация, создание и удаление, а также связанных с ними операций над первичными и вторичными индексами в виде B-деревьев.
Внутри тела транзакции (ограниченного операторами начала и фиксации) прикладной программист использует методы Shore для доступа к структурам хранения – файлам и индексам, а также к каталогам для их поиска. Во всех структурах данных для хранения информации используются слоттированные страницы (slotted page). Методы Shore выполняются под управлением менеджера транзакций, который тесно взаимодействует со всеми другими компонентами. При доступе к структурам хранения производятся вызовы менеджера журнала, менеджера блокировок и менеджера буферного пула. Эти вызовы всегда проходят через уровень управления параллелизмом, который отслеживает попытки совместного и монопольного доступа к различным ресурсам.
Этот уровень не является отдельным модулем; во всем коде все виды доступа к общим ресурсам производятся с синхронизацией на основе защелок. Защелки похожи на блокировки (в том, что они могут быть совместными и монопольными), но они являются легковесными и не сопровождаются механизмом обнаружения синхронизационных тупиков. Прикладной программист должен гарантировать, что синхронизация на основе защелок не приведет к тупику.
Далее авторы обсуждают архитектуру потока управления и приводят подробности блокировок, журнализации и управления пулом буферов.
Поддержка потоков управления. В Shore обеспечивается собственный пакет поддержки невытесняемых потоков управления на пользовательском уровне. Этот пакет был получен на основе пакета NewThreads (первоначально разрабатывавшегося в Университете Вашингтона). В пакете поддержки нитей Shore поддерживается API стандарта POSIX. Этот выбор пакета поддержки потоков управления повлиял на разработку кода и поведение Shore. Поскольку потоки поддерживаются на пользовательском уровне, приложение выполняется в рамках некоторого процесса, объединяющего все нити Shore. Блокировки этого процесса по причине ввода-вывода избегаются путем порождения отдельных процессов, ответственных за устройства ввода-вывода (все процессы общаются через разделяемую память). Тем не менее, приложения не могут напрямую пользоваться преимуществами многоядерных (или SMP) систем, если не входят в распределенные приложения. Однако последний вариант привел бы к избыточным накладным расходам для многоядерного центрального процессора в тех случаях, когда достаточно было бы использовать простой многопотоковый режим на системном уровне.
Поэтому при получении результатов, описываемых в этой статье, использовался однопотоковый режим. В системе, использующей многопотоковый режим работы, требовалось бы большее число команд и циклов процессора на выполнение каждой транзакции (поскольку в дополнение к коду транзакции нужно было бы выполнять еще и код, поддерживающий поток управления).
Поскольку основной целью данной статьи является анализ числа команд процессора, потребляемого разными компонентами системы баз данных, отсутствие полной многопотоковой реализации Shore влияет только на общее число команд, выполняемых в исходном варианте системы до начала удаления из нее избыточных компонентов.
Блокировки и журнализация. В Shore реализована стандартная двухфазная схема блокировок для поддержки транзакций со стандартными свойствами ACID. Поддерживаются иерархические блокировки, эскалация которых (record, page, store, volume) по умолчанию выполняется менеджером блокировок. Для каждой транзакции поддерживается список удерживаемых ею блокировок, так что блокировки можно журнализовать при входе транзакции в состояние подготовки и освобождать в конце транзакции. В Shore также реализуется упреждающая запись в журнал (write ahead logging, WAL), для чего требуется тесное взаимодействие между менеджерами журнала и буферов. До выталкивания страницы из буферного пула должна быть вытолкнута соответствующая журнальная запись. Для этого требуется тесное взаимодействие между менеджерами транзакций и журнала. Все три мененджера понимают смысл последовательных номеров журнальных записей (log sequence numbers, LSN), которые служат для идентификации и обнаружения записей в журнале, расстановки в страницах временных меток, определения последней модификации, выполненной данной транзакцией, и нахождения последней журнальной записи, записанной транзакцией. С каждой страницей связывается LSN последней модификации, воздействовавшей на эту страницу. Страница не может быть записана на диск, пока журнальная запись с LSN, ассоциированным с этой страницей, не попадет в стабильную память.
Менеджер буферов. С помощью менеджера буферов все остальные модули (за исключением менеджера журнала) читают и записывают страницы. Страница читается путем вызова метода fix менеджера буферов. Если база данных целиком размещается в основной памяти, любая страница всегда будет располагаться в буферном пуле (в противном случае, если запрашиваемая страница не содержится в буферном пуле, соответствующий поток покидает процессор и ожидает, пока процесс, ответственный за ввод-вывод не поместит эту страницу в буферный пул).
Метод fix обновляет отображение между идентификаторами страниц и буферными фреймами и статистическую информацию буферного пула. Для обеспечения согласованности имеется защелка, регулирующая доступ к методу fix. При чтении записи (после того, как ее идентификатор найден путем поиска в индексе) происходит следующее:
эта запись блокируется (как и содержащая ее страница, посредством иерархической блокировки); страница фиксируется в буферном пуле; вычисляется смещение от начала этой страницы до начала записи.
Чтение записи выполняется путем вызова методов pin/unpin. Модификация записей выполняется посредством копирования части записи или записи целиком из буферного пула в пользовательское адресное пространство, выполнения там требуемой модификации и передачи новых данных менеджеру хранения данных.
Подробности архитектуры Shore можно найти на Web-сайте проекта. В следующем подразделе описываются дополнительные механизмы и возможности системы; в этом же подразделе обсуждаются модификации системы, произведенные авторами статьи.
Shore
СУБД Shore (Scalable Heterogeneous Object Repository) разрабатывалась в Висконсинском университете в начале 1990-х гг. как типизированная система персистентных объектов, заимствовавшая черты технологий файловых систем и объектно-ориентированных баз данных [CDF+94]. Система обладала многоуровневой архитектурой, которая позволяла пользователям выбрать соответствующий уровень поддержки их приложений. Эти уровни (система типов, совместимость с UNIX, языковая неоднородность) обеспечивались поверх менеджера хранения данных Shore (Shore Storage Manager, SSM). В SSM поддерживались средства, типичные для всех современных СУБД: полное управление параллелизмом и восстановлением (свойства транзакций ACID) c применением двухфазных блокировок и журнализации с упреждающей записью в журнал, а также надежная реализация B-деревьев. Основные архитектурные решения основывались на идеях, описанных в основополагающей книге Грея и Рейтера про обработку транзакций [GR93], а также на использовании многочисленных алгоритмов, заимствованных из статей про ARIES [MHL+92, Moh89, ML89].
Поддержка проекта завершилась в конце 1990-х гг., но она продолжалась в отношении SSM; в 2007 г. вышла версия SSM 5.0 для использования в среде Linux на процессорах Intel x86. В этой статье под названием Shore понимается именно SSM. Информация по поводу Shore и исходные коды системы доступны на сайте проекта. В оставшейся части этого раздела обсуждаются ключевые компоненты Shore, структура кода системы, характеристики Shore, влияющие на сквозную производительность системы, а также набор модификаций системы, произведенных авторами данной статьи, и воздействие этих модификаций на код системы.
Исследование производительности
Этот раздел организован следующим образом. Сначала авторы описывают свой вариант тестового набора TPC-C (подраздел 4.1). В подразделе 4.2 приводятся детали аппаратной платформы – экспериментальной установки, а также описываются инструментальные средства, которые использовались для сбора данных о производительности. В подразделе 4.3 представлена серия результатов, уточняющих повышение производительности Shore по мере применения оптимизаций и удаления компонентов.
Экспериментальная установка и методология измерений
Все эксперименты выполнялись на одноядерном процессоре Pentium 4 3.2GHz с кэшем L2 емкостью 1 мегабайт, отключенным гипертредингом, основной памятью в 1 гигабайт. Система работала под управлением Linux 2.6. Для компиляции использовался компилятор gcc версии 3.4.4 с оптимизацией уровня O2. Для отслеживания активности дисков и проверки того, что во время экспериментов с базами данных не генерировался дисковый трафик, использовалась стандартная утилита Linux iostat. Во всех экспериментах база данных целиком предварительно загружалась в основную память. Затем пропускалось большое количество транзакций (40000). Пропускная способность измерялась напрямую делением прошедшего времени на число завершенных транзакций.
Для детального подсчета числа команд и циклов процессора в код тестового приложения были встроены вызовы библиотеки PAPI [MBD+99], которая обеспечивает доступ к измерителям производительности центрального процессора. Поскольку вызов PAPI производится после каждого вызова Shore, авторы должны были компенсировать расходы на вызовы PAPI в своих итоговых результатах. На используемой машине на эти вызовы расходовалось 535-537 команд и 1350-1500 циклов процессора. Авторы измеряли расходы на вызовы Shore для всех 40000 транзакций и вычисляли средние значения показателей.
Большинство диаграмм, представленных в этой статье, основывается на измерениях числа команд процессора (полученных с использованием измерителей производительности ЦП), а не на астрономическом времени. Причиной является то, что показатели числа команд отображают длину выполняемых участков кода, и они детерминированы. Конечно, одно и то же число выполненных команд в разных компонентах может привести к разным астрономическим временам выполнения (числу циклов процессора) из-за разного поведения на уровне микроархитектуры процессора (отсутствие данных в кэше, отсутствие требуемых элементов в буфере быстрого преобразования адресов (translation lookaside buffer, TLB) и т.д.). В п. 4.3.4 сравниваются показатели числа команд и числа циклов процессора и демонстрируются компоненты, для которых обеспечивается высокая эффективность на микроархитектурном уровне за счет редкого отсутствия данных в кэше L2 и хорошего распараллеливания на уровне команд.
Однако на число циклов влияют различные параметры, начиная от характеристик процессора, таких как размер/ассоциативность кэша, качество предсказания переходов, особенности функционирования TLB, и заканчивая переменными времени исполнения, такими как параллельно выполняемые процессы. Поэтому число циклов следует воспринимать, как относительный временной показатель. В этой статье авторы не углубляются в проблематику эффективности кэшей процессоров, поскольку основной задачей является идентификация набора компонентов СУБД, удаление которых может привести к увеличению на два десятичных порядка производительности некоторых видов рабочих нагрузок OLTP. Более подробную информацию о микроархитектурном поведении систем баз данных можно найти, например, в [Ail04]. В следующем подразделе авторы переходят к описанию полученных ими результатов.
Экспериментальные результаты
Во всех экспериментах основная платформа Shore представляла собой систему баз данных, полностью сохраняемых в основной памяти, без каких-либо выталкиваний данных на диск (обмены с дисковой памятью могли инициироваться только менеджером журнала). Имелся только один поток управления, в котором транзакции выполнялись по одной. Маскирование ввода-вывода (в случае журнализации на диске) не являлось проблемой, поскольку этот ввод-вывод влиял только на общее время отклика и не увеличивал число команд и циклов, реально затрачиваемых на выполнение транзакций.
В Shore было вставлено 11 различных разновидностей изменений, позволявших авторам устранить функциональные возможности (или произвести оптимизацию). При представлении экспериментальных результатов эти разновидности объединены в шесть компонентов. Список 11-ти разновидностей изменений (и соответствующих компонентов) и порядок их применения показан на рис. 7. Более подробно эти модификации были описаны в подразделе 3.2. Последнее изменение состоит в полном отказе от использования Shore и запуске разработанного авторами ядра с минимальными накладными расходами, которое в этой статье называется «оптимальным». По сути, это ядро представляет собой построенный вручную пакет для работы с B-деревьями в основной памяти без какой-либо поддержки транзакций или обработки запросов.
Команды по сравнению с тактами
Имея детальный анализ числа выполняемых команд в транзакциях Payment и New Order, авторы теперь сравнивают долю астрономического времени (число тактов процессора), затраченного на выполнение каждой фазы транзакции New Order, с долей числа команд, выполненных на каждой фазе. Результаты демонстрируются на рис. 8. Как уже отмечалось, авторы не ожидали, что эти доли будут идентичны, поскольку в кэше могут отсутствовать требуемые данные, конвейер команд может тормозиться (обычно из-за условных переходов), и для выполнения некоторых команд может потребоваться больше тактов, чем для других команд.
Например, оптимизации B-дерева в меньшей степени сокращают число тактов, чем число выполняемых команд, поскольку устраняемые накладные расходы в основном касаются вычисления смещений, при которых данные обычно содержатся в кэше. И наоборот, в оставшемся после всех оптимизаций ядре используется намного больше тактов, чем команд, поскольку в нем много переходов, происходящих, в основном, от вызовов функций. Аналогично, значительно больше тактов используется в компоненте журнализации, поскольку он работает с разными адресами при создании и записи журнальных записей (время обмена с диском не включается ни в одну из диаграмм). Наконец, компоненты управления блокировками и буферами потребляют примерно такую же долю тактов, что и команд.

Рис. 8. Команды (слева) и такты (справа) для транзакции New Order
New Order
Аналогичный анализ числа команд, затрачиваемых при выполнении транзакции New Order, показан на рис. 6. На рис. 7 показан детальный расчет влияния всех одиннадцати выполненных модификаций и оптимизаций. В этой транзакции используется примерно в 10 раз больше команд, чем в транзакции Payment, для выполнения 13 вставок в B-дерево, 12 операций создания записи, 11 операций модификации, 23 операций pin/unpin и 23 поисков в B-дереве. Основное отличие между New Order и Payment по влиянию оптимизаций на сокращение числа выполняемых команд в разных компонентах относится к коду сравнения ключей B-дерева, журнализации и блокировкам. Поскольку в New Order к смеси операций добавляются вставки в B-дерево, относительно более выигрышной оказывается оптимизация сравнения ключей (около 16%). Удаление журнализации и блокировок теперь приводит к сокращению общего числа выполняемых команд только на 12 и 16% соответственно. В основном, это связано с тем, что в этом случае значительно меньшее время занимает выполнение операций, для которых требуется большая работа по журнализации и управлению блокировками.

Рис. 6. Детальный анализ числа команд для транзакции New Order
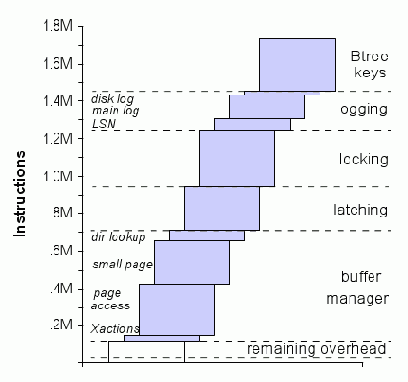
Рис. 7. Расширенный анализ для транзакции New Order (пояснения по поводу надписей в левой колонке см. в подразделе 3.2)
Оптимизации менеджера буферов и здесь обеспечивают наиболее существенный выигрыш, снова по той причине, что удается избежать высоких накладных расходов на создание записи. Показатели для оптимизации менеджера буферов, представленные на рис. 7, демонстрируют нечто поразительное: увеличение размера страницы с 8 килобайт до 32 килобайт (см. блок «small page») обеспечивает сокращение общего числа выполняемых команд на 14%. Эта простая оптимизация (служащая для сокращения частоты выделения страниц и уменьшения глубины B-дерева) дает значительный выигрыш.
Payment
На рис. 5 (слева) показано уменьшение числа команд, затрачиваемых на выполнение транзакции Payment, за счет оптимизации сравнения ключей B-дерева и удаления функциональности журнализации, блокировок, защелок и менеджера буферов. В правой части рисунка для каждого действия по оптимизации или удалению компонентов показано его воздействие на число команд, затрачиваемых на разные части выполняемой транзакции. Для транзакции Payment эти части включают вызов метода начала транзакции, три поиска в B-дереве, три соответствующих операции pin/unpin, три операции модификации (через B-дерево), одно создание записи и вызов метода фиксации транзакции. Высота каждого прямоугольника соответствует общему числу выполненных команд. Самый правый прямоугольник показывает производительность ядра с минимальными накладными расходами.

Рис. 5. Детальный анализ числа команд для транзакции Payment
По имеющейся у авторов информации, выполненная ими оптимизация сравнения ключей B-дерева является стандартной практикой в высокопроизводительных архитектурах СУБД, и для Shore эта оптимизация была произведена первой, поскольку ее следует делать в любой системе.
Удаление журнализации влияет, главным образом, на операции фиксации транзакций и модификации, поскольку именно в их коде генерируются журнальные записи; в меньшей степени это действие затрагивает поиск в B-деревьях и каталогах. Произведенные модификации позволили сократить общее число команд на 18%.
На поддержку блокировок тратится около 25% от общего числа команд. Удаление блокировок влияет на весь код, но в особенности на операции pin/unpin, поиска в B-деревьях и каталогах, а также фиксации транзакций, т.е. на операции, устанавливающие и освобождающие блокировки (транзакция всегда имеет требуемые блокировки модифицируемых записей к моменту выполнения операций модификации).
Механизм защелок занимает примерно 13% от общего числа команд, и он, прежде всего, затрагивает части транзакций, создающие запись и производящие поиск в B-дереве.
Это связано с тем, что буферный пул (используемый при создании записи) и B-деревья являются основными общими структурами данных, при доступе к которым должна производиться синхронизация.
Наконец, модификации, относящиеся к буферному пулу, позволили сократить общее число команд еще на 30%. Как говорилось ранее, после выполнения этих модификаций память под новые записи получается непосредственно вызовом функции malloc, и в большинстве случаев поиск страниц не проходит через буферный пул. Это делает операцию создания новой записи очень дешевой, а также существенно улучшает производительность других компонентов, часто осуществляющих поиск.
К этому моменту в оставшемся ядре выполняется 5% от исходного числа команд (что дает двадцатикратный выигрыш в производительности), что в шесть раз превышает число выполняемых команд в «оптимальной» системе. Этот анализ приводит к двум наблюдениям. Во-первых, существенны все шесть основных компонентов, для каждого требуется выполнение не менее 18 тысяч команд из исходных 180 тысяч. Во-вторых, до применения всех оптимизаций сокращение числа выполняемых команд не является слишком существенным: до последнего шага по удалению менеджера буферов в оставшихся компонентах выполняется примерно треть от исходного числа команд (а после удаления менеджера буферов достигается 20-кратное повышение пропускной способности).
Рабочая нагрузка OLPTP
Тестовый набор, используемый авторами, происходит от TPC-C [TPCC], в котором моделируется оптовый поставщик запасных частей, работающий с несколькими складами и связанными с ними торговыми участками. Тестовый набор TPC-C разработан для представления любой прикладной области, в которой требуется регулировать, продавать или распространять некоторые продукты или услуги. В нем учитывается потребность в масштабировании, когда поставщик расширяет свой бизнес и создаются новые склады. С каждого склада продукция должна поставляться в 10 торговых участков, и каждый торговый участок должен обслуживать 3000 заказчиков. Схема базы данных, в которой учитываются требования масштабирования (число складов W является параметром), показана на рис. 3. Размер базы данных для одного склада составляет около 100 мегабайт (авторы экспериментировали с пятью складами, т.е. с базой данных общим размером в 500 мегабайт).

Рис. 3. Схема TPC-C
TPC-C включает смесь из пяти параллельных транзакций разных типов и сложности. В их число входят транзакции регистрации заказов (New Order), учета платежей (Payment), доставки заказов, проверки состояния заказов и отслеживания уровня запасов на складах. В TPC-C также специфицируется, что около 90% времени выполняются первые две транзакции. Для лучшего понимания эффекта своих оптимизаций и модификаций авторы экспериментировали со смесью только первых двух транзакций. Структура их кода (вызовов Shore) показана на рис. 4. Для достижения повторяемости экспериментов в исходные спецификации внесены следующие небольшие изменения.

Рис. 4. Вызовы методов Shore в транзакциях New Order и Payment
New Order. Каждая транзакция New Order размещает заказ из 5-15 пунктов, и 90% заказов полностью удовлетворяется за счет запасов «соседнего» склада заказчика (для 10% заказов требуется доступ к запасам удаленного склада). Чтобы избежать изменчивости результатов авторы установили число пунктов заказа в 10 и всегда обслуживают заказы из локального склада. Эти два изменения не влияют на пропускную способность. Код на рис. 4 демонстрирует двухфазную оптимизацию, упоминавшуюся в подразделе 2.5, которая позволяет избежать аварийного завершения транзакции. Сначала читаются все пункты заказа, и если среди них обнаруживается что-то недопустимое, то приложение аварийно завершается без потребности в откате базы данных.
Payment. Это легковесная транзакция. Она обновляет баланс заказчика и поля «склад/торговый участок», а также генерирует запись истории. Здесь снова имеется выбор между соседним и удаленным складами, и авторы всегда выбирают соседний склад. Еще одна возможность случайного выбора состоит в том, ищется ли заказчик по имени, или же по идентификатору, и авторы всегда используют идентификаторы.
Воздействие на пропускную способность
После всех удалений компонентов и оптимизаций в полученном варианте Shore остался код, при выполнении которого процессор занимается полностью, поскольку отсутствует какой-либо ввод-вывод. Среднее время выполнения транзакции составляет 80 микросекунд (для смеси 50/50 транзакций New Order и Payment); выполняется около 12700 транзакций в секунду.
Для сравнения, полезная работа в оптимальной системе занимала около 22 микросекунд на одну транзакцию, что позволяло выполнять около 46500 транзакций в секунду. Основными причинами этого различия является более глубокий стек вызовов в ядре, разработанном авторами, и невозможность устранения некоторых остаточных явлений управления транзакциями и вызовов буферного пула без разрушения Shore. В качестве точки отсчета бралась стандартная версия Shore с разрешенной журнализацией, но базой данной, целиком кэшированной в основной памяти. Эта система обеспечивала выполнение примерно 640 транзакций в секунду (1.6 миллисекунд на транзакцию). Вариант Shore с базой данных в основной памяти без выталкивания буфера журнала позволил добиться пропускной способности в 1700 транзакций в секунду (около 588 микросекунд на транзакцию). Тем самым, модификации, произведенные авторами, позволили увеличить общую пропускную способность в 20 раз.
Представив эти базовые измерения пропускной способности, авторы переходят к детальному анализу числа команд, затраченных системой на выполнение двух транзакций из тестового набора. В анализе числа команд и циклов процессора, представленном в следующих пунктах, не учитывается какое-либо влияние дисковых операций, хотя в показателях для исходного варианта Shore некоторые операции записи в журнал учитывались.
B-деревья с учетом знаний о поведении кэша
В своих исследованиях авторы не преобразовывали B-деревья Shore в формат, в котором учитывались бы знания о поведении кэша («cache-conscious») [RR99, RR00]. Такая перестройка, по крайней мере, в системе без других оптимизаций, представленных в этой статье, оказала бы только умеренное влияние на производительность. В работах, посвященных этой разновидности B-деревьев, исследуются проблемы отсутствия в кэше данных, требуемых при доступе к значениям ключей, которые хранятся в узлах B-дерева. Оптимизации авторов статей позволяют сократить на 80-88% время выполнения операций над B-деревьями без изменения паттернов доступа к ключам. При переходе от максимально оптимизированной Shore к ядру с минимальными накладными расходами – в котором производится доступ к тем же данным – оставшееся время сокращается еще на две трети. Другими словами, авторы полагают, что более важно оптимизировать другие компоненты, такие как управление параллелизмом и восстановление, чем оптимизировать структуры данных. Однако после минимизации системы до очень простого ядра новым узким местом может стать именно отсутствие данных в кэше при выполнении операций над B-деревом. В действительности, может оказаться, что в этой новой среде лучшую производительность смогут обеспечить другие индексные структуры, такие как хэш-таблицы. Опять же, эту гипотезу требуется тщательно проверить.
Благодарности
Авторы благодарны рецензентам SIGMOD за их полезные замечания. Это исследование частично поддерживалось грантами Национального научного фонда (National Science Foundation) 0704424 и 0325525.
Оценка повторяемости результатов
Все результаты, описанные в этой статье, были проверены комитетом SIGMOD по повторяемости. Код и данные, использованные в статье, доступны на сайте sigmod.org .
Поддержка многоядерных процессоров
Возрастающая распространенность многоядерных компьютеров приводит к интересному вопросу: что будут делать с несколькими ядрами будущие серверы баз данных OLTP? Один вариант состоит в параллельном выполнении нескольких транзакций на разных ядрах в одном узле (как это делается сегодня); конечно, такой параллелизм требует использования защелок и приводит к потребности решения многих проблем распределения ресурсов. Эксперименты авторов показывают, что хотя накладные расходы механизма защелок не особенно велики (10% от общего числа циклов процессора в основной транзакции New Order), они остаются препятствием для достижения существенного повышения производительности систем баз данных OLTP. Когда технологии (такие, как транзакционная память [HM93]) эффективного выполнения высоко параллельных программ на многоядерных машинах достигнут зрелости и начнут применяться в продуктах, будет очень интересно проанализировать новые реализации защелок и заново оценить накладные расходы многопотокового режима в системах баз данных OLTP.
Второй вариант основан на использовании виртуализации на уровне операционной системы или СУБД, чтобы каждое ядро представлялось как однопотоковая машина. Неясно, какие последствия будет иметь этот подход для производительности, но он является основанием для тщательного исследования такой виртуализации. Третий вариант, дополнительный по отношению к первым двум, состоит в том, чтобы попытаться использовать внутризапросный параллелизм, который может быть оправдан, даже если в системе транзакции выполняются по очереди. Однако объем внутризапросного параллелизма, доступного в типичной транзакции OLTP, вероятно, ограничен.
Родственные исследования
Проводилось несколько исследований узких мест производительности современных систем баз данных. Работы [BMK99] и [ADH+99] показывают, что возрастание объемов доступной основной памяти мало способствует повышению производительности систем баз данных. В [MSA+04] анализируются узкие места, возникающие из-за конкуренции за различные ресурсы (такие как блокировки, синхронизация ввода-вывода или центральный процессор), с точки зрения клиента (что включает воспринимаемые задержки из-за операций ввода-вывода или вытесняющее планирование других параллельно обрабатываемых запросов). В отличие от исследования, представленного в данной статье, авторы упомянутых статей анализируют полные системы баз данных, и не обсуждают их покомпонентную производительность. Исследования на основе тестовых наборов, такие как TPC-B [Ano85] области OLTP или Wisconsin Benchmark [BDT83] в области общей обработки SQL-запросов, также характеризуют производительность полных СУБД, а не их отдельных компонентов.
Кроме того, имеется большое число публикаций, посвященных системам баз данных в основной памяти. В исследованиях индексных структур в основной памяти анализировались AVL trees [AHU74] и T-trees [LC86]. Другие методы применения основной памяти описаны в [BHT87]. К числу полных систем баз данных в основной памяти относятся TimesTen [Tim07], DataBlitz [BBK+98] и MARS [Eic87]. Обзор этой области содержится в [GS92]. Однако ни в одной из этих работ не предпринимались попытки изолировать компоненты накладных расходов, что является основным вкладом данной статьи.
Слабая согласованность
В большинстве крупных Web-ориентированных магазинов для достижения высокой доступности и обеспечения восстановления после аварийных отказов используется репликация баз данных OLTP, обычно в глобальной сетевой среде. Однако, похоже, что никто не собирается платить за транзакционную согласованность в глобальной сети. Как отмечалось в разд. 2, распространенным рефреном в Web-приложениях является «конечная согласованность» [Bre00, DHJ+07]. Обычно сторонники такого подхода выступают за разрешение несогласованности не техническими средствами; например, дешевле предоставить кредит недовольному клиенту, чем поддерживать стопроцентную согласованность. Другими словами, реплики, в конечном счете, становятся согласованными, по-видимому, тогда, когда система переводится в пассивное состояние.
Должно быть понятно, что конечная согласованность невозможна без обеспечения транзакционной согласованности над общей рабочей нагрузкой. Например, предположим, что транзакция 1 фиксируется в узле 1 и аварийно завершается или теряется в узле 2. Транзакция 2 читает результаты транзакции 1 и пишет результаты в базу данных, что приводит к распространению несогласованности и загрязнению системы. При этом, очевидно, должны существовать рабочие нагрузки, для которых конечная согласованность достижима, и было бы интересно попытаться найти такие рабочие нагрузки. Однако, как отмечалось выше, результаты авторов показывают, что удаление поддержки транзакций – блокировок и защелок – из систем баз данных в основной памяти приводит к резкому повышению производительности.
Следствия для будущих серверов баз данных OLTP
На основе результатов, описанных в предыдущем разделе, авторы снова обращаются к обсуждению будущего систем баз данных OLTP, начатому в разд. 2. Прежде чем перейти к детальному рассмотрению следствий полученных результатов для разработки различных подсистем СУБД, авторы приводят два общих наблюдения, вытекающих из полученных численных показателей.
Во-первых, отказ от любого одного компонента системы оказывает относительно небольшое воздействие на общее повышение производительности. Например, оптимизации, относящиеся к поддержке баз данных в основной памяти, позволили повысить производительность Shore примерно на 30%, что является существенным показателем, но, вероятно, не сможет склонить поставщиков систем баз данных к реинженирингу своих систем. Аналогичный выигрыш можно было бы получить путем устранения всего лишь защелок или перехода в однопотоковому режиму с выполнением рабочей нагрузки по одной транзакции.
Наиболее существенный выигрыш достигается при применении нескольких оптимизаций. Полностью разгруженная система обеспечивает двадцатикратный выигрыш в производительности над исходным вариантом Shore, и это действительно очень существенно. Следует заметить, что такая система может по-прежнему поддерживать транзакционную семантику, если транзакции выполняются по одной, и восстановление путем копирования состояния из других узлов сети. Однако такая система очень и очень отличается от любой системы, предлагаемой поставщиками в настоящее время.
Управление параллелизмом
Эксперименты авторов показывают значительный вклад в общие накладные расходы динамических блокировок. Это означает, что большой выигрыш может принести выявление сценариев, таких как коммутативность приложений или поочередная обработка транзакций, для которых позволительно отключить управление параллелизмом. Однако имеется много приложений баз данных, которые недостаточно хорошо соблюдают подобные приличия или не могут работать в режиме выполнения транзакций по одной. В таких случаях интересным вопросом является то, какой из протоколов управления параллелизмом является наилучшим? Двадцать лет назад разные исследователи [KR81, ACL87] выполнили всестороннее имитационное моделирование, которое ясно показало превосходство динамических блокировок над другими методами управления параллелизмом. Однако в этих исследованиях предполагалось хранение баз данных на дисках и наличие соответствующих простоев транзакций в ожидании завершения ввода-вывода, и это, очевидно, существенно влияло на результаты. Было бы крайне желательно заново произвести такие модельные исследования, имея в виду рабочую нагрузку с базами данных в основной памяти. Авторы серьезно подозревают, что превалирующим вариантом будет некоторая разновидность оптимистического управления параллелизмом.
Управление репликацией
В традиционных системах баз данных принято поддерживать репликацию на основе схемы «активный-пассивный» путем пересылки журнальной информации. У каждого объекта имеется «активная» первичная копия, к которой, в первую очередь, направляются все изменения. Затем журнал изменений передается по сети в один или несколько «пассивных» резервных узлов. После этого в удаленных базах данных по журналу воспроизводятся изменения, выполненные в первичном узле.
У этой схемы имеется несколько недостатков. Во-первых, если не используется какая-либо разновидность двухфазной фиксации транзакций, то удаленные копии не являются транзакционно согласованными с первичной копией. Следовательно, если чтения должны быть транзакционно согласованными, то они не могут производиться над репликами. Если операции чтения направляются к репликам, то нельзя ничего сказать о точности ответов. Второй недостаток состоит в том то, что обработка отказа не является мгновенной. Следовательно, простои из-за сбоев являются более длительными, чем могли бы быть. В третьих, для поддержания реплик требуется журнал, а эксперименты авторов показывают, что на поддержку журнала уходит около 20% общего числа тактов процессора. Поэтому авторы полагают, что интересно было бы исследовать альтернативы репликации «активный-пассивный», такие как подход «активный-активный».
Основной причиной того, что в прошлом использовалась репликация «активный-пассивный» с пересылкой журнала, является то, что воспроизведение изменений по журналу обходится гораздо дешевле выполнения над репликой логики транзакции. Однако в системе баз данных в основной памяти время выполнения транзакции обычно составляет менее одной миллисекунды, что, вероятно, не намного превышает время, требуемое для воспроизведения изменений по журналу. В этом случае альтернативная архитектура «активный-активный» кажется вполне осмысленной. При этом подходе все реплики являются «активными», и транзакция выполняется синхронно надо всеми репликами. Преимуществом этого подхода является почти мгновенная обработка отказов, и отсутствует требование направления изменений сначала в узел с первичной копией. Конечно, в таком сценарии существенную дополнительную задержку будет порождать двухфазная фиксация, из чего следует потребность в технологии, избегающей использования двухфазной фиксации – возможно, путем выполнения транзакций в порядке временных меток.
Авторы выполнили исследование производительности системы
Авторы выполнили исследование производительности системы Shore для того, чтобы понять, на что тратится время в современных системах баз данных, и попытаться разобраться в том, какой могла бы быть потенциальная производительность нескольких недавно предложенных альтернативных архитектур систем баз данных. Путем удаления компонентов из Shore авторам удалось создать систему, на которой модифицированный тестовый набор TPC-C выполняется почти в 20 раз быстрее, чем на исходной системе (хотя и с существенным сокращением функциональных возможностей!).
Авторы обнаружили, что управление буферами и операции над блокировками вносят наиболее значительный вклад в системные накладные расходы, но также существенными являются журнализация и операции над защелками. На основе этих результатов авторы сделали несколько интересных наблюдений.
Во-первых, без удаления всех этих компонентов производительность системы баз данных, оптимизированной для хранения всей базы данных в основной памяти, вряд ли будет намного превосходить производительность традиционной системы баз данных, если вся база данных помещается в основной памяти. Во-вторых, если создать полностью разгруженную систему – например, систему, работающую в однопотоковом режиме, обеспечивающую восстановление путем копирования состояния из других узлов сети, размещающую все данные в основной памяти и поддерживающую ограниченные функциональные возможности транзакций, – то можно добиться производительности, на порядки превосходящей производительность исходной системы.
Это говорит о том, что недавние предложения по поводу создания систем баз данных с ограниченными функциональными возможностями [WSA97, SMA+07] могут привести к достаточно интересным результатам.
